偶尔我们需要这样做。
在一台主机上如果复制多个主库,可以很简单:在备库主机上启动多个MySQL实例(mysqld_muilt),每个实例使用一个端口,复制多台主库就可以了。但是如果希望复制过来的数据都在同一个实例中,事情就复杂了。
1. 问题以及开源社区的尝试
需求:多个主库都复制到一个备库,复制过来的数据都在一个实例中,这样实现对应用层的透明。目前,MySQL本身不提供这样的功能(考虑过,但一直未实现)。
1.1 开源社区也有很多方案和想法,例如Tungsten replicator:可以支持异构数据复制,JAVA实现,数据量较大时,性能较差,而且MySQL版本更新较快,而该软件支持较慢;
1.2 再如P.Linux的尝试:通过拉取多个主库上的Binlog在单个备库上应用的方式,对MySQL没有入侵,实现也较为简单。
1.3 High Performance MySQL还可以通过多级复制的方式实现:例如有主库DB1、DB2,都需要复制到S1上,则先配置D2复制D1的全部数据,然后再从S1上复制D2的全部数据就可以了。整理需要注意D2上的log-slave-update需要打开,为了减少D2的压力,DB上复制过来的表可以全部使用Blackhole引擎。
1.4 另外,还有一些欠成熟的Patch实现。
2. MySQL Federated引擎的“软链接”特性
Federated引擎可以在本地数据库中创建一个远端数据表的“软链接”。这样,访问远端数据表就如同访问本地数据表。(这里远端可以是不同主机上的不同实例)
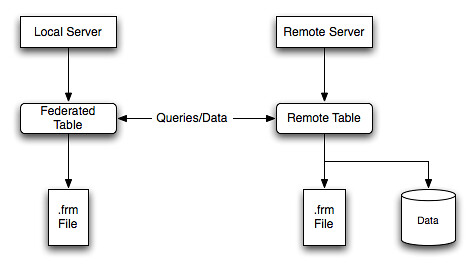
3. 使用Federated数据表实现多主一备
例如,主库DB1,DB2,都需要复制到S1上,这里DB1,DB2,S1分别在主机H1,H2,H3上。首先,在主机H3(S1所在的主机)上其另外起两个MySQL实例S2、S3,分别复制主库DB1和DB2,然后在实例S1上建立多个Federated表关联S2、S3中的数据表(相当于在S1中建立到S2、S3的软连接)。
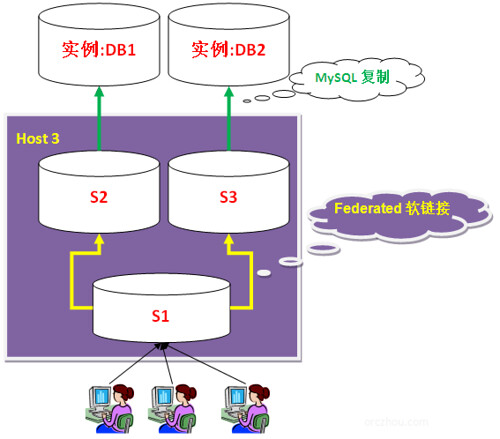
这时应用,连接到S1,就可以同时透明的访问到DB1、DB2中的实时数据表了。
4. 一些说明
4.1 上面描述的方法,也可以直接在S1上建立到DB1、DB2各个表的软连接,但是为了最大程度的减少对主库的影响,最好如上多配一层备库。
4.2 最简单的可以直接在备库上配置多个实例,让应用连接多个实例就好了,无需上面这么复制的配置。
参考文献:
1. MySQL Manual: The FEDERATED Storage Engine
2. Post of MySQL Forums : Multiple masters to single slave
3. 通过tungsten replicator实现mysql多主一从的备份架构
4. Is it possible to do N-master => 1-slave replication with MySQL
5. MySQL Multi-Master – Single-Slave – Replication