AWS re:Invent已经过去一个多月了,现在才来写这篇文章,虽然有些后知后觉,但比不知不觉应该还是要好一点。
AWS是云行业的“领导者”,re:Invent是AWS每年最重要的会议,会介绍当前和未来一段时间的新产品发布,内容也很具启发性。这篇文章,主要关注Andy Jassy的Keynote中数据库部分的内容。
开篇就怼Oracle
以前都是Larry在OOW上怼其他公司的,这次AWS怼Larry,怼得非常直白,连漫画都用上了。这也算是今年数据库领域非常有趣的一件事情了(之前OOW上,Larry怼了AWS,说上面的Oracle授权相比Oracle的云贵太多)。
Andy Jassy开篇就怼了Oracle。逻辑很清晰,Keynote中数据库部分主题叫“Freedom”也是有意安排。
Andy认为在过去二十年,数据库领域并不自由。在现场,他先引用了George Michael的歌曲“Freedom”,表达Builder(可以理解成使用云的工程师们)们对自由的诉求:
All we have to see is that i dont belong to you and you dont belong to me Freedom! Freedom! Freedom! You’ve gotta give for what you take
那数据库领域为什么说不自由呢?在数据库领域,过去20年,对很多公司来说,非常痛苦,因为他们不得不使用某些数据库,而这这个数据库厂商似乎并不太在乎他们的客户。在今年早些时候,Oracle一夜之间把运行在AWS和Microsoft环境的软件授权费用增加了一倍。在Andy的描述中,Oracle不在乎他们的客户,唯一在乎的只是财报。在这个环境下,现在大量的客户开始尽快的转移到一些开源的引擎,比如MySQL、PostgreSQL、MariaDB等等。但是,想从这些开放的引擎上获得商业数据库的性能,虽然有可能,但非常困难,需要做大量的尝试和调优等工作。Andy还放出了一个很有趣的,也将非常经典的漫画:

漫画解读:警察带着一个老奶奶来指认罪犯,警察问:“昨天晚上是谁吓到你的?”,答:“那个留着山羊胡须的!”(Larry Ellison,Oracle的创始人)。并列的其他三个人分别是:恐怖电影《Freddy vs. Jason》中的Freddy和Jason,恐怖电影《Cult of Chucky》中的Chucky。旁边两个是Oracle的数据库主机Exadata。
接着Andy说,这是为什么他们要做Amazon Aurora,它提供了商业数据库的性能,可靠性,持久性,同时也具备了开放数据库的成本。
Aurora新特性:多主/多点写入
这次发布单个地区(Region)多主的Aurora,在2018年,还将发布多地区(Region)的多主Aurora。
Aurora兼容MySQL、PostgreSQL,性能、持久性、可用性都是商用数据库级别,是AWS历史上增长最快的产品,大量客户在使用,客户最喜欢的点是高性能、高可用性。今年AWS Aurora提供的三个能力:
新的多主(Multi-mater)的Aurora数据库,同时具备了扩展读和写的能力。把主库的失败的切换时间从30s降低到100ms。Andy宣称这是第一个跨数据中心的数据库(原话是it becomes the first relational database service scaled out multiple data centers.)。即使使用Oracle RAC都是建议在一个房间、一个可用区、一个数据中心。当前发布Aurora Multi-master preview(预览版),单个region多主的Aurora,而且提到,AWS将在2018年发布多个region多主的Aurora。
Aurora Serverless版本
有很多的数据库是压力不是特别大,比如开发或者测试环境。这些数据库使用并不是很多,在不使用的时候,我们不想为这个实例付费,那么可以使用Aurora Serverless版,按需自动扩展的关系型数据库。它的四大优点:

支撑Amazon Prime Day的DynamoDB
过去几十年,关系型数据库无所不在,因为他的事务能力,基本上各个应用都是用。但是现在时代不一样了,数据越来越大,当数据量到TB级别以上的时候,关系模型很多时候并不适用,所以研发了DynamoDB。
这里Andy以Amazon Prime Day(相当于亚马逊夏季版本的黑五)为例子。在今年的七月,Prime Day的最重要的点就是DynamoDB,处理了3.34万亿次请求,高峰时间是1.29千万/每秒(有没有很熟悉,这个套路很像阿里巴巴的双十一技术嘛…)。也有很多客户是用MongoDB和Cassandra,但是到达一定体量的时候,客户都会需要像DynamoDB这样可控的数据库。
接着,Andy发布了DynamoDB Global Table。这里以Expedia为案例,他希望他的APP在北美地区和欧洲地区能够有一样的访问性能(跨地区的数据访问性能)。DynamoDB将提供跨地区(region)的能力。然后发布了一个在备份相关的特性,按需备份当天发布,2018年还将发布“到过去某个时间点的恢复”能力。
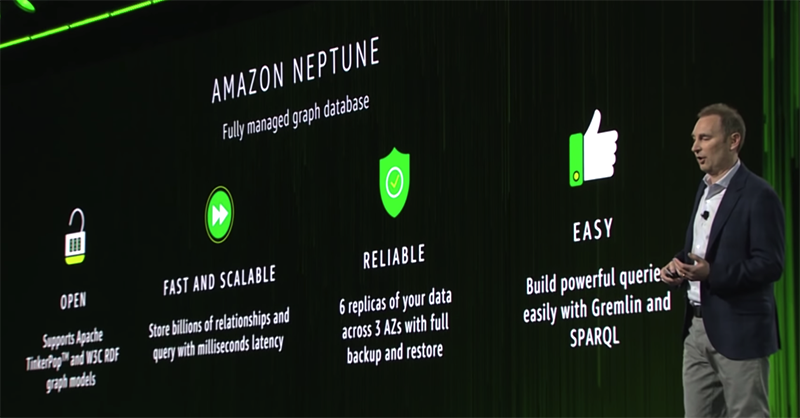
存储强关联数据的图数据库:Amazon Neptune
在数据存储上,看到有很强关联的数据需要存储和计算,这类问题有很多。这里举了三个例子:
很有很多方法可以处理这类问题,常用的有两种。很多人会用关系型数据库,但用关系模型的问题是,你需要建很多的关系(表)、外键,很快就会发现你的查询速度会非常慢,非常的不方便;也有很多人会开源的图数据库,但开源的方案的可用性、扩展性都不能满足需要,而商业方案要不是太贵,要么就是让你做出选择,你要用property graph比如Apache TinkerPop,还是用RDF model 。但是,用户更想要一个全可控、快速、可扩展、高可靠的方案。于是推出了:
Amazon Neptune : fully managed graph database
支持:property graph、TinkerPop、RDF三种模型。特性概括如下:
就这些吧。
Leave a Reply