在过去二十年中,移动互联网飞速发展,催生了大量LBS相关应用,这也让空间信息处理成为较为基础的诉求。PostgreSQL因为其起源就与空间信息处理关系很大,所以在该领域一直有着非常大的优势。MongoDB也在很早就对空间信息处理做了很强的支持,这也帮助MongoDB在发展过程中拿下来部分市场。MariaDB也在去年8月(参考)收购了厂商“CubeWerx”以增强其在地理信息的存储与分析上的能力。
在过去的十年,MySQL也在不断的增强空间信息的处理能力,本文概述了,当前MySQL在这一块的能力现状。
当前,数据库访问与处理GIS相关的信息主要参考的是:OGC Standards中的“Simple Feature Access – Part 2: SQL Option”(链接)。当前,MySQL支持的空间类型主要包括:
- 点、折线、多边形、空间(可以存储前面三种类型中的任何一种)
- 多点、多折线、多多边形、多空间(可以存储多个任何类型)
使用MySQL空间类型,则最好使用InnoDB或NDB引擎(其他还支持空间类型的引擎有MyISAM、ARCHIVE),其中InnoDB支持较为完整,对空间索引也有比较好的支持。
如果要支持地理信息,则可以使用“WGS 84系统”标准的坐标系统,正式名称是:世界大地测量系统(World Geodetic System, WGS),对应的SRID为4326。WGS是当前被广泛使用的地球空间坐标系统,例如GPS就是使用该坐标系统。该坐标系统,建立以地球的质心为中心的一套坐标系统,里面包括地球的一些基础数据等。
在MySQL可以通过如下Query可以查看MySQL中的WGS 84系统的一些基本信息:
SELECT *
FROM INFORMATION_SCHEMA.ST_SPATIAL_REFERENCE_SYSTEMS
WHERE SRS_ID = 4326\G
*************************** 1. row ***************************
SRS_NAME: WGS 84
SRS_ID: 4326
ORGANIZATION: EPSG
ORGANIZATION_COORDSYS_ID: 4326
DEFINITION: GEOGCS["WGS 84",DATUM["World Geodetic System 1984",
SPHEROID["WGS 84",6378137,298.257223563,
AUTHORITY["EPSG","7030"]],AUTHORITY["EPSG","6326"]],
PRIMEM["Greenwich",0,AUTHORITY["EPSG","8901"]],
UNIT["degree",0.017453292519943278,
AUTHORITY["EPSG","9122"]],
AXIS["Lat",NORTH],AXIS["Long",EAST],
AUTHORITY["EPSG","4326"]]
DESCRIPTION:基础对象和对应的WKT表达
MySQL或者说SQL标准中支持的对象包括如下,:Point、Linestring、Polygon、Multi Point、Multi Linestring、Multi Polygon、Geometry Collection。

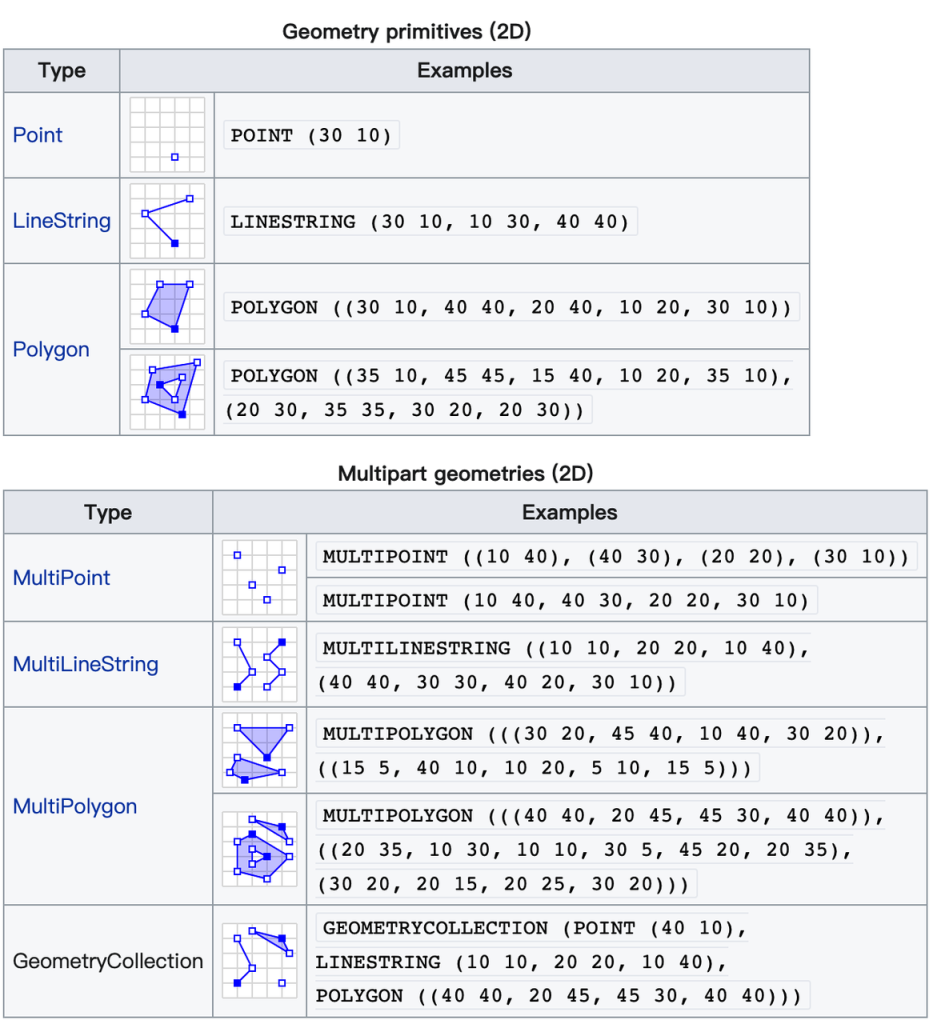
具体的:
- Point、LineSting都比较好理解
- 在WKT表达中,点的X/Y坐标,之间并没有逗号;但是,MySQL的Point函数,则是需要逗号的。
- 这里省略了一个叫“LineRing”的概念,LineRing就是一个不相交且头尾相连的LineString
- Polygon有两种,一种是普通的,一种是带hole的Polygon
- Polygon是一个Surface,不仅仅是组成边缘的点,还包含内部覆盖区域
- Polygon即便是普通的(不带hole),外部也会有一个括号
- Polygon通常是由多个LineRing组成
在这个规范下,就可以非常简单的创建OGC标准中的对象,例如:
CREATE TABLE geom (
id int,
p POINT SRID 0
);
INSERT INTO geom(id,p) values (1,Point(12,30));在实际查询中,默认的空间类型会返回二进制类型数据,所以客户端查询需要进行一次转换,将其转换容易阅读的文本类型,即标准的WKT(Well-Known Text):
转化前:
mysql> select * from geom;
+------+---------------------------+
| id | p |
+------+---------------------------+
| 1 | (@ >@ |
+------+---------------------------+
1 row in set (0.00 sec)使用了WKT函数转换后:
mysql> select id,ST_AsText(p) from geom;
+------+--------------+
| id | ST_AsText(p) |
+------+--------------+
| 1 | POINT(12 30) |
+------+--------------+好的,这是一个简单的入门介绍,更多的能力需要自己探索,祝玩得开心。
