目录
LLM 强大的语言、知识与推理能力在改变很多领域,也将持续、深入的改变更多领域。在软件领域,“Agent” 的编程模型已经是一种新的编程模式,通过这种“模式”可以将 LLM 的能力,软件提供商的领域知识,以及外部工具的能力很好的结合起来,形成“新的”软件产品。
概述
GAIA Benchmark 是 Agent 方向的一个标准测试,用于对 Agent 的通用能力进行测试,回答该 Benchmark 的问题通常需要具备一定的推理能力、Web搜索能力以及语音、图片识别,或者是这些能力的混合。这里实现一个能够解决其中60%的Level 1级别问题的 Agent 作为实践,看看 Agent 构建中的一些挑战和应对。
本文完整的代码发布并运行在 🤗 Hugging Face 上:Agent Answering Questions。
使用LangGraph构建Agent
这里选择了工具体系更加完善的 LangGraph 作为实现框架。该框架通过构建一个“图”的方式来实现流程的推进。在实际的问题解决过程中,程序按照 LLM 的推理来在不同的“Node”之间推进,从而最终找到问题的答案。解决 Gaia 的 Level 1 的问题,大部分情况,只需要通过工具调用和LLM的推理,就可以完成。所以这里使用经典的工具模型:

这里的工具包含了常见的:网页访问、搜索工具。此外,在最初实现 GAIA Benchmark 中还会涉及部分语音识别的部分,为了简化,这里做了删减。所以,基于这个程序,还可以进一步添加“语音识别”能力、“图片识别”、“实时数据获取”等功能。
构建LangGraph的“图”
首先,在开始之前,需要设计一个解决问题的上述的“图”。“图”中需要定义各个点“Nodes”;然后构建“Nodes”之间的“边”(即流转方向);最后,需要设计好“状态”(State),用于在各个“Nodes”之间传递数据(或运行状态)。
构建“节点”
“节点”通常是定义的某种功能,或者是一个自定义的函数或者工具。
这里向大模型提供了三个工具:搜索、网页访问(此外,还可以有语音转文本、图片识别等)。在这里,主节点“analysis”是问题处理的主逻辑部分,会根据工具调用结果,再次调用大模型,并获得大模型的反馈。大模型会根据这个反馈,去继续调用工具或者返回最终的结果。
####### tools and tools node #######
from z_http_request import get_http_request
from z_search import tool_google_search,search_information_from_web
from z_extract_audio import extract_audio_from_url
tools = [tool_google_search,get_http_request,extract_audio_from_url]
builder.add_node("tools", ToolNode(tools))
def analysis(state: AgentState):
...
return {"messages": [response]}
builder.add_node("analysis", analysis)构建“边”
“边”代表了节点之间的流转。例如,获得了搜索结果之后该怎么做后续处理?这里定义三条边:
builder.add_edge(START, "analysis")表示总是从“analysis”开始任务的处理。START可以理解为零号节点- 第二个“边”,则表示 “analysis” 则需要根据条件进行判断,进入哪个工具节点;或者进入END节点,即结束调用
- 第三个“边”,表示工具调用后,总会回到 “analysis” 节点
############ edges ################
builder.add_edge(START, "analysis")
builder.add_conditional_edges(
"analysis",
# If the latest message requires a tool, route to tools
# Otherwise, provide a direct response
tools_condition,
)
builder.add_edge("tools", "analysis")状态保存与流转
节点之间的运行状态与数据可以通过“AgentState”进行流转,这里的“messages”则用于保存历史消息,主要是大模型的输入与输出数据:
############# state #############
class AgentState(TypedDict):
task_id : str
question: str
file_name: str
file_url: str
messages: Annotated[list[AnyMessage], add_messages]编译并“实例化”该Agent
如下的builder.compile()则会创建并实例化该 Agent 。还可以通过函数get_graph来生成一个由mermaid表示的“图”(如果你需要打印这个图的话):
######### compile the agent ##########
zex_vs_gaia_graph = builder.compile()
######### print the graph ##########
display(Image(zex_vs_gaia_graph.get_graph(xray=True).draw_mermaid_png()))解决问题的过程分析
当构建了上述的“Agent”之后,我们看看它是如何解决一个实际的问题的。这里给出的问题是:
what is the temperature of hangzhou on 18th August 2025?Agent 给出回答是:
34°C / 25°C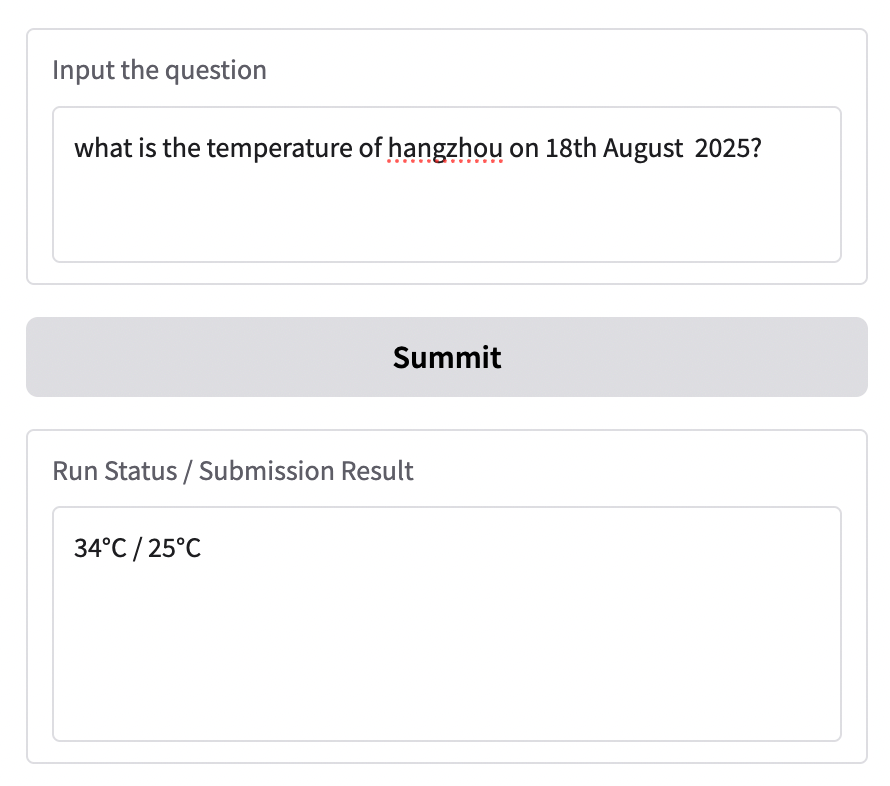
推理过程
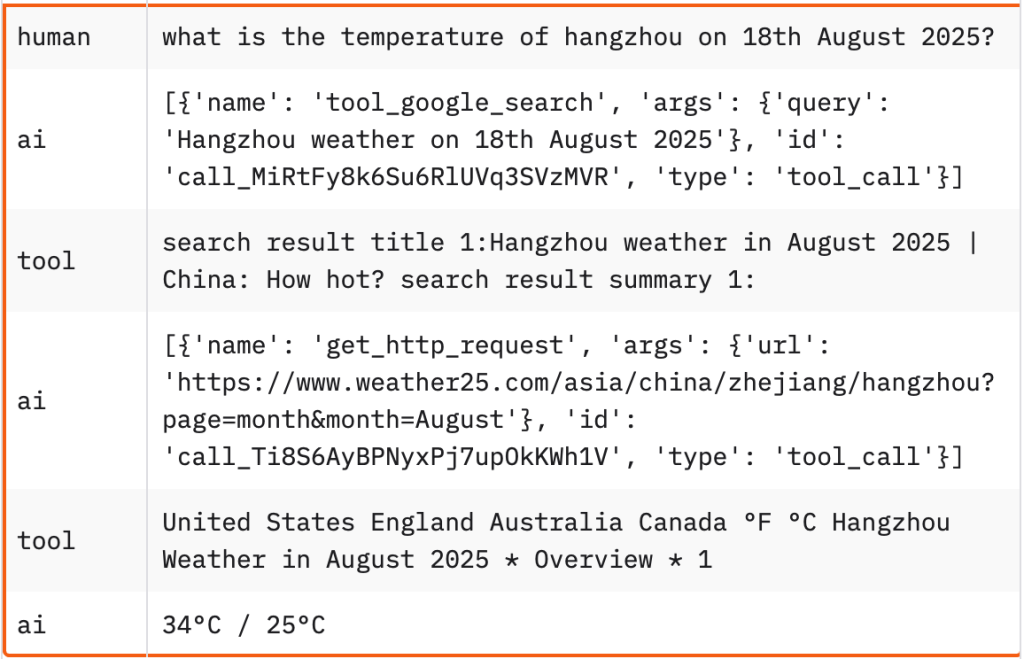
在这里为了看看“Agent”内部的推理过程,我们将其过程展示如下,如下为消息流:
- 首先,由人类发起提问:杭州8月18日气温多少?
- AI 首先决定使用工具执行 Google 搜索
- Tool 返回搜索结果(右侧展示有截断)
- AI 再决定访问一个具体的网页
- Tool 返回了页面的完整内容
- AI 最后决定给出最终的回答
注:这里呈现的消息并不是完整的和大模型调用时的实际消息,诸如system prompt和function call相关的部分并没有展示。
Agent 构建过程中的一些经验
Token 数量控制
对于此类通用“Agent”,有过实践经验的都知道,真的非常消耗“Token”。一个网页访问、一个搜索结果可能都需要数千甚至数万的“Token”,有时候,获得一个问题的答案需要数次搜索和页面访问,那么一个问题就可能消耗数万“Token”,这大概也是“Manus”定价有一定门槛的重要原因,所以,在构建“Agent”需要在过程中监控“Token”的数量使用。
包括,监控每次与LLM交互过程中的“Token”使用,以及工具调用中诸如图片、语音分析时等工具涉及的“Token”使用等。必要的时候,则需要进行“截断”处理,一方面是的“Token”数量不超过窗口上限,另一方面也可以适当节省“Token”,但这时候,也需要注意,截断后的内容可能会损失重要信息,导致推理失败,也需要做好这方面的异常处理。
多模模型还是多个模型
当同时需要处理文本、语音、图片等多种数据时,是选择一个多模模型处理,还是选择多个不同的专有模型处理?这里给出的经验是:可以选择多个模型处理。
不同的模型在训练的时候,尤其是微调阶段,都是面向特定类型任务的,这就很大程度上决定了模型适合的场景。在当前阶段,由于各个专有模型通常都有更好的准确度,更强的垂直场景适配能力等。各个模型平台都提供了非常方便的模型接口和接入能力,所以,推荐使用多个模型处理。
这里没有单独去做测试,但专有模型处理速度更快、效果更好是有直观感受的。
这里需要注意的是,基础的文本生成、推理模型最好还是使用“OpenAI”的模型,在开发中注意到,LangGraph对于“OpenAI”或其兼容接口的模型有着最好的兼容性。例如,如果使用HuggingFace Hub的Endpoint模式,则可能会无法简单的实现工具绑定(参考:LangGraph fails to make tool calls with models hosted via TGI.)。而对于独立的语音、图片等专有的场景的推理,则可以独立的使用HuggingFace的Endpoint模式。
Google 搜索还是 DuckDuckGo
DuckDuckGo 提供了非常低的搜索上手门槛,但经过一些实践,还是发现Google有着更好的搜索质量。这种好的搜索质量,可以再某些情况下,非常快速的帮助Agent找到目标答案。
但是,Google使用起来要稍微麻烦一些,需要一个Google的搜索API KEY,还需要一个Google Cloud的API KEY,好在都是一次性配置的工作。
所以,在初次实现时可以先试用DuckDuckGo,再后续改进的时候再更换搜索工具。
其他说明
因为这里会使用大模型去调用网页,那么在设计时,是需要注意一些安全问题的。例如,有的网站的服务或者说“Action”可能都是通过“http”服务的方式提供的,那么,这里的“网页访问”可能具备潜在的“操作”能力。
此外,要完成一个更具实践价值的功能,则通常还需要更多能力,例如提供多轮对话、记忆能力等功能,依据此则可以构建成一个更为企业化能力的“Agent”。
Leave a Reply