上一次写DTCC已经是15年前了(参考:DTCC关于MySQL的未来),今天又有写一点什么的冲动了。因为要“练摊”,所以也只能是“部分”观察。
AI 到底会如何改变数据库领域
这次会场上,对于“佰晟智算”和“银联”在AI方向的一些探索关注的多一些,其他时间,则主要是在NineData展台“练摊”。说说一些感受吧。“佰晟科技”主要聚焦于国产化数据库的优化、监控管理等方向,最为亮眼的创新在于,将大模型的能力与“运维知识”深度的结合起来。白鳝很早就在给产品做市场预热了,所以,在产品推出比较短的时间能,就快速的获得了一些早期的种子客户。

“银联”则是在内部的数据库管理上,做了很多的探索。银联有非常强的自主研发能力,也做了很多的智能化探索,包括Text2SQL、SQL的性能诊断等。Text2SQL很多的企业做了探索,但由于表名、列名的识别对于大模型来说,是非常困难的(一方面由于列可能非常多、而且命名比较简短),会让大模型出现非常强的幻觉问题,这使得在复杂OLTP场景,Text2SQL依旧难以胜任。但对于一些较为简单的场景,例如比较比较少,表、列都使用非常规范的时候,对于部分开发者,依旧有帮助。也注意到,有很多的企业在BI或者“取数”、“报表”场景,做了非常多的探索。

在SQL优化的方向,AI的能力,已经得到了开发者比较一致的认可,大模型虽然可能会给出一些不太实用的建议,但是“正确”的优化建议,也总是在大模型给出的建议列表之中。这对于,DBA渐少的时代,对开发者来说,确实非常友好。
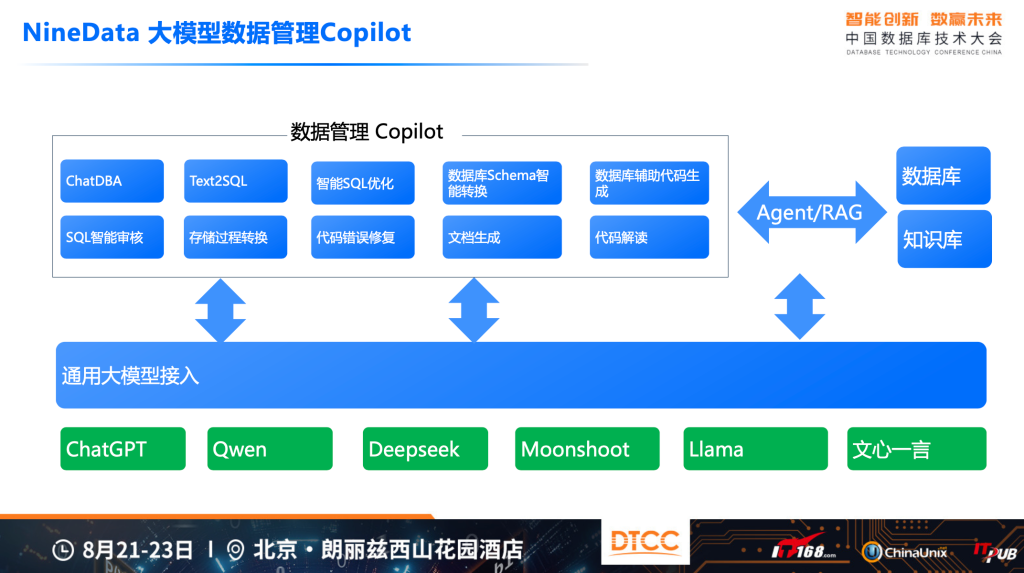
NineData 在这个方向上,也做了很多探索,从最早发布ChatDBA以来,后续持续在“DDL转换”、“SQL 优化”、“Text2SQL”、“国产化转换”等方向去尝试,这些功能随着基础大模型的增强,以及辅助以各种优化,确实可以让开发者的数据库管理变得简单一些。
Memobase
还听了一场 Memobase 的分享,是一个关于大模型“memroy”的产品。创始人非常技术,整个介绍听下来,如果稍不留神,甚至不知道演讲者是来介绍 Memobase 的,而是把业界的“memroy”产品以及相关的技术栈介绍了清楚。本以为这可能是一个略微冷门的话题,但从现场的问答环节来看,开发者们在这个方向上有很多的问题要解决。

这个是一个依旧在快速发展的方向。无论是Memobase还是Mem0,这类产品,与数据或者数据库的关系比较有趣的。简单的数据存储,即便是多模态存储,是无法简单的解决此类问题的。此类问题,当前,依旧是比较偏场景化的解决方案,例如,当天讨论的最多的,包括问答机器人、智能对话陪伴等。这些具体的场景下,产品需要深入到场景之中,才能解决开发者的问题。至于存储方案,可能不是当前最为紧迫的问题,所以存储上,可以用S3、也可以用“EloqData”、也可以考虑类似于MongoDB等其他的产品。
Memobase 比较强调自己在 Latency 方面的优势,但是,目前来看,在一个Chat的场景下,多个百毫秒的Latency,似乎并不是问题。
之所以,这里比较强调多模态的存储,主要在于:在这个场景中,通常会使用如下的方案,包括,使用 Graph 存储一些关联关系,例如一个人的朋友、“属性”等信息;还会大量使用json存储诸如profile、conversation 历史等信息。此外,这类方案,与RAG类似,也非常依赖注入Embedding、bm25等相似搜索,用于处理历史消息等。
总得来说,是一个场景化的,混合的存储方案,去应对业务场景。
创新与迭代是唯一出路
这次在现场也与很多朋友讨论了 AI 对数据库从业者(不限于)的影响,大家也都有着类似的看法,如果你不是做基础大模型的,那么,基本上,如果你能够更好的使用 AI,那么就有可能开发者出更好的产品;如果你的产品,能够更好的使用AI的能力,你的产品可能会在市场上有更强的竞争力。
对于开发者来说,确实应该更加积极、甚至激进的去拥抱 AI 技术。LLM从出圈到现在,一共也就两三年时间,所以,“大家的起点都一样,不要犹豫,往前跑就可以了”。
这个说法在当初ChatGPT刚出来时,Google也有类似的论断类似:““我们没有护城河,OpenAI也没有(We Have No Moat, And Neither Does OpenAI)”。事实上,经过也就两年的时间,Google Gemini 的能力、体验与市场,已经逐步在赶上ChatGPT。
另一方面,现在整个社会最多的风投资金、最聪明的人都聚集到了这个领域,这个领域的发展和变化,可以说是“日新月异”,这个领域一定会出现很多新的商业模式和企业。但如果,跑得晚了,后面的追赶会更加吃力。从最近的Zack如此大价钱的挖掘 AI 人才,也可能看出,即便是,最头部的厂商,在这个势头下,也是非常焦虑的。
向量数据库是AI还是数据库
向量存储在搜索在多个AI场景都有这广泛的使用,这次大会上,包括腾讯、华为、中兴、Oracle等厂商都介绍自己自己在这个方向的探索,包括海量存储下的性能优化、标量与向量混合查询的性能、面相RAG常见的效果优化、高效的向量缓存方案等。

最后
DTCC 是一年一度的数据库领域朋友聚会,非常开心。因为要“练摊”的原因,错过了很多的主题分享,今年的DTCC就简单记录如上。
Leave a Reply