大概是在朋友圈看到的这个会议 GOSIM(Global Open-Source Innovation Meetup),注意到有来自HuggingFace、vLLM、SGLang、BAAI 、字节等开发者来分享,果断报名去学习。大会是周六、日两天大概有接近10个分会场同时并发分享,于是只能选择一些自己感兴趣的部分主题听听,本文是部分见闻记录与分享。
推理优化与推理框架
这次关于大模型“推理优化”相关的话题特别多,包括 vLLM、Llama.cpp、SGLang、🤗 Optimum、Chitu、kTransformers、llm-d 等。大模型要能够向企业或组织提供服务,除了通过 API (SaaS)的方式之外,最为常见的则可能是需要搭建一套具备高并发服务能力的平台,而这些平台则需要满足高并发、底层本、易运维等要求,这就是上述这些框架、工具所解决的问题。相关的研究和发展方向则集中在KVCache优化、网络优化、PD分离、容器化管理、量化效率提升、多硬件适配、国产化适配(Chitu)、expert deferral等。
如果用数据库类比的话,这大概相当于各种 DBPaaS 平台如何通过调度、CPU硬件、网络设备去提升整理的数据库资源利用率。但是,LLM/VLM等所面临的问题,则更多的关注在 GPU (或与CPU协同等)层面。
“赤兔”定位是开源的「生产级大模型推理引擎」,面向于国产硬件环境做了很多适配,是一家“清华”背景的计算机专家推出的产品,背后的公司是:清程极智。
SGLang 是一个被比较广泛使用的大模型 大语言模型(LLMs)及多模态语言模型(VLMs)推理平台。该项目是LMSYS的一部分,目前似乎是以非盈利组织的模式在运作。该组织,最初是源自美国多所大学协作的项目(参考)。LMSYS 开发的其他著名项目包括:Chatbot Arena 、SGLang、FastChat、Vicuna LLM等。
🤗 Optimum 是对 Transformer 库的扩展,目标是能够让模型能够更加高效在多种不同的硬件平台上高效的运行,包括训练和推理等。目前适配的硬件包括了NVIDIA、AMD、Intel、AWS Trainiu/Inferentia、Google TPUs、Habana、FuriosaAI,此外也可以非常方便与多个开源模型优化矿建进行集成,例如ONNX、ExecuTorch、Exporters、Torch FX。


Second Me
现在的大模型学习能力确实非常强,也许真的可以虚拟出一个“人”完整的“影子”。这个项目非常有意思,也获得了非常多个关注,项目的强调 “AI that amplifies, not erases, YOU.” 。项目的构想在于使用本地模型和存储,基于个人的数据、事件等构建一个数字的自己。也许现在的 AI 技术让这个设想有了某种可能性,这个项目则是对这种可能性的探索。感兴趣的可以关注:Second-ME。
Agents
因为时间所限仅选择了部分 Agents 场次去听,包括“扣子空间”、“Google Agents”等。
来自Google的开发者则非常系统的介绍了面向Agent,Google为整个生态提供了哪些能力,其实是几乎覆盖了整个Agent生命周期的,包括了 Agent 构建SDK、Agent之间通信、Agent托管等一系列完整的服务。Google 对于 AI 各个方向都是非常大的,并且整体都很成功,这大概也能够顺利的帮助 Google 从搜索时代过渡到 AI 对话时代。
字节跳动的大模型(Seed)似乎还在“蓄力”阶段,但是上层的应用迭代和发展比较快。面相普通用户有“豆包”,面相开发者则有“扣子”,基于“扣子”,最近则退出了类似的“deep research”产品“扣子空间”。这次大会上,来自字节的工程师则分享了Agent、多Agent构建过程中的一些经验。此外也分享了一些有意思的“事实”:目前Agent领域发展非常快,在2024年初Agent基本上仅限于对话、陪伴机器人等少数方向;2024年底,智能客服则逐渐走向较为成熟的阶段;而现在则百花齐放,各个领域都在做大量探索,最为典型的就是“Manus”模式。
OpenSeek
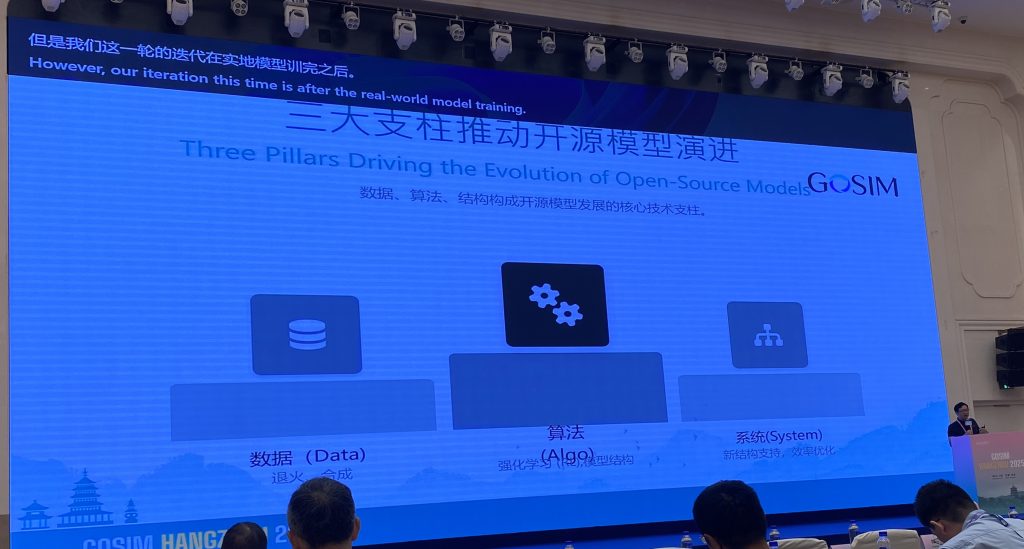
OpenSeek 是一个比较新的、由 BAAI 发起的一个开源大模型项目,该项目致力于构建一个更加完整开源大模型项目,而不是仅仅开源模型架构和参数,而是提供更加完整模型构建过程的代码,从而向开发者提供更加“开放”的模型。此外,这次分享中,也介绍了一些 OpenSeek 的一些基础实现,例如mid/post training,此外特别提到了 OpenSeek 的 DMA 机制(Dynamic Mask Attention 通过动态计算部分Token的Attention,降低计算复杂度)去实现更高性价比的模型训练与推理。感兴趣的可以访问 GitHub 地址:OpenSeek@GitHub。


MemTensor
随着 AI 技术的继续发展,预训练和后训练对于模型能力的增强的加速度是在下降的。那么,为了提升自然语言与模型的交互的效果,演讲者认为“记忆体”可能会成为增强大模型体验的关键组件。MemTensor团队则尝试通过将模型与“记忆”更加紧密的链接起来,从而增强模型的使用体验。
关注的议题:


最后
GOSIM 大会大概有超过十个分论坛在并行分享,还有很多关于具身智能、Rust等相关的技术。
Leave a Reply