
目录
在最初尝试了解 diffusion 模型的时候,原本是打算跳过 VAE (Variational Autoencoder 变分自编码 )模型的,后面发现有点跳不过去。再花了一些时间去了解 VAE,才意识到其实不应该跳过去,相反的,了解 VAE 实现的一些架构、原理、直觉、初衷、数学原理则可以大大帮助理解后续的生成模型。
1. 为什么现在你依旧需要了解 VAE
“潜空间”(latent space)的处理依旧是现代(SOTA)生成模型最为核心的组件。而从autoencoder模型,扩展到 VAE 模型,则是生成模型走出的关键步骤之一。将潜空间限制在一个正态分布的空间内,然后,在这个空间进行采样后进行 decoder 的生成思想,则是现代生成模型很多思想来时的路。
如果跳过这一段,很多的概念则会显得非常突然。
2. VAE 关键直觉与主要思想
2.1 关键直觉
在计算机与数学科学中有几个概念是反复出现的,其中之一就是“高斯分布”(或者叫“正态分布”)。在图像生成模型中非常关键的,则是将潜空间限制在了一个正态分布之中,为什么会这样?似乎并没有人去说明这一点,这里做一个简单的阐述和理解。高斯分布可以理解为大量伯努利分布的极限形式,现实世界的分布我们通常会假设其为大量微小因子的共同作用下的宏观表现,故通常假设其满足高斯分布。
那这与 VAE 有什么关系呢?在经典的 Guassian VAE 中,一个关键假设是:“潜空间” \(z \) 符合高斯分布的(通过训练来将其拉向高斯分布)。然后再对潜空间采样后,就可以生成较为“逼真”的图像了。那么假设“潜空间” \(z \) 符合高斯分布有什么深意吗?还是只是为了方便采样?
从直觉构建的角度,我们可以这样认为:潜空间的每个“维度”都有某这非常强的意义,例如色彩、风格、类型等,那么则有理由相信,一个对象在每一个“维度”上的分布也是符合正态分布的。即“潜空间”是一个符合正态分布的空间,那么从这个样本空间进行采样时,也就更容易得到一个有代表意义的点。
2.2 VAE 的主要思想
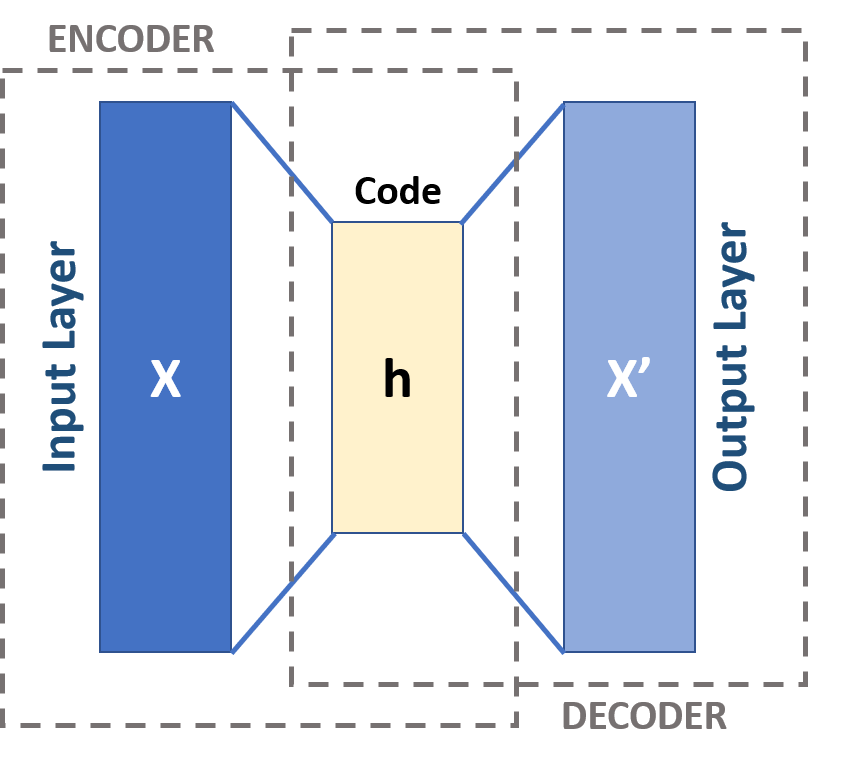
如何使用“神经网络”生成“逼真”的数据(例如图片、视频等)呢?在机器学习领域,一个比较自然的探索是从“autoencoder”架构去做一些尝试:“autoencoder” 由一个确定的encoder 将输入压缩到一个低维的“潜编码”(latent code)空间中,然后再由decoder根据“latent code”重建数据。
如右图所示,对于这样的神经网络设计其优势是非常明显的,这可以是非常好的“无监督学习”的神经网络,对比最终输出和输入的数据即可以作为损失函数。
但,在数据生成(例如新的图像生成)上,这样的设计在实践中也有着非常明显的限制:即对于如果随机选取一个“latent code”,通常只能生成一些无意义的数据。
2013年的 “Variational Autoencoder (VAE)” (Kingma and Welling, 2013) 架构则尝试解决这个问题:将“潜空间”(latent space)设计为某个符合某个概率分布结构。终于,可以生成出色的、逼真的数据(例如“图像”)。
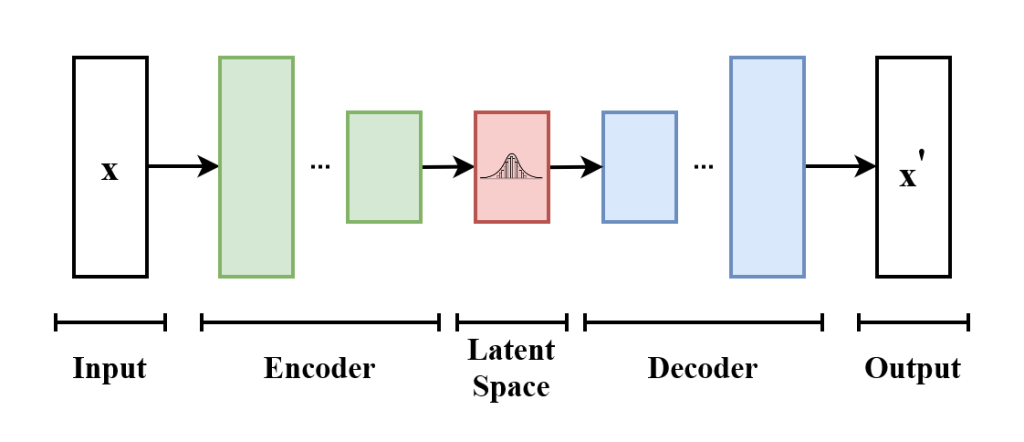

上述的描述可能还是比较抽象的,下面将实现一个基础的“VAE”模型,从而观测该模型的各个模块。
3. 一个简单的 VAE 模型的观测
3.1 模型架构概述
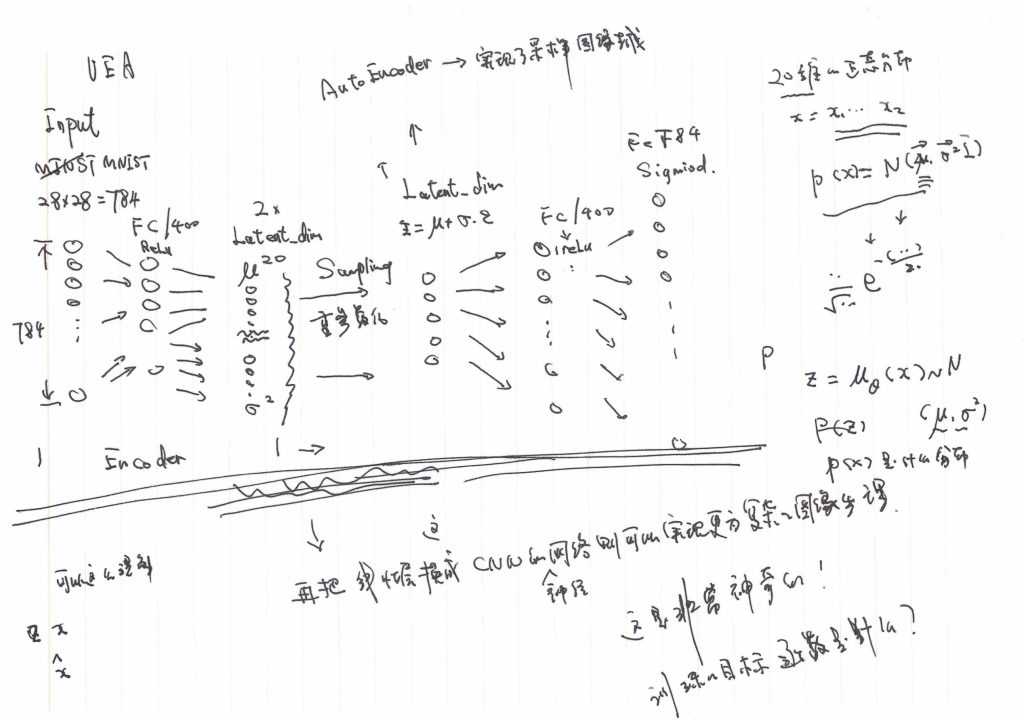
这里实现了(主要靠Gemini)一个由多个全连接层构成 VAE 模型。输入是 MNIST 数据集,输入层维度是 \(28 \times 28 = 784 \),中间的潜空间(Latent Space)维度为 20 ,包括 20 个均值和20个方差,然后是一个基本对称的decoder,包括一个400个神经元的全连接层和一个784个神经元的输出层,手绘描述如右图。
相关的代码实现参考:VAE-my-practice.ipynb。
这个神经网络结构之简单、生成效果之惊人,我自己是有点被震惊了的,相比于Autoencoder ,这里将“潜空间”限制在了某个概率分布之中,更为具体的是将每一个样本都“尝试”映射到正态分布中(注:\(p(z|x) \)是正态分布)。这里的“尝试”的做法是,先让神经网络输出“均值”和“方差”,然后再做一次重参数化的“采样”(Sampling)得到 \(z \)。
说明:\(p(z|x) \)是正态分布;从模型架构上看,\(p(z) \) 似乎并不是正态分布,但最终由训练的目标函数将\(p(z) \) “拉向”一个正态分布。
3.2 模型效果观测:某个点附近的数据

这里使用上述模型,将 MNIST 数据集中的一张原始图片计算出对应的正态分布,即均值和方差,然后使用该均值和方差进行了 11 一次采样,再生成 11 张图片,可以看到这些生成的图片和原始图片有非常高的相似度,同时又与原始图片不同。
即达到了生成“逼真”图片的效果。这种实现范式,展现出了非常强的图片生成潜力。也是后续 diffusion 模型的重要基础之一。

再从 \(z \sim \mathcal{N}(0,I) \) 随机采样一些值,再看看这些随机生成的效果,如右图。
可以看到,基本上能够生成一些有意义的图。这里只是使用了一些全连接层,即可以产生非常好的效果,可以预期,如果使用卷积神经网络,是可以有更好的效果的。
3.3 模型效果观测:空间中交接处的情况
从构建直觉的角度我们可以这样理解,encoder 层将原始的“向量空间”映射到了一个“潜空间”(latent space),该潜空间中的数据符合标准正态分布。所以,这就使得我们在“潜空间”变量 \(z \) 中做一个标准正态分布的采样,就可以使用 decoder 生成一个有意义的图片。并且,从构建直觉的角度,我们可以认为decoder 将正态分布中的点映射到“10个”数字的“空间”(784维)中,甚至可以认为(直觉角度)目标空间中有一片“连续”的空间即为“像空间”,这些空间某种程度可以“聚类”为“10类”,这些聚类的边缘则是一些介于不同数字之间的难以辨认的数字。
例如,我们考虑这样观测这些“聚类”中数字“1”和数字“0”之间的图像。我们先使用encoder计算(找一张图片作为输入)出数字“1”、“0”对应的均值,并以此作为对应数字在“潜空间”中的中心(更为严格的可以多计算一些相同的数字,再计算均值),然后在“1”、“1”对应的质心之间进行插值,然后观测这些“插值”经过encoder后的图片。

在放大33% ~ 66% 这个关键阶段:

3.4 模型小结
如上所述,encoder 最终把“原始的数据”映射到一个“潜空间”(latent space),“潜空间”中的数据(在线性代数中类似的概念称为“像空间”)符合正态分布。从从构建直觉角度我们可以有如下的一些理解和疑问。
VAE 模型尝试把“潜空间”限制在一个非常小区域,即以“原点”为中心的一个小“球”中(想想 3 \(\sigma \) 内就可能覆盖了 99.73% 的点),更为准确的是一片标准正态分布的概率云当中。问题:这种把“像空间”限制在小区域内,是否是实现“逼真生成”的关键因素?尝试回答:像空间的大小也许并不是关键的,毕竟,从数学角度来看,单位“球”可能与整个空间是一样大的,只是看起来小了而已;那么,关键可能在于把“像空间”现在在了某种结构上,这里的结构是标准正态分布空间。问题:为什么把“像空间”限制在某种结构上,就能够达到这样的效果呢?
在上述示例的“概率云”中,所有的点并不是“对等的”,概率密度相等的点,其意义也有着非常大的区别。从直觉的角度,例如最某个数字1的点 \(z_1 \in z \),在点 \(z_1 \) 附近的点则映射到的“像”也是更为接近的与数字“1”的点(这里的 \(z_1 = q_{\theta}(x) \quad \text{where} \, x \in \text{Samples} \))。
4. VAE 实现的一些细节
4.1 VAE的训练目标
VAE 模型将潜空间限制在了一个“正态分布”之中,通过在正态分布中采样的方式用来生成新的图片。这个过程并不是很好理解,这里介绍一下 VAE 的数学建模思路。
模型的训练目标(ELBO):
$$
\min_{\theta,\phi} \mathbb{E}_{q_{\theta}(z|x)}[\frac{1}{2\sigma^2}|| x-\mu_{\phi}(z) ||^2] + \mathcal{D}_{KL}(q_{\theta}(z|x)||p(z) ) \tag{1}
$$
关于这个式子的完整的数学推导,在网上比较好找到,有一些复杂、也不是很好理解。但是,这个式子的意义却比较明确:
- 前一部分,对于某个输入 \(x \),需要神经网络的参数 \(\theta , \phi \) 生成的图像\(x’ \)能够与原始图像接近
- 后半部分,则让神经网络参数\(\theta \) 是的分布 \(q_{\theta}(z|x) \) 靠近 \(p(z) \)即标准正态分布
4.2 VAE的数学模型
理解 VAE 比较困难的大概是这背后的数学模型,而理解了这个“数学模型”才可能进一步理解上述的公式,以及更多的VAE以及后续生成模型的思想。所以这里总结一些我对这个“数学模型”的理解:
Encoder 部分 \(q_{\theta} \) 是将一个图片 \(x \) 映射到一个概率分布(而不是某个具体的值),通常是 \(\mathcal{N}(\mu,\sigma^2) \)。那么,在神经网络中,如何将一个具体的样本/数据 \(x \) 映射到一个概率分布呢?是这样的:神经网络则需要输出/拟合/回归出该分布的关键参数即可,例如对于正态分布只需要给均值和方差即可。这也是为什么在上述的“示例VAE”中 Encoder 部分输出即为分布 \(z \sim p(z) \) 的均值与方差。那么,要从潜空间 \(z \) 中取一个值(即采样一个值)的时候,则需要“随机”的做一次生成,这里的“随机”则使用了“重参数化”技巧进行处理从而解决训练时向后传播的随机性问题。更为一般的即:$$ q_{\theta}(z|x) := \mathcal{N}(z;\mu_{\theta}(x),\text{diag}(\sigma_{\theta}^2(x))) \tag{2} $$
Decoder 部分 \(p_{\phi} \) 则是将潜空间的采样 \(z \) 映射到一个概率分布,而不是一个具体的值,但这里可能感觉是一个具体指的原因是,通常输出就是这个分布的均值(或期望),而不再另外进行采样操作。在常见的 Gaussian VAE 中,更为一般的有:
$$ p_{\phi}(x|z) := \mathcal{N}(x;\mu_{\phi}(z),\sigma^2 I) \tag{3} $$
最后,有了这两个定义公式(2)、(3),就可以计算上述的损失函数公式(1)了。
5. VAE 中的数学推导
这大概是最难理解的部分,甚至注意到很多领域内的专家(更加注重实践能力),对于这部分也很头疼,这里做一些尝试。
5.1 VAE 基本数学概率模型与训练目标
我们有一个上述的 VAE 模型,其中:
- \(\theta \) 为encoder部分参数,\(\phi \) 为decoder 的参数
- \(p_{\theta}(z|x) \) 表示对于给定的输入 \(x \),encoder 将输入映射为分布\(p_{\theta}(z|x) \) ,通常按照上述的公式(2)定义
- \(p_{\phi}(x|z) \) 表示对于给定的潜空间采样值 \(z \),decoder 将其映射为分布\(p_{\phi}(x|z) \) ,通常按照上述的公式(3)定义
在数学形式上,就可以有目标端(神经网络的输出)\(x \) 的分布:
$$
p_{\phi}(x) = \int p_{\phi}(x|z)p(z)dz
$$
这是一个形式上的表达,并不能直接计算,这是因为 \(p_{\phi}(x|z) \) 是一个由神经网络定义的映射或分布,对于每一个 \(z \),并没有一个简单的表达式给出\(p_{\phi}(x|z) \)的形式,或者更为直接的,在公式(3)中的 \(\mu_{\phi}(z) \) 由神经网络定义,并没有数学形式的表达。
这个式子确实不可计算,在实际训练中,则做了一些数学“推导”,训练另一个与此相关的式子(ELBO),这个我们后续再看。
所以,对于 VAE 模型的训练,即需要最大化:
$$
\max_{\phi}\sum_\limits{i} \log p_{\phi}(x_i) \quad \forall x_i \in \text{Sample Data} \tag{4}
$$
即对于最终的概率分布(PDF)\(p_{\phi}(x) \),任何的真实的图像(对应的 \(\forall x \in {\text{data}} \))所对应的密度值取值都需要很大,才能最终使得上述式子取值最大。
这似乎还比较抽象,这里我们进一步解释一下上述的式子(4)。考虑真实分布为 \(p_{\text{data}}(x) \),通常我们可以使用 KL 散度衡量两个分布的距离,那么,就需要最小化这个散度值:
$$
\begin{aligned}
\mathcal{D}_{\text{KL}} &= \int p_{\text{data}}(x) \log \frac{p_{\text{data}}(x)}{ p_{\phi}(x)}dx \\[0.8em]
&= \int p_{\text{data}}(x) \log p_{\text{data}}(x)dx – \int p_{\text{data}}(x) \log p_{\phi}(x)dx
\end{aligned}
$$
上述式子中的前项是一个常数(认为真实世界的分布是确定的,是拟合的目标,其实就是这个分布的“熵”),那么要这个散度值最小,就是让上述式子中后一项最大,即 \(\int p_{\text{data}}(x)p_{\phi}(x)dx \) 最大;在离散场景,积分则变成求和,并且 \(p_{\text{data}}(x) \)通常不可知,则通常使用\(\frac{1}{N} \)替代或者直接忽略,即有上面的式子(4)。
5.2 使用 ELBO 对上述目标进行近似
关于“Evidence Lower Bound” (简称 ELBO )虽然网上有很多的说明,但总是不够细致(或者要求对概率论有非常深的理解),这里做一个最为详细的推导和说明如下(应该是互联网上能够找到的最为详细的说明了)。
ELBO的定义为:
$$
\mathcal{L}_{\text{ELBO}}
=
\underbrace{
\mathbb{E}_{z \sim q_\theta(z|x)}
\left[ \log p_\phi(x|z) \right]
}_{\text{Reconstruction Term}}
–
\underbrace{
D_{\mathrm{KL}}\!\left( q_\theta(z|x) \,\|\, p(z) \right)
}_{\text{Latent Regularization}}
$$
可以通过严格的证明,如下不等式成立:
$$
\begin{equation}
\log p_\phi(x) \ge \mathcal{L}_{\text{ELBO}}(\theta, \phi; x)
\end{equation}
$$
证明如下:
$$
\begin{aligned}
\log p_\phi(x) &\stackrel{(1)}{=} \log \int p_\phi(x, z) \, dz \\[0.8em]
&\stackrel{(2)}{=} \log \int q_\theta(z|x) \frac{p_\phi(x, z)}{q_\theta(z|x)} \, dz \\[0.8em]
&\stackrel{(3)}{=} \log \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \frac{p_\phi(x, z)}{q_\theta(z|x)} \right] \\[0.8em]
&\stackrel{(4)}{\geq} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log \frac{p_\phi(x, z)}{q_\theta(z|x)} \right] \\[0.8em]
&\stackrel{(5)}{=} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log \frac{p_\phi(x, z) p(z)}{q_\theta(z|x)p(z)} \right] \\[0.8em]
&\stackrel{(6)}{=} \mathbb{E}_{z \sim q_\theta(z|x) p(z)} \left[ \log \frac{p_{\phi}(x|z)p(z)}{q_\theta(z|x)} \right] \\[0.8em]
&\stackrel{(7)}{=} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log {p_{\phi}(x|z)} – \log { \frac{q_\theta(z|x)}{p(z)} } \right] \\[0.8em]
&\stackrel{(8)}{=} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log {p_{\phi}(x|z)} \right] – \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log { \frac{q_\theta(z|x)}{p(z)} } \right] \\[0.8em]
&\stackrel{(9)}{=} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log {p_{\phi}(x|z)}] – \mathcal{D}_{\mathrm{KL}}(q_\theta(z|x)||p(z)) \right] \\[0.8em]
\end{aligned}
$$
各步骤的说明:
- 步骤 (1) 为边缘概率公式
- 步骤(2) 分子、分母都乘以了 \(q_\theta(z|x) \)
- 步骤(3) 使用期望的形式改写上述公式(可以想一想连续形式的概率期望计算),这一步是为了转化为下一步可以使用 “Jensen” 不等式
- 步骤(4) 这里使用 “Jensen” 不等式,对于凹函数 \(\varphi \)有 \(\varphi(\mathbb{E}[X]) \geq \mathbb{E}[\varphi(X)] \) ,函数 \(f(x) = \log (x) \) 即为凹函数
- 步骤(5) 分子、分母都乘以 \(p(z) \)
- 步骤(6) 使用基础的条件概率公式 \(p_{\phi}(x|z)p(z) = p_{\phi}(x,z) \)
- 步骤(7) 使用对数函数基本性质 \(\log \frac{ab}{c} = \log {a} – \log \frac{c}{b} \)
- 步骤(8) 使用期望公式的线性特性 \(\mathbb{E}[X+Y] = \mathbb{E}[X] + \mathbb{E}[Y] \)
- 步骤(9) 使用了KL散度的定义,简单的说,即概率密度对数的差的期望即为散度
步骤(9) 也最终与前述的 \(\mathcal{L}_{\mathrm{ELBO}} \) 定义完全相同,故得证。
Leave a Reply