admin
-
标题:阿里云发布RDS AI助手,集成DuckDB;向量数据库VexDB发布;火山veDB/MongoDB新增向量检索;AlloyDB AI支持NL2SQL
重要更新
新的向量数据库 VexDB 正式发布,该数据库由清华研发团队,能够支持百亿千维向量数据毫秒级查询,召回准确度高,并在国际权威的 DABSTEP 非结构化数据分析测试中,VexDB 的数据代理系统以领先第二名超 10 个百分点的成绩夺冠[1]。
阿里云 RDS MySQL 深入集成 DuckDB ,一方面可以支持独立的DuckDB分析主实例,另一方面也可以通过数据库代理实现HTAP自动行列分流的方式使用DuckDB分析只读实例[134][135]。(注:RDS PostgreSQL亦支持 DuckDB)
阿里云RDS产品推出全新智能运维助手“RDS AI助手”,其基于大语言模型与专家知识库,集成智能问答、性能诊断、个性化Agent与安全控制四大能力。只需简单提问即可自动获取异常诊断分析、性能优化建议与全局资源洞察,实现高效排查与规模化管理,显著提升RDS运维效率[137]。
云数据库 PostgreSQL 提供了 tencentdb_ai 插件,方便您在云数据库 PostgreSQL 实例中轻松调用网络可通的大模型 API,完成各种场景的应用开发。[225]
更新详情
阿里云
- RDS MySQL HTAP自动行列分流,该功能可以通过数据库代理实现HTAP自动行列分流,将OLAP查询请求路由至DuckDB分析只读实例[134]
- RDS MySQL蓝绿部署功能支持MySQL 5.6升级至MySQL 5.7及8.0。[135]
- RDS新增DuckDB分析主实例,通过在MySQL内核中深度集成DuckDB引擎,将分析查询的性能提升至MySQL InnoDB引擎的百倍以上[136]
- 阿里云RDS产品推出全新智能运维助手“RDS AI助手”,其基于大语言模型与专家知识库,集成智能问答、性能诊断、个性化Agent与安全控制四大能力。您只需简单提问即可自动获取异常诊断分析、性能优化建议与全局资源洞察,实现高效排查与规模化管理,显著提升RDS运维效率。[137]
- RDS MySQL高性能本地盘部分独享型实例提升了默认最大连接数和最大IOPS。[138]
- RDS MySQL支持数据库代理跨可用区部署,并新增就近访问功能。可通过新功能实现应用程序、代理节点、只读节点均在同一可用区,最大程度降低延迟。[139]
- RDS MySQL标准版(原X86)集群系列增加64核 128GB(mysql.x2.8xlarge.xc)和64核 256GB(mysql.x4.8xlarge.xc)规格。[140]
- RDS MySQL集群系列实例支持库表恢复功能,可用于误操作后的快速订正,以及分析历史数据等场景。[142]
- RDS MySQL全面升级了全球多活数据库(简称GAD)产品,GAD基于RDS与DTS产品打造,融合了灾备与多活两大能力,作为一站式、高性价比的灾备与多活解决方案,为用户提供全面的灾备和多活数据库服务。[143]
- RDS MySQL新增支持通过控制台设置列加密规则及相关用户角色权限,而不仅限于通过SQL进行设置。[144]
- 创建或配置RDS MySQL Serverless实例时,RCU的选择范围从原来的[0.5,16]变更为[0.5,32],最大可支持32RCU。[149]
- RAG Agent 检索增强生成解决方案发布,通过与Supabase生态的深度集成,该解决方案能够自动化处理来自云存储的文档,并支持多模态解析、知识图谱构建等高级功能[153]
- RDS PostgreSQL推出DuckDB分析实例,该实例专门用于处理分析类工作负载[154]
- RDS SQL Server 异地容灾功能新增支持更多能力:支持更多海内外地域。[175]
- RDS SQL Server支持将Serverless实例转换为按量付费实例[176]
- PolarDB支持共享备份集。该功能基于阿里云资源共享服务,允许您安全地将指定备份集授权给其他阿里云账号使用,以用于集群恢复。[190]
腾讯云
- TDSQL-C MySQL 、云数据库 MySQL 分析引擎(LibraDB)发布了全新的内核版本3.2503.7.0和2.2410.13.0,支持了诸多全新的内核特性,并对系统问题进行了修复和优化。[192][205]
- 数据库代理支持配置只读分析引擎故障转发至只读或读写实例。同时支持 SQL 通过读权重转发至只读分析引擎。[197]
- 支持在控制台中查看只读分析引擎实例的慢 SQL 明细与 SQL 分析报告。[198]
- TDSQL-C MySQL 版实例形态为 Serverless 的集群支持二级存储功能,开启二级存储可帮助用户实现存储资源的动态分配和高效利用,节省存储成本开销。[209]
- 云数据库 PostgreSQL 正式支持 PostgreSQL 18.0[221]
- 云数据库 PostgreSQL 支持更多常用插件如 age 、orafce [222]
- 云数据库 PostgreSQL 提供了 tencentdb_ai 插件,方便您在云数据库 PostgreSQL 实例中轻松调用网络可通的大模型 API,完成各种场景的应用开发。[225]
- 云数据库 SQL Server 支持通过数据库传输服务 DTS 进行 SQL Server 到 SQL Server 链路的数据同步[226]
AWS(亚马逊云)
- Aurora PostgreSQL Zero-ETL 与 Amazon SageMaker 集成支持更多区域[10]
- Aurora PostgreSQL Limitless 数据库已在其他 AWS 区域推出[11]
- RDS for Db2 支持备份单个 Db2 数据库[15]
- RDS 支持 Amazon RDS for Db2 的预留数据库实例[16]
- Amazon RDS 在数据库预览环境中支持 MySQL 9.4[18]
- RDS for Oracle 和 RDS Custom for Oracle 支持裸机实例类[22]
- Amazon RDS 支持 MariaDB 11.8[23]
- Amazon DocumentDB(兼容 MongoDB)现在支持基于 Graviton4 的 R8g 数据库实例[45]
- Amazon Timestream 现已支持 InfluxDB 3 [51]
Azure(微软云)
- PgBouncer 1.23.1 正式支持 Azure Database for PostgreSQL – Flexible Server [52]
- 高可用性 Azure Database for PostgreSQL 支持“近乎零停机时间扩展” [56]
- Azure Redis Enterprise 将于 2027 年 3 月 30 日停用[59]
- Azure Redis 缓存将于 2028 年 9 月 30 日停用[60]
- Azure Database for PostgreSQL 支持机密计算[63]
- Azure MySQL 发布“自愈”Self Heal功能 [67]
- Azure Database for MySQL 8.4 正式发布 [69]
- Azure Database for MySQL 近乎零停机维护(Near-zero-downtime)[71]
GCP(谷歌云)
- 现在您可以在BigQuery Studio中通过自然语言编写SQL[76]
- AlloyDB 支持
tds_fdw扩展,该扩展提供了一个外部数据包装器 - Cloud SQL for PostgreSQL 现在支持 PostgreSQL 版本 18(预览版)。[104]
- Spanner CLI 现已正式发布。它与 gcloud 捆绑在一起,您可以使用 Spanner 命令行界面打开交互式会话,或从 shell 或输入文件自动执行 SQL 语句 [107]
- 现在您可以使用 Gemini 的功能来修复 Cloud SQL Studio 中的查询错误[113]
- Cloud SQL 托管连接池现已正式发布 [121]
- 您可以使用专为 Cloud SQL for MySQL, PostgreSQL, SQL Server, AlloyDB 设计的 Gemini CLI 扩展程序来配置、管理和查询数据库。该扩展程序提供对数据库的完整生命周期控制,包括配置实例、探索模式和排查问题,所有操作均可通过命令行界面完成。 [132]
- AlloyDB AI 支持自然语言转SQL功能[133]
火山云
- 云数据库 MySQL 版提供的在线扩展 varchar 字段长度功能,支持在扩展期间执行 Online DDL[228]。
- 云数据库 MySQL 版提供的 IN 谓词性能优化特性在优化阶段可以对包含 IN 谓词的查询进行改写,消除 IN 谓词,改为和一张临时表进行 JOIN,进而提升查询性能[229]。
- 支持创建云盘版的单节点实例类型,满足更多业务场景需要[230]。
- 支持为实例的代理读写终端配置 SQL 转发规则,将匹配到的 SQL 语句转发到规则所指定的节点[231]。
- 支持 veDB-Search 混合检索:基于云数据库 veDB MySQL 版和云搜索服务(Cloud Search),用户可以基于 AI 向量检索等能力,构建智能推荐、RAG 知识库、Agent 记忆库等 AI 基础设施[232]。
- 云数据库 PostgreSQL 支持为实例开启 SSL 加密,并支持更新 SSL 证书[233]。
- 文档数据 MongoDB 版提供了向量检索(Vector Search)能力,Vector Search 支持依据语义而非仅依靠关键字匹配来查询数据,有助于获取相关性更强的搜索结果。
百度云
- RDS MySQL 支持数据库大版本升级[234]
- MySQL 5.7版本支持线程池
- 支持手动切换主备实例,手动切换可用于容灾演练或多可用区场景下的就近连接等需求。[236]
- 创建GaiaDB集群时,代理规格支持随集群规格自适应;GaiaDB代理支持配置读权重
- Redis 集群版支持升级代理节点版本,高版本的代理节点通常具备更好的性能、更高的稳定性。[238]
- Redis 跨可用区部署,开启就近访问之后,主可用区的读请求仅会路由至主可用区的主节点或只读节点,备可用区的读请求也仅会路由至备可用区的只读节点,降低读延迟。
华为云
- TaurusDB Serverless服务优化升级:实例起步规格调整为0.5TCU,同时开放弹性策略自定义[239]。
参考链接
- [1] https://vexdb.com/
- [10] https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.Aurora_Fea_Regions_DB-eng.Feature.Zero-ETL.html
- [11] https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/limitless-reqs-limits.html
- [15] https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/db2-sp-managing-databases.html#db2-sp-backup-database
- [16] https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_WorkingWithReservedDBInstances.html
- [18] https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/MySQL.Concepts.VersionMgmt.html#mysql-preview-environment-version-9-4
- [22] https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Concepts.DBInstanceClass.html
- [23] https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/MariaDB.Concepts.VersionMgmt.html
- [45] https://aws.amazon.com/about-aws/whats-new/2025/10/amazon-documentdb-graviton4-based-r8g-database-instances/
- [51] https://aws.amazon.com/about-aws/whats-new/2025/10/amazon-timestream-influxdb-3/
- [52] https://azure.microsoft.com/updates?id=513254
- [56] https://azure.microsoft.com/updates?id=508403
- [59] https://azure.microsoft.com/updates?id=499606
- [60] https://azure.microsoft.com/updates?id=499577
- [63] https://azure.microsoft.com/updates?id=500795
- [67] https://azure.microsoft.com/updates?id=501999
- [69] https://azure.microsoft.com/updates?id=501989
- [71] https://azure.microsoft.com/updates?id=500765
- [76] https://docs.cloud.google.com/bigquery/docs/write-sql-gemini#generate_sql_from_a_comment
- [104] https://cloud.google.com/sql/docs/postgres/create-instance
- [107] https://cloud.google.com/spanner/docs/spanner-cli
- [113] https://cloud.google.com/sql/docs/sqlserver/write-sql-gemini#fix-query
- [121] https://cloud.google.com/sql/docs/postgres/managed-connection-pooling
- [132] https://docs.cloud.google.com/sql/docs/mysql/pre-built-tools-with-mcp-toolbox#mcp-configure-your-mcp-client-geminicli
- [133] https://cloud.google.com/alloydb/docs/ai/natural-language-overview
- [134] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/htap-based-automatic-query-routing-is-available-for-apsaradb-rds-for-mysql
- [135] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/blue-green-deployment
- [136] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/duckdb-analysis-instance/
- [137] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/rds-ai-assistant
- [138] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/the-default-maximum-number-of-connections-and-maximum-iops-of-apsaradb-rds-for-mysql-instances-with-premium-local-ssds-are-increased
- [139] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/new-features-new-specifications-cross-zone-deployment-and-nearest-access-are-supported-for-the-database-proxies-of-an-apsaradb-rds-instance
- [140] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/primary-apsaradb-rds-for-mysql-instance-types
- [142] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/restore-individual-databases-and-tables-of-an-apsaradb-rds-for-mysql-instance
- [143] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/release-of-global-active-databases-in-apsaradb-rds-for-mysql
- [144] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/configure-column-encryption-rules-in-the-apsaradb-rds-console
- [149] https://help.aliyun.com/document_detail/421557.html
- [153] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/rag-agent/
- [154] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/duckdb-based-analytical-instance
- [175] https://help.aliyun.com/zh/rds/apsaradb-rds-for-sql-server/geo-disaster-recovery/
- [176] https://help.aliyun.com/zh/rds/apsaradb-rds-for-sql-server/change-the-instance-billing-method-from-serverless-to-pay-as-you-go
- [190] https://help.aliyun.comhttps://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/shared-backup-sets
- [191] https://help.aliyun.comhttps://help.aliyun.com/zh/mongodb/user-guide/download-backup-files
- [192] https://cloud.tencent.com/document/product/236/115774
- [197] https://cloud.tencent.com/document/product/236/82248
- [198] https://cloud.tencent.com/document/product/236/124017
- [209] https://cloud.tencent.com/document/product/1003/119284
- [221] https://cloud.tencent.com/announce/detail/2140
- [222] https://cloud.tencent.com/document/product/409/75121
- [225] https://cloud.tencent.com/document/product/409/116227
- [226] https://cloud.tencent.com/document/product/238/124436
- [228] https://www.volcengine.com/docs/6313/1840904
- [229] https://www.volcengine.com/docs/6313/1840828
- [230] https://www.volcengine.com/docs/6313/75366
- [231] https://www.volcengine.com/docs/6313/1848599
- [232] https://www.volcengine.com/docs/6357/1820181
- [233] https://www.volcengine.com/docs/6438/1864761
- [234] https://cloud.baidu.com/doc/RDS/s/Umhbe5vhw
- [235] https://cloud.baidu.com/doc/RDS/s/9jwvyzuws
- [236] https://cloud.baidu.com/doc/RDS/s/dmfcb5uwc
- [237] https://cloud.baidu.com/doc/RDS/s/Ujwvz0py7
- [238] https://cloud.baidu.com/doc/SCS/s/Fmfca8y60
- [239] https://support.huaweicloud.com/usermanual-taurusdb/taurusdb_02_0210.html
-
新加坡之行
·
这次到新加坡在工作之余,也好好的了解了一下这个城市,如下一些随意的记录吧。
目录
花园城市“新加坡”
Rain Vortex@Changi Airport
一到新加坡樟宜机场(Changi Airport)就可以看到一个精心设计的壮观“室内瀑布”(the Rain Vortex):

the Merlion
此外,这次参加展会的地点是 Marina Bay Sands的Convention Centre,这里是新加坡地标式建筑“Merlion”所在地:

新加坡大概800年前被称为“Singapura”(马来语),意思是“lion city”,而更早之前,这里则是一个被称为“Temasek”的渔村。可以看到,“Merlion”的设计正是取自这两个名字所代表的意义。可以很好的代表这块土地过去千年的历史。
Gardens by the Bay
猜测,新加坡人的思路大概是,这个地方虽然不是很大,那我们就把这个缺点变成优点吧,于是,就把新加坡的每个地方都设计得非常精致。
在滨海湾花园(Gardens by the bay)这里,就非常精致。这里,有一个地方叫“Flower Dome”,里面摆满了来自世界各地的植物、鲜花;旁边是一个“Cloud Forest”,里面也有一个非常高的室内小瀑布,里面则是一个以“Jurrasic Park”和“Jurrasic World”为主题的展览。

关于“Singapore”名字的来历
“Singapore”一词来自于马来语的“Singapura[1]”,一把认为这个词语最初是来自梵文,意义为“Lion City”。
更为具体的,在梵文中,“Singa”来自梵文中的 siṃha (सिंह), 意思是 “lion”;而“pūra (पुर)” 意思为“city”,pūra也是很多印度地名非常常见的后缀(例如,Jaipur 斋浦尔)。
那新加坡于“lion”有什么关系呢?根据记载,大概在800年前,“Sang Nila Utama”来到这里,看到了疑似狮子的动物,故就将此地命名为“Singapura”,即“狮城”。至于到底当时看到的是不是狮子,现在已经不可考了,主流的看法似乎倾向于认为是其他的大型猫科动物。但,这个名字已经叫了800年了,故到底是什么动物,已经不再重要了。
在被叫为“Singapura”之前,这里是一个渔村,被称为“Temasek”,这词可能是来自马来语,表示“海边的地方”[1]。
“little india”
这次后面几天住的酒店是在“little india”区,这里保留了很多印度文化相关内容。比较有代表性的是“India Heritage Centre”,有点像一个“印度文化博物馆”,而最近正好是“Deepavali”节日前后,所以在这个“博物馆”的楼下,就有一些印度表演,虽然在电视上也看过一些印度舞蹈,但是现场看,感受还是非常不一样:

在“little india”区域中,另一个代表性的地方是一个叫“SRI Veeramakaliamman[2]”印度庙宇,这个神庙大约有150年的历史。

文化的异同
在新加坡众多感受之一是这里的“多元化”。在这里,多民族、多文化的融合做得非常好。
即便是在一个族群里面,人与人或者人群与人群的差异都是非常大的。更不用说,感受上,不同的族群之间的差异了,大家的语言、文化、习惯、信仰、肤色差异都很大,天然的也就会让人与人之间产生隔阂。新加坡在对于这种隔阂的消除、弱化上做得很好。大家都说一样的英语,虽然也保留自己的母语、大家都住在一样的房子里面,在一样的地方上学与生活,最终,让彼此最大限度的相处在一起。
在过程中,起初是感受到彼此的不同。而后,在印度神庙中,看到的大家脸上的对于诸神的虔诚,在哪里都是一样的;看到大家对于脱离痛苦的希冀,哪里都是一样的;看到爸爸带着孩子的介绍,孩子的好奇和父亲的关爱,哪里都是一样的;在India Heritage Centre为Deepavali表演的学生们脸上的自豪、兴奋与紧张,也都是一样的。
Raffles@National Museum of Singapore
周日,则去参观了新加坡国家博物馆。里面比较完整的介绍新加坡的历史。来的时候,已经注意到新加坡很多地方都以“Raffles”命名,包括最有名的酒店“Raffles Hotel”、“Raffles City”、“Raffles Institution”、“Raffles Place”等,而在国内也有一些高端的“来福士”商业中心。所以,参观时也特别留意了一下关于Raffles的介绍。

Raffles 全名是“Sir Thomas Stamford Bingley Raffles”,他被认为是现代新加坡的缔造者,曾是现代新加坡建立时的“总督”,虽然他在新加坡的实际任期时间并不长(“His longest tenure in Singapore was only eight months, but he was considered the founder of Singapore nevertheless.”)。主要原因在于[3]:
- 他很早看到了新加坡地缘所具备的潜力,在当时,事实意义控制了“现代新加坡”
- 制定了一系列具有现代化意义的城市规划与治理制度
最终,影响了这里发展成为真正的“现代新加坡”。
关于现代“Raffles”品牌
我并不关注当前的商业现状,出于好奇做了一些搜索和阅读。众多“Raffles”品牌可能是属于“淡马锡控股”[4],而淡马锡则是新加坡政府的投资公司,淡马锡则控制了众多新加坡的重要公司,例如“星展银行”(DBS)、Seatrium、新加坡航空、凯德置地(CapitaLand)等。李显龙的妻子何晶曾担任淡马锡控股的CEO[4]。
Lee Kuan Yew
Lee Kuan Yew 是当代新加坡国的实际建立者。关于他,已经有了很多中文资料,这里不再详述。
Java, the island
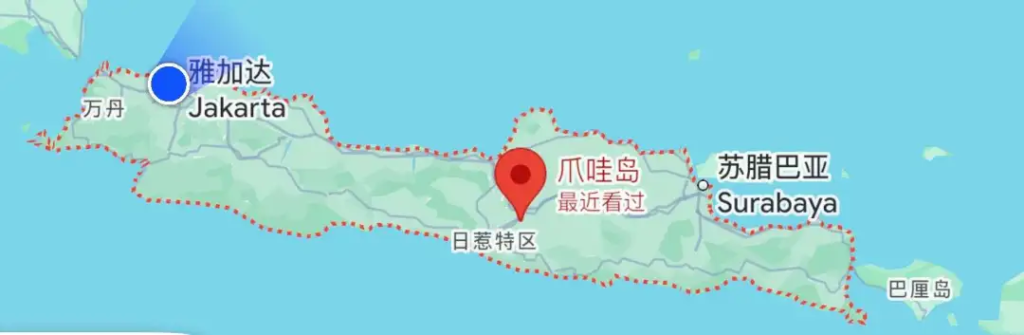
这次新加坡之行其中有两天去一趟 Jakarta-印尼的首都,位于Java岛的西北部。
Java 真的是一个岛,而且非常大。Java 岛是印尼人口最多的岛,也是印尼首都雅加达所在的地方。但如果在 Google 上搜索“Java”会发现,这个词已经被编程语言所占据,真正的“Java岛”的搜索结果只在第三,并且,整个第一页,只有这一个结果是与Java岛相关的。
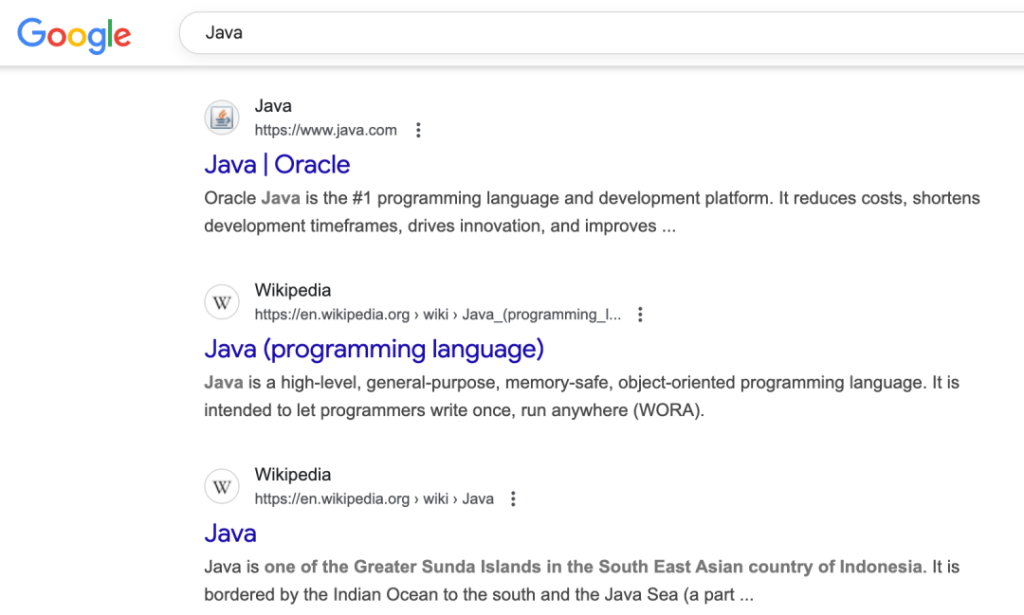
不管怎样,Java 语言已经带火 Java 岛的咖啡。如果,你恰好在写Java,再来一杯Java,是不错的,如果你恰好是在Java岛上,那可能就完美了。
参考链接
- [1] https://en.wikipedia.org/wiki/Names_of_Singapore
- [2] https://en.wikipedia.org/wiki/Sri_Veeramakaliamman_Temple
- [3] https://en.wikipedia.org/wiki/Stamford_Raffles
- [4] https://en.wikipedia.org/wiki/Temasek_(company)
-
LLM 强大的语言、知识与推理能力在改变很多领域,也将持续、深入的改变更多领域。在软件领域,“Agent” 的编程模型已经是一种新的编程模式,通过这种“模式”可以将 LLM 的能力,软件提供商的领域知识,以及外部工具的能力很好的结合起来,形成“新的”软件产品。
(more…)
