orczhou
-
标题: PolarDB-X 发布全新列存能力支持HTAP场景; 华为GaussDB泰国峰会在曼谷举行;
重要更新
华为云数据库泰国峰会在曼谷举行,峰会以“GaussDB:给世界一个更优选择”为主题。华为在会上与泰国本地客户和合作伙伴,共同展示了GaussDB解决方案,并提出GaussDB先锋计划。小编点评:先不管大模型sleep几秒,GaussDB在华为是一个战略级产品,在与其电信、政府、云业务一起协同服务客户 [1]
PolarDB-X 发布2.4版本支持列存能力,通过额外的基于列式结构的二级索引(Clustered Columnar Index,CCI,覆盖行存所有列),使用一张表可以同时具备行存和列存,同时满足分布式的OLTP和部分OLAP场景。 [2]
Oracle云
- Autonomous Recovery Service服务支了从相关联的Data Guard中备份与恢复Oracle数据库 [10]
- Oracle Data Safe 现在支持 Oracle Database@Azure [11]
AWS(亚马逊云)
- RDS for PostgreSQL 支持最新的插件 pgvector 0.7.0,以实现更完整的向量查询与搜索功能 [12]
- Amazon RDS宣布将对PostgreSQL 11.22版本提供最多三年的扩展支持(注:PostgreSQL 11最早与2018年发布,11.22是2023年11月发布的该系列最后一个小版本)[13]
- Performance Insights开始支持RDS for Oracle Multitenant [14]
腾讯云
- 云数据库 MySQL 双节点、三节点架构的主实例支持挂载多个灾备实例,帮助提升业务连续服务能力以及数据的可靠性。[15]
参考链接
- [1] https://mp.weixin.qq.com/s/f0Sef7IeuYwfM5EFc5iJeA
- [2] https://mp.weixin.qq.com/s/KMF2WuZ5iGTD-gASBxya_A
- [10] https://docs.public.oneportal.content.oci.oraclecloud.com/iaas/releasenotes/changes/500b6bfa-63b9-4060-b40a-57eae0cedfbf/
- [11] https://docs.public.oneportal.content.oci.oraclecloud.com/iaas/releasenotes/changes/6d9c7bae-4f13-416a-87ec-7eb3773e50eb/
- [12] https://aws.amazon.com/about-aws/whats-new/2024/05/amazon-rds-postgresql-pgvector-0-7-0/
- [13] https://aws.amazon.com/about-aws/whats-new/2024/05/amazon-rds-postgresql-extended-support-minor/
- [14] https://aws.amazon.com/about-aws/whats-new/2024/05/amazon-rds-performance-insights-oracle-multitenant/
- [15] https://cloud.tencent.com/document/product/236/7272
-
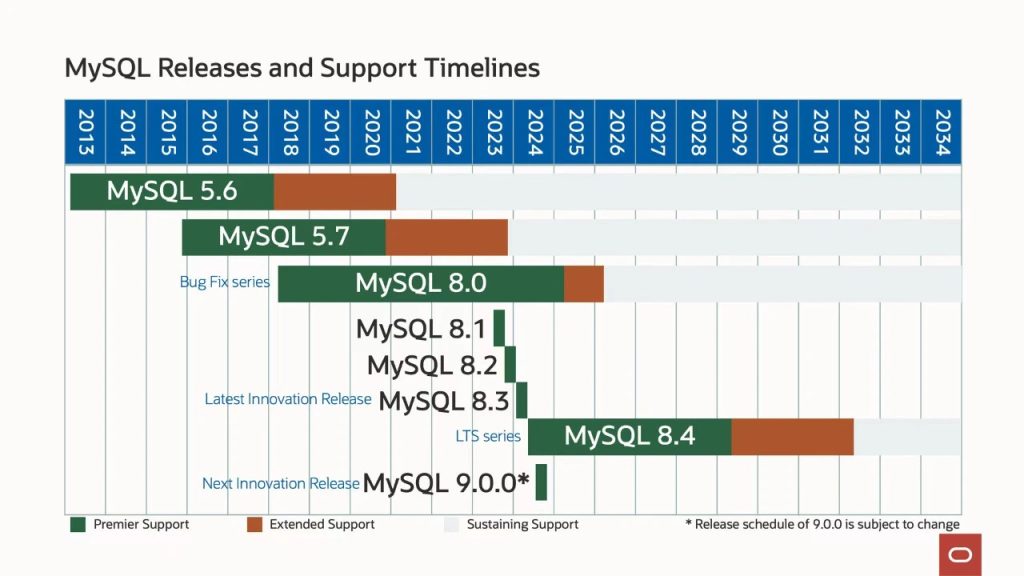
近日,MySQL发布了8.4版本,这是一个新的稳定版。在MySQL版本规划中,在2026年8.0.x生命周期结束后,将成为下一个主流稳定版本。
目前为止,看到该版本并没有特别大的改进。部分改变包括改进了直方图统计信息更新、并行复制、组复制(GR)等,完整的更新可以参考:Changes in MySQL 8.4.0 (2024-04-30, LTS Release)。
MySQL 8.4@OCI性能测试(vs MySQL 8.0)
Oracle Cloud上也第一时间支持了该版本,于是也通过性能测试的方式,第一时间“尝鲜”了一下该版本。性能测试的趋势图如下:
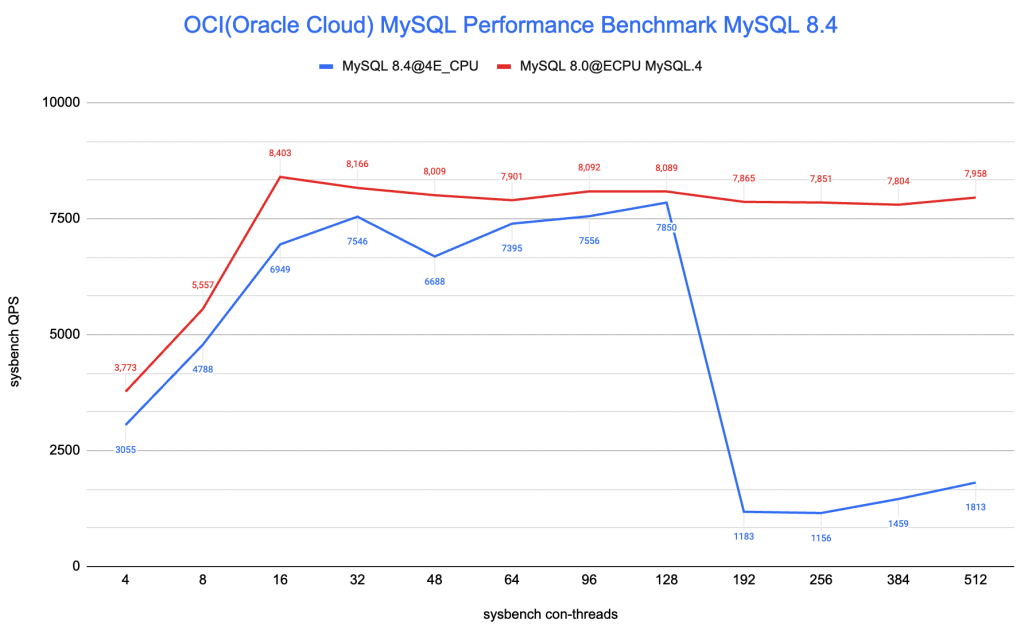
注意到,在该Sysbench测试模式下:
- 当前MySQL 8.4在性能上相对于8.0版本,要低21%(以16并发为参考)
- 并在超高并发时(并发高于192),性能出现了严重的退化
作为一个稳定版本,期待官方尽快解决。
(more…) -
自AWS在2009年发布第一个数据库服务RDS MySQL以来,其数据库架构已经发展了13年,这个过程中一直都保持着快速的更新,到现在为止,云数据库架构已经有了一定的复杂度。该架构图系列系统通过适当的简化,帮助开发者能够快速的了解,如何选择适合自己的业务场景的RDS架构与规格。如下:
(more…) -
在日常编写SQL中,使用变量来灵活的构建执行的SQL语句是比较常见的。就像在编程中使用变量、函数参数等是一样的道理。本文介绍使用JSON函数(JSON_ARRAY、JSON_SEARCH)、以及 FIND_IN_SET 如何简单的实现带有数据组变量的SQL拼接与执行。使用该方法,则无需使用CONCAT函数拼接SQL,再使用PREPARE/EXECUTE语法执行,所以会更加简洁,可读性、扩展性更强。
具体的,例如需要再查询结果中找到u_name在数组@u_list_j中的记录,那么使用JSON方式可以按照如下模式实现:
SET @u_list_j = JSON_ARRAY('zhou','wu','zheng','wang','zhuge'); SELECT id,u_name FROM t_01 WHERE JSON_SEARCH(@u_list_j,'one',t_01.u_name);另一种较为常见的方法是使用 FIND_IN_SET 函数。其使用方法如下:
set @u_list_s = 'zhou,wu,zheng,wang,zhuge'; SELECT u_name FROM t_01 WHERE FIND_IN_SET(t_01.u_name,@u_list_s);另外,还可以尝试使用 LOCATE 函数实现,只是使用该函数需要注意,在做字符串匹配的时候容易出现的重复、错误匹配问题。例如,数组中存在”zhuge”,那么匹配”zhu”,则可能匹配成功,但这并不是期望的结果。
示例表:
本文中使用的一些示例表如下:
CREATE TABLE t_01( id int UNSIGNED AUTO_INCREMENT primary key, u_name varchar(32) ); INSERT INTO t_01(u_name) values ('wu'), ('zhao'), ('qian'), ('sun'), ('li');
