简单生活
-

最近 midjourney 用的比较多,很好奇,这背后的技术大概是怎样的。好了,那就去做一些了解吧(补充注:后来我才发现这个坑有多大…)。
除了大语言模型之外,另一个非常活跃的领域就是图片处理技术,例如文生图(Text-to-Image)、多模态模型等。除了在原有的 CNN 技术架构上,也出现了很多新的突破。虽然同样使用的是深度神经网络,但图像生成技术与大语言模型技术(LLM)是非常不同的。其模型架构不同 ,底层的数学、物理原理也非常不一样。在对大语言模型有一个框架性的了解 之后,现在打算开一个新的“坑”,当然,也就没有打算爬出来,可能就“浅尝辄止”做个最为基础的了解。一般学东西,都是从 “Why/How/What” 的顺序,但在尝试了一下,无法理解“Why”后,于是就打算绕道,看看 How 和 What 了。那么,“What”打算就从“Foward Diffusion Process”开始吧。
整个文生图(Text-to-Image)的架构是比较复杂的,其中较为“简单”、基础 的一步即位“Forward Diffusion Process”,本文从“Denoising Diffusion Probabilistic Models”论文中为例,说明这个过程。
目录
1. 概述:“FDP” 是一个加随机噪声的过程
很多地方都会说:“Forward Diffusion Process” 就是一个添加随机噪声的过程。这话对、也不对。首先,“FDP” 确实是一个添加随机噪声的过程,但是这个随机噪声添加得非常有“讲究”。我们就从“添加随机噪声”和“讲究”两个角度去介绍。
“Forward Diffusion Process” 过程的数据是用于训练神经网络(通常是一个U-Net架构)的参数的,从而最终实现其逆过程(即“Reverse Diffusion Process”),而生成图片。
1.1 添加随机噪声
“FDP” 做如下的事情:
- 先读取一张图片(这里使用的一张博客图片)
- 将图片的每个像素点取值,随机“迭代加上”一个随机值 \(N(0,1) \)
例如,我们使用论文 DDPM 中的设定对如下图片添加噪声,就可以观察到如下过程:

更为详细的:
- 1. 先读取一张图片,并将其 RGB 通道的数据读取出来
- 2. 将像素值从 [0, 255] 的整数缩放到 [0.0, 1.0] 的浮点数
- 3. 每个通道每个点随机“迭代加上”一个随机值,按照 \(N(0,1) \) 分布生成该随机值
2. “线性”添加噪声
在 Denoising Diffusion Probabilistic Models 论文中使用了“线性调度”的方式添加噪声。即添加噪声的强度“线性”的逐渐增强,这里的“线性”是指增加的噪声的“方差”线性增加。
先用更加形式化的数学语言描述上述的噪声添加,即:
$$ x_t = A x_{t-1} + B \epsilon \quad \text{where} \quad \epsilon \sim \mathcal{N}(0,1) $$
2.1 调整权重系数
直觉上,可以这样理解,在添加噪声的过程中,刚开始是清晰图片,所以噪声添加的较少,而后,随着图片变得模糊,也逐步增加了添加噪声的强度(方差)。
论文中 “线性调度” 模式做了如下设计:
$$
x_t = \sqrt{1 – \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) \tag{1}
$$这里的 \(\beta_t \) 是一个随着时间序列推进逐渐增大的值,从而在迭代过程中(或者说这个马尔科夫链中),逐步增加噪声在图片中的影响。论文中,\(\beta_t \) 是一个线性变换的序列,从 \(10^{-4} \),通过1000步迭代,增加到\(0.02 \)。
2.2 计算的“简化”
上述的“公式(1)”是一个迭代计算的“数列”(或者说是“马尔科夫链”),在实际的计算中,会经常使用如下的“通项公式”计算上述的迭代“数列”:
$$
x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon \quad \epsilon \sim \mathcal{N}(0,1) \\
\text{Where} \quad \alpha_t := 1-\beta_t ,\, \bar{\alpha}_t = \prod_{s=1}^{t}\alpha_s \tag{2}
$$关于详细的如何从“公式(1)”严格的推导到上述表达式(2),参考本文小结“4.5 “调度公式”的推导”。
上述的表达式,在论文中出现的形式则是:
$$
q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}}x_0,(1-\bar{\alpha_t}\mathbf{I}) ) \tag{3}
$$这里的“公式(2)、(3)”所表达的意思是等价的。简单的说明:
- (a) \(\mathcal{N}(x; \mu \, , \sigma^2) \) 表示正态分布的随机变量 \(x \),均值为\(\mu \) 方差为 \(\sigma^2 \)
- (b) 上述的表达式中的 \(I \) 表示单位矩阵。这是因为公式中的 \(x_t \) 是一个表示所有像素值的向量(例如,128×128的向量,即可能有16384个随机变量),\(I \) 表示协方差矩阵是一个对角矩阵,即所有随机变量都是完全独立的。
3. 代码实现
完整的代码参考:Forward-Diffusion-Process.ipynb.ipynb
3.1 读取并预处理图片
该函数输入原始图片、迭代次数、初始噪声,即 (x_0, t,noise) 。原始图片在读取后,需要做几个处理:
- 统一 Resize 到 128 x 128 像素来出来
- 按 RGB 三通道转成一个 1 x 3 x 128 x 128 的张量/数组
- 像素值从 [0, 255] 的整数缩放到 [0.0, 1.0] 的浮点数
对应代码:
# 3. 加载测试图片 url = "https://www.orczhou.com/wp-content/uploads/2025/12/IMG_1710-scaled.jpg" img = Image.open(requests.get(url, stream=True).raw).convert("RGB") transform = transforms.Compose([transforms.Resize((128, 128)), transforms.ToTensor()]) x_0 = transform(img).unsqueeze(0) # 变为 (1, 3, 128, 128)3.2 生成随机噪声
生成一个随机按 \(N(0,1) \) 分布的对象,与上述图片相同,即:1 x 3 x 128 x 128
noise = torch.randn_like(x_0) # 采样纯噪声 epsilon3.3 原始图片叠加噪声
噪声的叠加并不是简单的直接相加( \(x_0 + \text{noise} \) ),而是一个迭代式的,并考虑原始图片影响的方式(线性采样考虑):
$$
\begin{aligned}
x_t &= \sqrt{1 – \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) \\[0.5em]
x_t &= \sqrt{\bar{\alpha}} x_0 + \sqrt{1-\bar{\alpha}}\epsilon
\end{aligned}
$$4. 公式(1)的说明
我们再来看看 “公式(1)” 的设计:
$$
x_t = \sqrt{1 – \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) \tag{1}
$$为什么不用最为直观、自然的 \(1-\beta_t \) 与 \(\beta_t \) 作为上述表达式中的系数,而是使用了他们的平方根?
这个“设计”思路的根源是因为:高斯分布乘以一个常数后,其方差则为该常数的平方再乘以原来的方差。即: \(X \sim \mathcal{N}(\mu,\sigma^2) \),那么 \(aX \sim \mathcal{N}(a\mu,a^2\sigma^2) \)。
整体上,考虑是希望在传播过程中,方差不要偏离太大。并且随着时间的推进,最终的数值是一个标准正态分布的,如果来看推迟到出来的“公式3”:
$$
q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}}x_0,(1-\bar{\alpha_t})\mathbf{I}) \tag{3}
$$可以看到在这样的“设计”(即使用“根号”)下,最终迭代的\(x_t \) 的均值是 \(\sqrt{\bar{\alpha}}x_0 \),方差为 \(1-\bar{\alpha_t} \),随着\(t \)的增加,就逐步趋向于 \(\mathcal{N}(0,1) \)了。
5. 一些数学公式与推导

Diffusion 相关的数学基础还是非常、非常复杂的,而这里的公式推导看起来虽然有点复杂,但可能是整个Diffusion模型的数学基础中最为简单的部分了。这里,勉强祭出右边的图片。
我们这里还是来做一些尝试吧。
5.1 Forward Diffusion Process 公式
$$x_t = \sqrt{1 – \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) \tag{1} $$
这个公式本身已经有一定的复杂度了,要搞清楚大概需要关注如下点:
- 这里的 \(\epsilon \) 是什么意思
- \(\beta_t \) 的计算设计
- 从“迭代公式(1)”到“通项公式(2)”
5.2 唬人的 \(\epsilon \)
多维变量的概率已经忘得差不多了…,好在这里是一些完全“独立”的随机变量,还比较好理解。我们先看看这里的: \(\epsilon \sim \mathcal{N}(0, \mathbf{I}) \)。
第一次看到这些个符号的时候,也是被“怔”了一下的,仔细一看还好。
首先,这里公式中的 \(x_t \) 是一张图片所有的像素信息,例如,如果是一张 128×128 的图片,那么所有的像素信息则是一个长度为 1 x 3 x 128 x 128 的向量。即,\(x_t \) 是一个 3 x 128 x 128 的向量。
对应的,这里的 \(\epsilon \) 也是一个这样的向量(例如, 3 x 128 x 128 的向量,而不是数学中常见的表示一个很小的值),可以这样理解,这个向量的每一个取值都是一个随机变量(例如一共 3 x 128 x 128 个随机变量),每一个随机变量都是独立的,即协方差矩阵为单位矩阵(这里的 \(\mathbf{I} \)),并且每个随机变量符合标准正态分布,即 \(\mathcal{N}(0, 1) \)。
再回头看看原公式,是不是简单了很多:
$$x_t = \sqrt{1 – \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) $$
5.3 线性调度
再来看公式中的 \(\beta_{t} \):
$$x_t = \sqrt{1 – \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}) $$
在原始的 Denoising Diffusion Probabilistic Models 论文中,取值如下:\( \beta_1 = 10^{-4} ,\, \beta_{T} = 0.02 \),即均匀线性的在1000次噪声添加中,\(\beta \)均匀的从\(0.0001 \) 增长到 \(0.02 \),即:
$$ \beta_1 = 0.0001, \beta_2 = 0.0001199, \beta_3 = 0.0001398 , … , \beta_{1000} = 0.02 $$
在 Python 中就是如下代码:
T = 1000 # 总步数 betas = torch.linspace(0.0001, 0.02, T) # 线性调度:噪声方差逐渐增大5.4 “线性调度”的真实计算式
但是,在实际的运算不会用上面的公式。而是,使用了这个版本的推导,从而更加高效,更加直觉,同时,看起来更加“抽象”,即在论文中的如下公式:
$$ q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}}x_0,(1-\bar{\alpha_t}\mathbf{I}) ) \tag{3}$$
这个版本看起来就很“唬人” ,但理解了其意思还是感觉比较“简洁”的,再理解之后,就觉得也还比较“简单”。
本质上,这公式是前面“公式(1)”的推导与快速计算版本,该公式提供了一个无需迭代计算,而直接根据\(x_0 \) 计算 \(x_t \) 的方法。其中的 \(\alpha_t := 1-\beta_t ,\, \bar{\alpha}_t = \prod_{s=1}^{t}\alpha_s \) 。
5.5 “调度公式”的推导
这里来尝试做一下“公式(1)”到“公式(2)”的推导,尝试理解以下研究者们这部分工作(也可以参考这里:Diffusion Models: A Mathematical Introduction的第14页)。
$$
\begin{aligned}
x_t &= \sqrt{1 – \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon \\[0.5em]
x_{t-1} &= \sqrt{1 – \beta_{t-1}} x_{t-2} + \sqrt{\beta_{t-1}} \epsilon \\[0.5em]
x_{t-2} &= \sqrt{1 – \beta_{t-2}} x_{t-3} + \sqrt{\beta_{t-2}} \epsilon \\[0.5em]
\quad &\vdots & \\[0.5em]
x_{1} &= \sqrt{1 – \beta_{1}} x_{0} + \sqrt{\beta_{1}} \epsilon \\[0.5em]
\end{aligned}
$$所以:
$$
\begin{aligned}
x_t &= \sqrt{1 – \beta_t} (\sqrt{1 – \beta_{t-1}} x_{t-2} + \sqrt{\beta_{t-1}} \epsilon) + \sqrt{\beta_t} \epsilon \\[0.5em]
&= ( \sqrt{1 – \beta_t}\sqrt{1 – \beta_{t-1}} )x_{t-2} + ( \sqrt{1 – \beta_t}\sqrt{\beta_{t-1}} )\epsilon + \sqrt{\beta_t} \epsilon
\end{aligned} \tag{4}
$$接下去看看上面等式的后面两部分:
$$ ( \sqrt{1 – \beta_t}\sqrt{\beta_{t-1}} )\epsilon + \sqrt{\beta_t} \epsilon \tag{5}$$
这里并不是简单的加法,而是两个独立概率分布的加法:如果概率基础还在的话,就有如下的公式,两个独立的高斯分布(例如:\(X \sim \mathcal{N} (\mu_X ,\sigma^2_X ) \quad Y \sim \mathcal{N} (\mu_Y ,\sigma^2_Y ) \))的随机变量之和,其结果依旧是高斯分布,并且均值依据是两个均值的和、方差也是两个方差的和( \(X+Y \sim \mathcal{N} (\mu_X + \mu_Y ,\sigma^2_X + \sigma^2_Y ) \) )。
注意上面的表示 \(\sqrt{\beta_t}\epsilon \) 中,\(\sqrt{\beta_t} \) 是标准差,方差即 \(\beta_t \)。
所以上面“公式(5)”两个分布的和,依旧是高斯分布,且均值依旧是 0,方差则为 \((1-\beta_t)\beta_{t-1}+\beta_t \),即有了如下看似错误的,但是却是正确的推导:
$$
( \sqrt{1 – \beta_t}\sqrt{\beta_{t-1}} )\epsilon + \sqrt{\beta_t} \epsilon = \sqrt{(1-\beta_t)\beta_{t-1}+\beta_t} \epsilon
$$其实上面并不是一个一般意义的“等式”,而是表达了如下的含义:
$$
( \sqrt{1 – \beta_t}\sqrt{\beta_{t-1}} )\epsilon + \sqrt{\beta_t} \epsilon \sim \mathcal{N}(0,(1-\beta_t)\beta_{t-1}+\beta_t)
$$有了这里的理解,就以继续上面公式(4)的推导就非常容易有如下的结论了:
$$
\begin{aligned}
x_t &= \sqrt{1 – \beta_t} (\sqrt{1 – \beta_{t-1}} x_{t-2} + \sqrt{\beta_{t-1}} \epsilon) + \sqrt{\beta_t} \epsilon \\[0.5em]
&= ( \sqrt{1 – \beta_t}\sqrt{1 – \beta_{t-1}} )x_{t-2} + ( \sqrt{1 – \beta_t}\sqrt{\beta_{t-1}} )\epsilon + \sqrt{\beta_t} \epsilon \\[0.5em]
&= \sqrt{\alpha_t\alpha_{t-1}}x_{t-2} + \sqrt{1-\alpha_t\alpha_{t-1}} \epsilon \\[0.5em]
&\vdots \\[0.5em]
&=\sqrt{\alpha_t\alpha_{t-1}\cdots\alpha_1}x_{0} + \sqrt{1-\alpha_t\alpha_{t-1}\cdots\alpha_{1}} \epsilon \\[0.5em]
&= \sqrt{\bar{\alpha_t}}x_0 + \sqrt{1-\bar{\alpha_t}} \epsilon \\[0.5em]
\text{where}\, \alpha_t &:= 1-\beta_t ,\, \bar{\alpha_t} = \prod_{s=1}^{t}\alpha_s
\end{aligned}
$$即有了最终的公式:
$$
x_t = \sqrt{\bar{\alpha_t}}x_0 + \sqrt{1-\bar{\alpha_t}} \epsilon \\
\text{where}\, \alpha_t := 1-\beta_t ,\, \bar{\alpha_t} = \prod_{s=1}^{t}\alpha_s
$$5.6 在Python中的实现
了解了上面这些,再看这些代码就很简单了:
T = 1000 # 总步数 betas = torch.linspace(0.0001, 0.02, T) # 线性调度:噪声方差逐渐增大 # 计算中间变量 alphas = 1. - betas alphas_cumprod = torch.cumprod(alphas, axis=0) # 对应公式中的 alpha_bar以及最后的 Forward Diffusion Process 计算:
sqrt_alphas_cumprod_t = torch.sqrt(alphas_cumprod[t]) # 信号系数 sqrt_one_minus_alphas_cumprod_t = torch.sqrt(1. - alphas_cumprod[t]) # 噪声系数 # 核心公式实现 return sqrt_alphas_cumprod_t * x_0 + sqrt_one_minus_alphas_cumprod_t * noise, noise6. 微分方程角度的考虑
从随机微分方程的角度考虑 “DDPM” 模型是该模型发布之后的事情了,我们这里先看看这个随机微分方程的“漂移/Drift”部分与上述迭代式子的关系。
先不考虑“随机项”的增加,那么在设计时,希望随着时间步骤的迭代,变化的速率逐渐增加,即迁移变化慢,后期变化快,即考虑在微分方程的右侧增加一下 \(\beta(t) \),该函数随着时间增加而增加,最为常见的即为线性增长(对应于“线性调度”)。此外,该变化率应该与当前值有关,当前值越大,则变化率应该越大;并且期望最终迭代结果趋向于零(即均值最终为零的正态分布),就有最终的微分方程设计:
$$ \frac{dx}{dt} = -\frac{1}{2}\beta(t)x \tag{5} $$
说明:
- 方程右侧的负号,表示总是朝着x取值相反的方向移动,即总是朝着原点方向移动
- \(\beta(t)x \)则表达了上述的两个关于“变化率”大小的意图
该微分方程的迭代解就有如下的迭代表达式:
$$
\begin{aligned}
&x_{t} – x_{t-1} = -\frac{1}{2}\beta(t)x_{t-1} \\[0.5em]
&x_{t} = x_{t-1} -\frac{1}{2}\beta(t)x_{t-1} \\[0.5em]
&x_{t} = (1 -\frac{1}{2}\beta(t))x_{t-1} \\[0.5em]
\end{aligned}
$$很神奇的是,在\(\beta \)很小的时候,根据泰勒展开有:
$$
\sqrt{1-\beta} = 1 – \frac{1}{2}\beta – \frac{1}{8}\beta^2 + \cdots
$$最终就有:
$$
x_{t} = \sqrt{1-\beta_t}x_{t-1}
$$这里就可以从“微分方程”的角度去理解上述的 stable diffusion 中 Forward Diffusion Process 中前半部分了。
7. 小结 FDP
在了解 What 中,也在慢慢理解 How 以及Why 。这里再次从宏观上概述 FDP 的过程,从而跳出上述的 What 细节,再次审视这个过程。
7.1 首先,为什么需要 “Forward Diffusion Process” ?
简单回答:给样本添加噪声,构建训练数据。
“Forward Diffusion Process” 过程的数据主要用于训练,对于一个给定的图片,逐步添加噪声,最后让其变成一张纯粹的、高斯分布的噪声。而这个过程的数据,则可以用于训练 U-Net 的神经网络,让该U-Net具备一个神奇的能力:即给出一张图片(带有噪声的),该 U-Net 可以预测出这张图片中有哪些是噪声。
7.2 “Forward Diffusion Process” 操作的数学计算
其核心公式如下:
$$
x_t = \sqrt{1 – \beta_t} x_{t-1} + \sqrt{\beta_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I})
$$经过推导,等价与如下公式(关于公式的推导:Forward Diffusion Process):
$$
x_t = \sqrt{\bar{\alpha_t}} x_0 + \sqrt{1-\bar{\alpha_t}}\epsilon \quad \epsilon \sim \mathcal{N}(0,1) \\
\text{Where} \quad \alpha_t := 1-\beta_t ,\, \bar{\alpha_t} = \prod_{s=1}^{t}\alpha_s \tag{a}
$$在论文中可能看到的形式:
$$
q(x_t|x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}}x_0,(1-\bar{\alpha_t}\mathbf{I}) )
$$对于一张照片实际做上述操作则有如下效果:
关于上述公式的一些重要特性:
- 经过若干次迭代后,一张清晰的图片最终变成一张“随机”噪声图片,这里的“随机”是指的正态分布
- 从“公式(a)”可以看到,逐步迭代和多步合并迭代有一样的效果。当然,为了获得训练数据,总是逐步迭代
-

到目前为止,前面的线性方程组的解,还有一些问题没有彻底回答(例如,解空间的描述),在回答这个问题之前,我们需要先了解一下“向量空间”。“向量空间”的严格定义是有些枯燥的,这里暂时把“向量空间”的限制为大家所熟悉的、最为典型的“ \(n \) 维欧氏空间”。
目录
1. 向量空间
1.1 基
要描述一个向量空间中的元素,则首先需要一组基(坐标)。在\(n\)维欧氏空间,最为常见的一组基,即为多个“垂直”(“正交”)的单位向量,即:
$$ \begin{align}
\alpha_1 &= (1,0,\dots) \\
& \vdots \\
\alpha_i &= (\dots,0,1,0,\dots) \\
& \vdots \\
\alpha_n &= (0,\dots,1)
\end{align}
$$在二维平面空间中,则为:\( \alpha_1 = (1,0) \quad \alpha_2 = (0,1)\);三维空间则为:\( \alpha_1 = (1,0,0) \quad \alpha_2 = (0,1,0) \quad \alpha_3 = (0,0,1)\)。
既然有“正交”基,那么当然有不那么“正交”的基,而此类“基”则是更为普遍的。事实上,更为普遍的,任何 \( n \) 个线性无关的向量都可以作为向量空间的基。
1.2 线性相关与线性无关
考虑一组向量\( \alpha_1,\dots , \alpha_n \),如果当且仅当所有\( a_i = 0 \quad i=1,\dots,n\)时如下的等式才成立:
$$ a_1\alpha_1 + a_2\alpha_2 + \dots + a_n\alpha_n = 0 $$
那么,就说 这组向量 \( \alpha_1,\dots , \alpha_n \) 是线性无关的。反之,则称这组向量是线性相关的。
或者这么说,对于一组线性无关的向量\( \alpha_1,\dots , \alpha_n \):任何一个向量都不能用剩余的向量做“线性表示”。
1.3 一些重要的结论
结论:设\( \{ \alpha_1,\dots , \alpha_n \}\)是向量空间\( V \)的一组基,那么\( V \)空间中的每一个向量都可以唯一的表示为这组基的线性组合。这个线性组合的系数,就叫“坐标”(注:相对于这组基)。
结论:\( W_1 \)、\( W_2 \)是\( V \)的有限子空间,那么有:
$$ dim(W_1+W_2) = dim(W_1) + dim(W_2) – dim(W_1\cap W_2) $$
结论:\( n \)维向量空间中,任意\( n \)个线性无关的向量都可以取做基。
2. 线性变换与矩阵
2.1 概述
“线性变换”是指向量空间中一类特殊的映射 \( \sigma : R^n \to R^m \) ,需要满足条件是:
- \( \sigma(\xi + \eta) = \sigma(\xi) + \sigma(\eta) \)
- \( \sigma(a\xi) = a\sigma(\xi) \)
“线性变换” 描述了向量空间之间的映射。后续所有的内容大概都是围绕此而展开,后续所有的内容都会尝试通过各种方式将 “线性变换” 的特性研究清楚。这里写出部分结论,后面再慢慢展开:
- 线性变换之下,原点保持不变。即 \( \sigma( \vec{0} ) = \vec{0} \)
- 几何意义下,通常,线性变换包括了:旋转、镜像、拉伸/压缩(特别的,有时候会压缩到零)、剪切
为了研究清楚一个线性变换上述的特点,通常需要选取一组“基”,然后使用这组“基”的“坐标”来描述空间中的点,进而再描述对应的线性变换。最为常见的基为“正交单位基”。
从方法上来看,研究清楚“线性变换”最为关键的是研究清楚对应的“变换矩阵”。所以,“线性代数”的核心后面就变成了对矩阵特性的研究,但是,也不要忘记了初衷,否则很快就迷失了。
2.2 线性变换
我在大学期间对于线性变换、矩阵有什么作用,是完全没有概念的。所以对于他们的特性研究也没有掌握的很深,基本上是停留在能够把一些联系题做对这个层面。而现在,注意线性变换的广泛应用之后,尝试去理解去本质之后,就会寻根问底的去理解清楚什么是线性变换、什么是矩阵。这里再次说说我的理解。
在一个向量空间中,最为常见的是 \(n \) 维欧氏空间,会有很多的向量,例如每个 Embedding 就可以理解是在一个线性空间中,“线性变换”表述了是空间中的一类映射,该映射满足上述“小结2.1”中的两个要求,即原点依旧到原点、映射保持所谓的“线性”(例如,向量和的映射等于映射的和等)。
在一个向量空间中,一个线性变换就是一个符合一定条件的映射。与向量空间的基的选取是没有关系的。自此,与矩阵也是没有关系的。所以,线性变换本身是更为底层、更为基础的概念。
2.3 欧氏空间的线性变换与矩阵
现在我们把问题限定在 \(n \) 维欧氏空间中。那么,这时候,我们如何描述一个线性变换呢?是的,就是“基”与“矩阵”。
通常,\(n \) 维欧氏空间,我们会先选取一组基,然后使用一个矩阵去描述这个线性变换。并且非常幸运的,一旦这组基 选定了,这个矩阵是唯一的。
结论:在\(n \) 维欧氏空间(这个条件似乎可以去掉)中,对于线性变换 \(\sigma \),如果选定一组“基”,那么就存在唯一的“矩阵”描述该线性变换。
上述的结论,是比较明显的。我们考虑对于线性变换中的上述选定的基向量 \(\alpha_i,\quad \text{where } i = 1,\ldots,n \),线性变换将其映射到 \(\beta_i,\quad \text{where } i = 1,\ldots,n \),那么根据“基”的基本性质,对于这里的任何 \(\beta_i \)都可以表示成\(\alpha_i \)的线性组合,所有的这些系数构成的矩阵,就是上述描述的唯一的“矩阵”。具体的:
$$
\begin{aligned}
\beta_1 &= a_{11}\alpha_1 + a_{21}\alpha_2 + \cdots + a_{n1}\alpha_n \\[0.5em]
\beta_2 &= a_{12}\alpha_1 + a_{22}\alpha_2 + \cdots + a_{n2}\alpha_n \\[0.5em]
&\ \vdots \\[0.5em]
\beta_n &= a_{1n}\alpha_1 + a_{2n}\alpha_2 + \cdots + a_{nn}\alpha_n
\end{aligned}
$$即:
$$
\begin{aligned}
\begin{bmatrix}
\beta_1 & \beta_2 & \cdots & \beta_n
\end{bmatrix}
=
\begin{bmatrix}
\alpha_1 & \alpha_2 & \cdots & \alpha_n
\end{bmatrix}
\begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\end{aligned}
$$即在这个线性变换\(\sigma \) 在选定基 \(\alpha_i,\quad \text{where } i = 1,\ldots,n \) 对应的矩阵为:
$$
\begin{aligned}
A =
\begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\end{aligned}
$$从这段简洁的“证明”(或“说明”)来看,我们很自然有如下结论,根据空间中的“基”的选取不同,我们会得到不同的矩阵。因为我们反复会提到,我们经常会通过研究矩阵的特性来研究线性变换。那么,同一个线性变换在不同的“基”下的不同“矩阵”,很自然的能够想到,这些“矩阵”是有某些共性的,是的,我们称这些矩阵为“相似矩阵”,相关特性,暂不展开。
3. 特征向量与特征值
3.1 为什么
为什么我们需要关注“特征值与特征向量”呢?为什么我们要去了解奇异值分解(SVD)呢?
原因是“线性变换”是一个映射,是非常抽象的。而特征值 、特征向量、SVD分解可以把线性变换最为关键的特性,以非常“直观”的形式表达出来。当然,这里的“直观”并不是简单意义上能够一眼就看出什么来,事实上,“线性变换”本身就有很强的抽象性,这里的“直观”只是相对的,是否直观,完全依赖于各位看客自己的“悟性”了 。
特征向量的基本定义:如果有 \( \sigma(\xi) = \lambda \xi \) ,那么这里的 \( \xi \) 就是特征向量,对应的 \(\lambda \) 就是对应的特征值。
要想真正说清楚特征向量与特征值是需要非常多篇幅的,而且关于对特征向量的理解对于理解线性变化也是非常关键的,所以,建议花些时间较为系统的做一些理解。如果你已经建立的基础概念,这里的一篇文章可能是帮助你增强一些理解:特征向量与特征值。
3.2 关于对特征向量的理解
完整的讨论特征向量与特征值是复杂的,这里将其限定在一些较为简单的情况,作为一个入门。我们这里考虑最为简单的情况,即对于一个 \(n \times n \)的矩阵,其秩为 \(n \),并且在计算特征值时,有 \(n \) 是不重复的实数解,即没有任何根式重根。如果,恰好 \( n = 2 \)这大概是最为简单的情况了,不过理解这种情况,再进一步拓展,则学习曲线会平滑很多。
我们来看一个实例,在二维空间中,在标准基下,我们有如下的线性变换矩阵:
$$
W = \begin{bmatrix}
2 & 1 \\
1 & 2
\end{bmatrix}
$$根据上述特征向量特征值的定义进行求解,我们可以有如下的特征值与特征向量:
- \( \lambda_1 = 3 \) 特征向量 \( (1,1) \)
- \( \lambda_2 = 1 \) 特性向量 \( (-1,1) \)
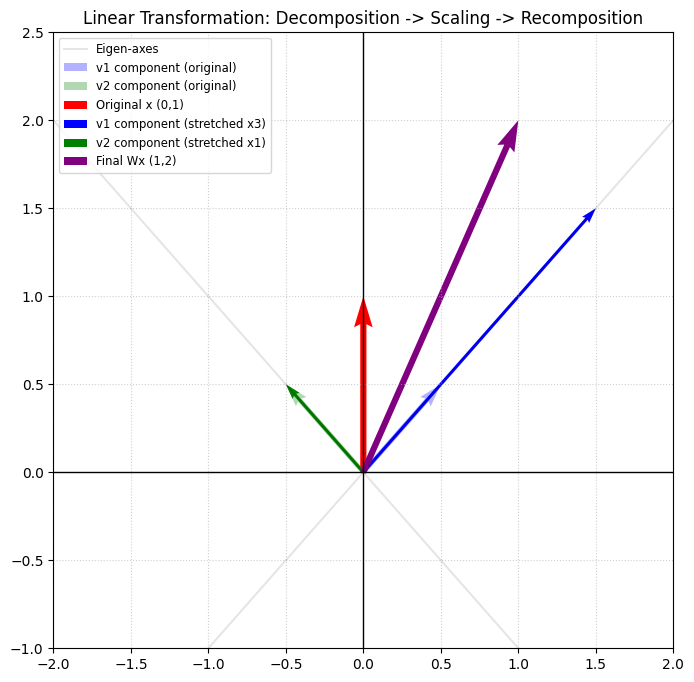
从特征向量角度理解线性变换:那么上述的矩阵A对应的线性变换 \(\sigma \) 有如下特性,在这个二维空间任何向量 \(\beta \),都可以分解(投影)为上述两个特征向量方向的向量: \(\beta_1 \,, \beta_2 \),且有:\(\beta = \beta_1 + \beta_2 \)。那么,则有:\(\sigma(\beta) = \lambda_1 \beta_1 + \lambda_2 \beta_2 \)。即,这个线性变换可以这样描述:先将任何向量沿着特征向量方向分解,然后再按照特征值的大小进行拉伸或压缩,然后再把向量合并起来。
上述的解释,可以对照着右图去理解。特征向量分别为 \((1,1) \) 和 \((-1,1) \) ,即图中浅绿色、浅蓝色方向。该矩阵作用在向量 \((0,1) \) 上,即图中的红色向量。先将红色向量沿着浅绿色、浅蓝色方向分解,然后按照特征值进行拉伸,即图中的绿色、蓝色向量,最后合并为图中的紫色最终向量。
上述的场景是线性变换中,最为简单的一类。而实际的线性变换,则更为复杂,可能还涉及到对于向量的旋转、镜像、剪切等变换。关于更多场景可以自己探索,或者阅读相关书籍,也可以看看这篇文章中的更多直观的例子:特征值与特征向量。
“特征向量”可以很好的帮助理解“方阵”变换,还有一类变换时非方阵的情况,通常这时候可以借助于奇异值分解的方式去理解,关于奇异值分解可以参考:奇异值分解–深度学习的数学基础。
4. 最后
初等的线性代数核心部分大概是这些内容,出于完整性的考虑,可以再进一步了解“Jordan 块”相关的内容,从而把相关理论补充完整,这里不再详述。
如果再回到最初的线性方程组解的问题,我们这里就可以回答最后一个问题:对于一个线性方程组,如果有解,那么所有的解空间是怎样的?
结论:如果方程组的系数矩阵的秩为\( r \),那么解空间的维度为\( n-r \)。解空间的“基”则可以通过初等变换求得。这里不再详述。
-
通史阅读:隋与唐
·

起初读历史总还是带着一些功利心的,总是想着这些知识能有些什么用处。读着读着,发现了解这些历史本身就是有趣的、愉快的,虽然有时候也觉得很沉重,完全不用有什么功利心。读着读着,也有一些所思、所想,所以也就记录下来,存放于此。
目录
1. 底层英雄与数代积累
隋、唐两个王朝家族都与“北魏”(包括北齐、北周)有着非常大的关系。杨坚之父杨忠,为西魏/北周建国“十二将军”将军之一;李渊祖父李虎为“西魏八大柱国”之一,都是当时极其显赫的家族。
北朝统治者都是鲜卑人,而当时在中国北部的汉人“胡化”也非常深,杨坚、李渊家族也都有各自的鲜卑姓氏,分别是“普六茹”和“大野氏”。
有少部分是底层“英雄”振臂一呼“王侯将相宁有种乎”后揭竿而起,但更多的王朝迭代都是数代人的积累后,再加上天时地利与人和,隋、唐的建立就是典型代表。隋文帝其父杨忠已经是北周重臣,其女则是北周宣帝宇文赟的皇后,其妻为西魏“八柱国”之一独孤信之女独孤伽罗,“禅让”皇位给杨坚的北周静帝即为宇文赟之子(注:并不杨坚之女所生)。
而后续的唐替隋也有一些类似。唐高祖李渊的祖父李虎,与当时的宇文泰、独孤信、李弼等同为西魏八柱国,后李虎追随宇文泰一起建立北周,对抗北齐高欢集团。而当时的隋炀帝杨广则是李渊的姨表亲(注:李渊父取独孤信四女;杨坚取独孤信七女)。
历史上,真正完全从底层如爽文般一路打拼成就帝业的是非常少,比较有名的大概就是汉高祖、明太祖、北齐高欢、后赵石勒等。大多数王朝或割据政权的建立,则都是历经数代人的累计。
2. 王朝的建立之初的平乱
一般王朝多建立于乱世,而在王朝建立之初,多半都需要平定各地分散的势力,才能最终建立统一的、稳固的王朝统治,隋初、唐初都有类似的局面。杨坚在拥立北周静帝时,平定了相州、郧州、益州等地叛乱;而后经“禅让”自立,先是北御突厥,待北方略微安定,再南征陈朝,最后与589年灭陈。至此,才真正建立的大一统的“隋”。
而唐初局面也非常混乱。在李渊最初控制了长安之后,全国局势依旧非常混乱。北边突厥异常强大,洛阳则有王世充、河北有窦建德、另外还有实力强大的瓦岗军(翟让/李密/秦琼/程咬金等)等。最终,直到唐武德七年,全国才全部统一。而在完全统一后的两年,就发生了改变历史进程的“玄武门之变”。
3. 总出问题的“国本”
帝王的继承问题,历来都是难以解决的“困局”。隋、唐两朝在初代都出现了比较严重的国本之“战”。隋文帝起初虽然立长子杨勇,但后来受多方影响,废杨勇,而改立杨广。而杨广很快矫召赐死杨勇(“矫称高祖之诏,赐故太子勇死,缢杀之” 资治通鉴/卷180)。
而唐初的“玄武门之变”则震惊历代看客,期间李世民射杀兄弟、逼迫其父退位。之后,太宗一朝虽然政治清明,制度逐渐完善,社会相对进入一段安定时期,并且太宗作为君主确实有非常多的了不起的地方(尤其是在宽宏用人这个方面),但,“玄武门之变”对于人伦观念的摧残,对后世影响大概是巨大的。在“后武则天”时代,李隆基诛杀安乐公主(堂妹),而后又诛杀太平公主(姑姑),最终掌权,开创“开元盛世”。帝王之家的人伦、亲情,大概不能用常理去理解吧。
4. 关于历史真实性的问题
理科生读历史大概总是比较较真,总会问出“这些事情都是真的吗?”。诸如鸿门宴的时候,并无外人在场,但“史记”却写得如此生动。所以,这些历史都是真的吗?
4.1 附会
关于这个问题并没有一个简单的回答。因为无论回答是什么,都没有人能够像“理科”一样去证明、或者去通过重复试验验证。但,学者们对此是有共识的。在读吕思勉的《中国通史》、《三国史话》时,印象最深的一词大概就是“附会”。例如:
《三国志》上所说的兵谋,大都是靠不住的。这大约因军机秘密,局外人不得而知,事后揣测,多系附会之谈,而做历史的人所听见的,也不过是这一类的话之故。
吕思勉 《三国史话 袁绍和曹操的战争》历史上的重大事件,多半都是真实发生过的,因为大事件经常会有多方记载,可以相互印证。再者,对于大的事件,因为知晓的人太多,即便是当权者也通常难以抹除。但,“篡改”、“重新构建”、丑化前朝、美化当朝则是经常有的,甚至是某种常态。
4.2 贞观君臣的史实构建
至于,大事件中的各种细节,则需要甄别,可能经过一些有意无意的修改或者“重构”,这是非常常见的。在看此类内容时,则通常需要考虑多方印证、编写者的时代、编写者的立场、甚至性格等综合因素去做一些“猜测”或“揣摩”。
例如,“玄武门之变”这场政变本身的记录是无法修改,但是关于这个事件的“叙事”史实的记录中大概是“真正假假”的,需要非常专业的甄别。关于这一点可以参考西北大学历史学院院长李军的一次在线分享《玄武门之变的真相与贞观君臣的史实建构》。从这个示例中,可以看到史官如何系统的、“精细”的“修改”历史,以满足当朝者的意志。
4.3 李渊的“久畜叛志”
… 突厥来侵,李渊遣军拒之,未能取胜,深恐获罪。于是世民等乘机劝渊举事,经过屡次的催促,他才决心采取行动。这是李渊起兵最通行的说法,但从若干史事的迹象看来,李渊本人可能是这次起兵的发动着,他富于才略,久畜叛志,世民只是为其效力建功而已[ 参看唐温大雅《大唐创业起居注》,罗香林《大唐创业起居注》考证(载罗著《唐代文化史研究》),李树桐《李唐太原起义考实》(载《大陆杂志》六卷十期及十一期) ]…
傅乐成 《中国通史》 p335/336傅乐成认为在后续的历史资料中,为了强调李世民“夺位”的“合法性”,有意夸大了李世民在起兵中的作用。而这种“修改”、“构建”在历史记录中大概是非常常见。
5. 胡汉血统
中国非常大,南北差异也非常大,民族融合问题在很多朝代都有着各种挑战,即便是在当代,也时有类似问题出现。
但从历史角度来看,这些问题有时候是比较奇怪的。现在中国人,有时候会被称作“唐人”,而海外更是很多的国家都以“唐人街”命名中国人聚集的地方。现在的中国人,也一般都以唐朝的强盛而自豪。但是,简单的从“血统”来说,李世民可能有非常多的鲜卑族的“血统”。至少,其母亲太穆皇后窦氏为鲜卑人、其祖母独孤氏也是鲜卑人。如果再算到唐高宗李治,因为其母是长孙皇后也是鲜卑人,其血统的鲜卑成分可能就更高了。
历史上,唐太宗李世民除了称皇帝外,也称“天可汗”,即其不仅是中原之首,也是周边一众其他民族之首。
所以,“胡汉”自很早以前,其界限就不再清晰了。更不用说,自北魏孝文帝以来,胡汉已经很大程度在进行融合,鲜卑人很可能也融合了很多的汉人的血统。如果要简单的从家族去论“胡汉”早就已经不太成立了。如果真的要较真的话,则大概只能去看“生物”(DNA)层面。
6. 武周与李唐
在看这段历史时,最错愕的大概是,武则天在处理“杀伐废立”时的果断,竟如历代“君王”一般,在消灭异己、拉拢人心、政事执行上,也显得娴熟老练。后续大概还想再细读一下武则天的一生,到底是怎样的早年经历或者成长环境,催生出如此人性如此冷酷、果决的一面。
起初,被唐高宗皇后王氏引入,以对抗萧淑妃。在武则天获宠之后,很快就借机以“谋行鸩毒”废王皇后与萧淑妃(“谋行鸩毒,废为庶人,母及兄弟,并除名,流岭南”),并最终杀害之。在废王皇后之后,武则天也很快被册立为皇后(临轩命司空李x继玺绶册皇后武氏)。而当初曾经反对立其为后的重臣,如“长孙无忌、韩瑗、来济、褚遂良”都被流放、贬官或赐死。而后来,高宗有一些厌恶武后的专权(“初,武后得志,遂牵制帝,专威福,帝不能堪”),有意废后的时候,找到宰相上官仪商量,上官仪表示支持并说:“皇后专恣,海内失望,宜废之以顺人心。”(新唐书-上官列传)。上官仪后来也被杀,其子上官庭芝亦被杀,其孙女婉儿被“配掖廷”(新唐书-后妃列传-上官昭容)。在上官婉儿被重用后,上官仪才被追赠为“中书令、秦州都督、楚国公”。
高宗死后,中宗即位的,数月后,武则天即废中宗,改立李旦(即唐睿宗),自己则临朝称制,自专朝政。很快,武太后(此时为太后)就遇到了第一个“大”的考验–徐敬业等的反叛(当时骆宾王为此写了一篇千古檄文《为徐敬业讨武曌檄》),此叛虽然很快就平定了。但是,武太后大概意识到,在自己真正掌权的路上还会有很多的“挑战”。在接下来几年,重用了一众“酷吏”,又大开告密之门,从而借此大肆剪除异己。
很快,又发生了琅邪王李冲(太宗之孙)的叛乱、越王李贞(太宗之子、李冲之父)呼应。但两人都没有组织起真正的力量,叛乱很快被平。这次叛乱牵连的李氏诸王很多,包括迫“韩王李元嘉(高祖子)、鲁王李灵夔(高祖子)、黄国公李譔(高祖孙、李元嘉之子)、东莞郡公李茂融(高祖孙)、常乐公主(高祖之女)等”,多被赐死或自缢。
之后,很快武皇后便正式废睿宗而称帝(690年),在位15年,于神龙元年(705年)政变,禅位于中宗,武则天这时八十一岁,并于同年崩逝。
7. 唐玄宗、杨贵妃与安史之乱
在中国千百年的帝王制度之下,皇帝本身“质量”的优劣很大程度上决定了国家兴衰,而皇帝“质量”和普通人其实是一样的,时好时坏,更多的时候是平庸;也有的人可能年轻时很励精图治,年迈后则多贪图权势与享乐,这其实都是人之常情。

唐玄宗彻底结束了李唐王朝中“女强人”干政带来的不稳定因素,并且在其在位的中前期,能够任用贤臣,使得唐朝社会再次在安定中发展。虽然这里提到的“彻底结束”过程也是艰难的,先是诛“韦后”、“安乐公主”,后又灭“太平公主”,最后才真正掌权。玄宗在位44年,也因为其在位前期、后期完全不同的“历史形象”,所以经常会看到人感叹:如果玄宗少活几年,大概也是一位在历史上能够排名前几的明君了。
哎,“太平公主”是玄宗亲姑姑、“韦后”是他“婶婶”、“安乐公主”是他堂姐妹,不得不再次感叹自古帝王家的人伦之情与百姓之家是完全不同的。大概真的如韩非所言:“情非憎君也,利在君之死也”,可怕!
玄宗晚年宠信杨贵妃“一家”,任用李林甫、杨国忠,最终导致“安史之乱”。期间,李唐皇室之狼狈,前所未有!安禄山破潼关后入长安时,玄宗仓皇出逃,到马嵬驿经历短暂的兵变,杨贵妃被赐死。而后,太子李亨与玄宗分道,北上收拾残兵以抵御“安史”之乱。太子很快就自行在灵武宣布即帝位,是为唐肃宗,遥尊玄宗为太上皇。最后,因郭子仪等众将征伐,以及“安史”自身的内乱,最终叛乱被平。
乱虽然平了,但是自此地方藩镇势力割据、中央控制大大削弱,加上皇室内部宦官持续当权,也导致唐朝最后的一百多年多处藩镇“自治”之中(注:虽然在宪宗时期虽短暂终结藩镇割据)。
到唐末,先是小范围的“民变/兵变”,最终导致“大范围”民变(王仙芝与黄巢)与藩镇自立。此时的唐室中央政权早已羸弱不堪,最终,叛乱看似平定,但是留下的两大军事势力“沙陀李克用部”、“黄巢旧部降将朱温部”,以及一众不再受控制的地方藩镇势力。
而唐昭宗时期宰相崔胤,为灭宦官,召朱全忠(朱温)入关。宦官确实被成功消灭了,但是,也引狼入室,最终导致自己被杀,唐室也最终被朱温所灭。朱温建国为梁,中国也进入了地方自治的“五代十国时期”。
8. 再读唐诗
了解了这些,打算再读读自己以前背过的一些唐诗。《早发白帝城》、《长恨歌》、《春望》、《石壕吏》。
杜甫 《石壕吏》
暮投石壕村,有吏夜捉人。
老翁逾墙走,老妇出门看。
吏呼一何怒,妇啼一何苦。
听妇前致词:三男邺城戍,
一男附书至,二男新战死。
存者且偷生,死者长已矣。
室中更无人,惟有乳下孙。
有孙母未去,出入无完裙。
老妪力虽衰,请从吏夜归。
急应河阳役,犹得备晨炊。
夜久语声绝,如闻泣幽咽。
天明登前途,独与老翁别。杜甫的一生大概是颠沛流离的。这首诗写于杜甫在安史之乱“流离”期间,是其著名的“三吏三别”之一,也曾入选初高中的教材之中。
诗中,家中老翁为了躲避征军,暂且躲避,由老妪面对官吏。老妪的一家三个儿子都已经被征召,孙子尚小,家中已无人能够去服役,最后,老妪自己被征召,去给军队做饭。独留老翁一人,支撑支离破碎的家。
再读 “吏呼一何怒,妇啼一何苦”,仿佛能够听到 1200 年前,征军人员的凶狠,以及百姓的无奈。
杜甫 《春望》
国破山河在,城春草木深。
感时花溅泪,恨别鸟惊心。
烽火连三月,家书抵万金。
白头搔更短,浑欲不胜簪。这首诗写于安史之乱期间,当时叛军攻陷长安,玄宗幸蜀,杜甫“流离”陷于长安,写下此诗。
“国破山河在,城春草木深” 写的是景,述的是感伤。而其中“国破山河在” 一句更是为古今中外所赞叹(Sangaria)。
李白 《早发白帝城》
朝辞白帝彩云间,千里江陵一日还。
两岸猿声啼不住,轻舟已过万重山。安史之乱期间,永王(玄宗十六子)被认为谋反,而李白曾为永王幕僚而被牵连。后,李白并被流放夜郎。在押送到白帝城时,被收到被赦免的消息,故做《早发白帝城》。
了解这个背景,再读“轻舟已过万重山”,可以感受到当时,李白突然一身轻松的感觉。
-
新加坡之行
·
这次到新加坡在工作之余,也好好的了解了一下这个城市,如下一些随意的记录吧。
目录
花园城市“新加坡”
Rain Vortex@Changi Airport
一到新加坡樟宜机场(Changi Airport)就可以看到一个精心设计的壮观“室内瀑布”(the Rain Vortex):

the Merlion
此外,这次参加展会的地点是 Marina Bay Sands的Convention Centre,这里是新加坡地标式建筑“Merlion”所在地:

新加坡大概800年前被称为“Singapura”(马来语),意思是“lion city”,而更早之前,这里则是一个被称为“Temasek”的渔村。可以看到,“Merlion”的设计正是取自这两个名字所代表的意义。可以很好的代表这块土地过去千年的历史。
Gardens by the Bay
猜测,新加坡人的思路大概是,这个地方虽然不是很大,那我们就把这个缺点变成优点吧,于是,就把新加坡的每个地方都设计得非常精致。
在滨海湾花园(Gardens by the bay)这里,就非常精致。这里,有一个地方叫“Flower Dome”,里面摆满了来自世界各地的植物、鲜花;旁边是一个“Cloud Forest”,里面也有一个非常高的室内小瀑布,里面则是一个以“Jurrasic Park”和“Jurrasic World”为主题的展览。

关于“Singapore”名字的来历
“Singapore”一词来自于马来语的“Singapura[1]”,一把认为这个词语最初是来自梵文,意义为“Lion City”。
更为具体的,在梵文中,“Singa”来自梵文中的 siṃha (सिंह), 意思是 “lion”;而“pūra (पुर)” 意思为“city”,pūra也是很多印度地名非常常见的后缀(例如,Jaipur 斋浦尔)。
那新加坡于“lion”有什么关系呢?根据记载,大概在800年前,“Sang Nila Utama”来到这里,看到了疑似狮子的动物,故就将此地命名为“Singapura”,即“狮城”。至于到底当时看到的是不是狮子,现在已经不可考了,主流的看法似乎倾向于认为是其他的大型猫科动物。但,这个名字已经叫了800年了,故到底是什么动物,已经不再重要了。
在被叫为“Singapura”之前,这里是一个渔村,被称为“Temasek”,这词可能是来自马来语,表示“海边的地方”[1]。
“little india”
这次后面几天住的酒店是在“little india”区,这里保留了很多印度文化相关内容。比较有代表性的是“India Heritage Centre”,有点像一个“印度文化博物馆”,而最近正好是“Deepavali”节日前后,所以在这个“博物馆”的楼下,就有一些印度表演,虽然在电视上也看过一些印度舞蹈,但是现场看,感受还是非常不一样:

在“little india”区域中,另一个代表性的地方是一个叫“SRI Veeramakaliamman[2]”印度庙宇,这个神庙大约有150年的历史。

文化的异同
在新加坡众多感受之一是这里的“多元化”。在这里,多民族、多文化的融合做得非常好。
即便是在一个族群里面,人与人或者人群与人群的差异都是非常大的。更不用说,感受上,不同的族群之间的差异了,大家的语言、文化、习惯、信仰、肤色差异都很大,天然的也就会让人与人之间产生隔阂。新加坡在对于这种隔阂的消除、弱化上做得很好。大家都说一样的英语,虽然也保留自己的母语、大家都住在一样的房子里面,在一样的地方上学与生活,最终,让彼此最大限度的相处在一起。
在过程中,起初是感受到彼此的不同。而后,在印度神庙中,看到的大家脸上的对于诸神的虔诚,在哪里都是一样的;看到大家对于脱离痛苦的希冀,哪里都是一样的;看到爸爸带着孩子的介绍,孩子的好奇和父亲的关爱,哪里都是一样的;在India Heritage Centre为Deepavali表演的学生们脸上的自豪、兴奋与紧张,也都是一样的。
Raffles@National Museum of Singapore
周日,则去参观了新加坡国家博物馆。里面比较完整的介绍新加坡的历史。来的时候,已经注意到新加坡很多地方都以“Raffles”命名,包括最有名的酒店“Raffles Hotel”、“Raffles City”、“Raffles Institution”、“Raffles Place”等,而在国内也有一些高端的“来福士”商业中心。所以,参观时也特别留意了一下关于Raffles的介绍。

Raffles 全名是“Sir Thomas Stamford Bingley Raffles”,他被认为是现代新加坡的缔造者,曾是现代新加坡建立时的“总督”,虽然他在新加坡的实际任期时间并不长(“His longest tenure in Singapore was only eight months, but he was considered the founder of Singapore nevertheless.”)。主要原因在于[3]:
- 他很早看到了新加坡地缘所具备的潜力,在当时,事实意义控制了“现代新加坡”
- 制定了一系列具有现代化意义的城市规划与治理制度
最终,影响了这里发展成为真正的“现代新加坡”。
关于现代“Raffles”品牌
我并不关注当前的商业现状,出于好奇做了一些搜索和阅读。众多“Raffles”品牌可能是属于“淡马锡控股”[4],而淡马锡则是新加坡政府的投资公司,淡马锡则控制了众多新加坡的重要公司,例如“星展银行”(DBS)、Seatrium、新加坡航空、凯德置地(CapitaLand)等。李显龙的妻子何晶曾担任淡马锡控股的CEO[4]。
Lee Kuan Yew
Lee Kuan Yew 是当代新加坡国的实际建立者。关于他,已经有了很多中文资料,这里不再详述。
Java, the island
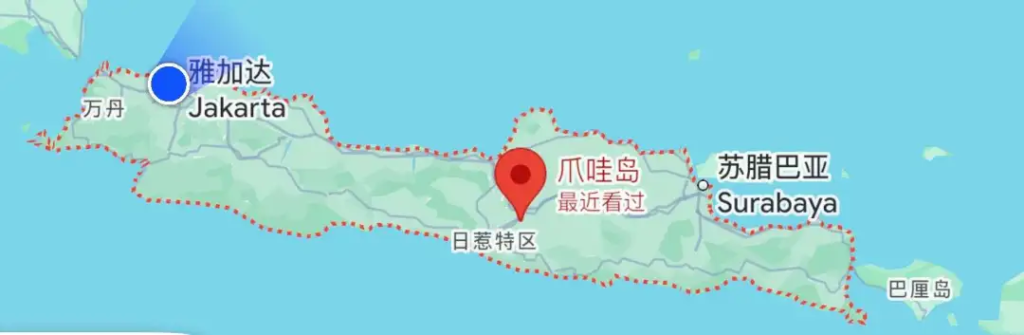
这次新加坡之行其中有两天去一趟 Jakarta-印尼的首都,位于Java岛的西北部。
Java 真的是一个岛,而且非常大。Java 岛是印尼人口最多的岛,也是印尼首都雅加达所在的地方。但如果在 Google 上搜索“Java”会发现,这个词已经被编程语言所占据,真正的“Java岛”的搜索结果只在第三,并且,整个第一页,只有这一个结果是与Java岛相关的。
不管怎样,Java 语言已经带火 Java 岛的咖啡。如果,你恰好在写Java,再来一杯Java,是不错的,如果你恰好是在Java岛上,那可能就完美了。
参考链接
- [1] https://en.wikipedia.org/wiki/Names_of_Singapore
- [2] https://en.wikipedia.org/wiki/Sri_Veeramakaliamman_Temple
- [3] https://en.wikipedia.org/wiki/Stamford_Raffles
- [4] https://en.wikipedia.org/wiki/Temasek_(company)

