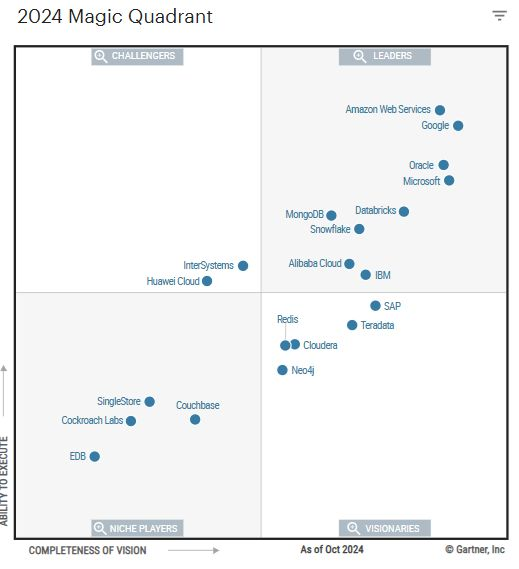
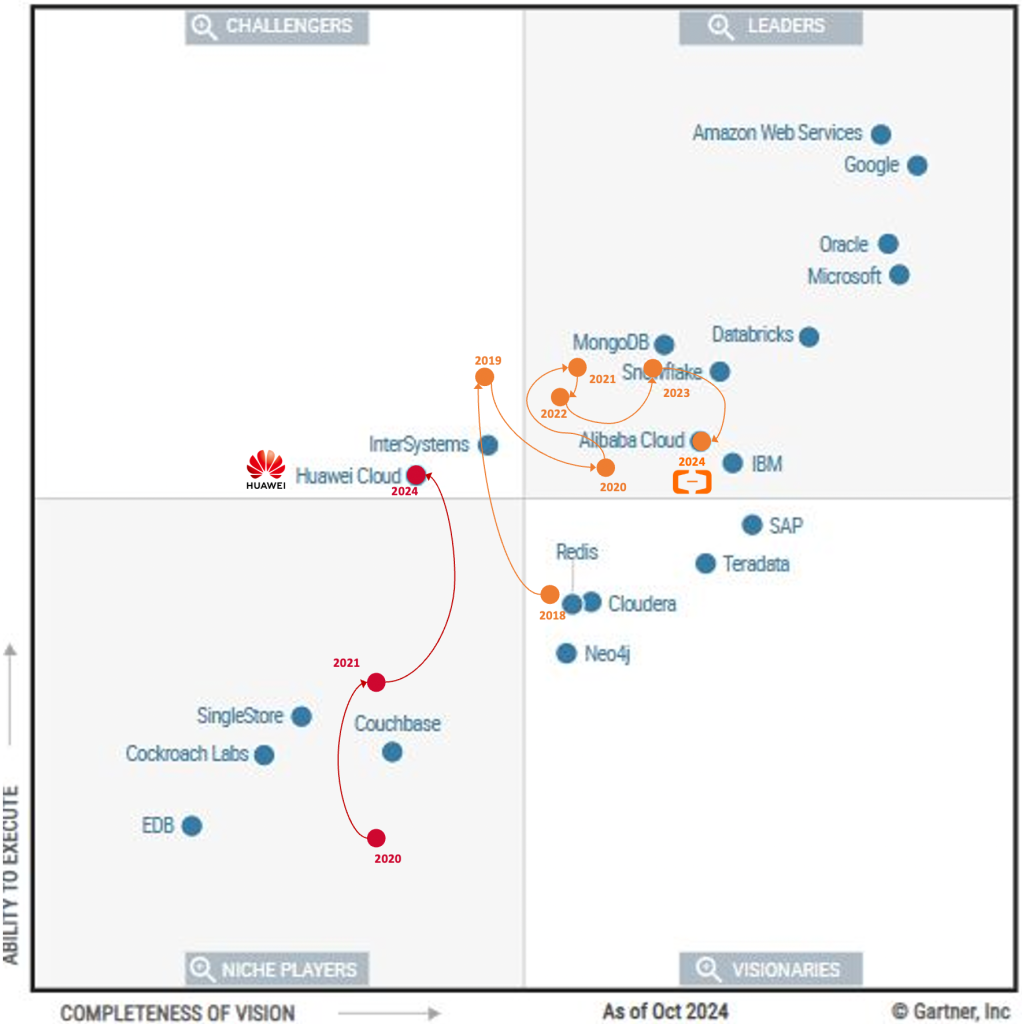
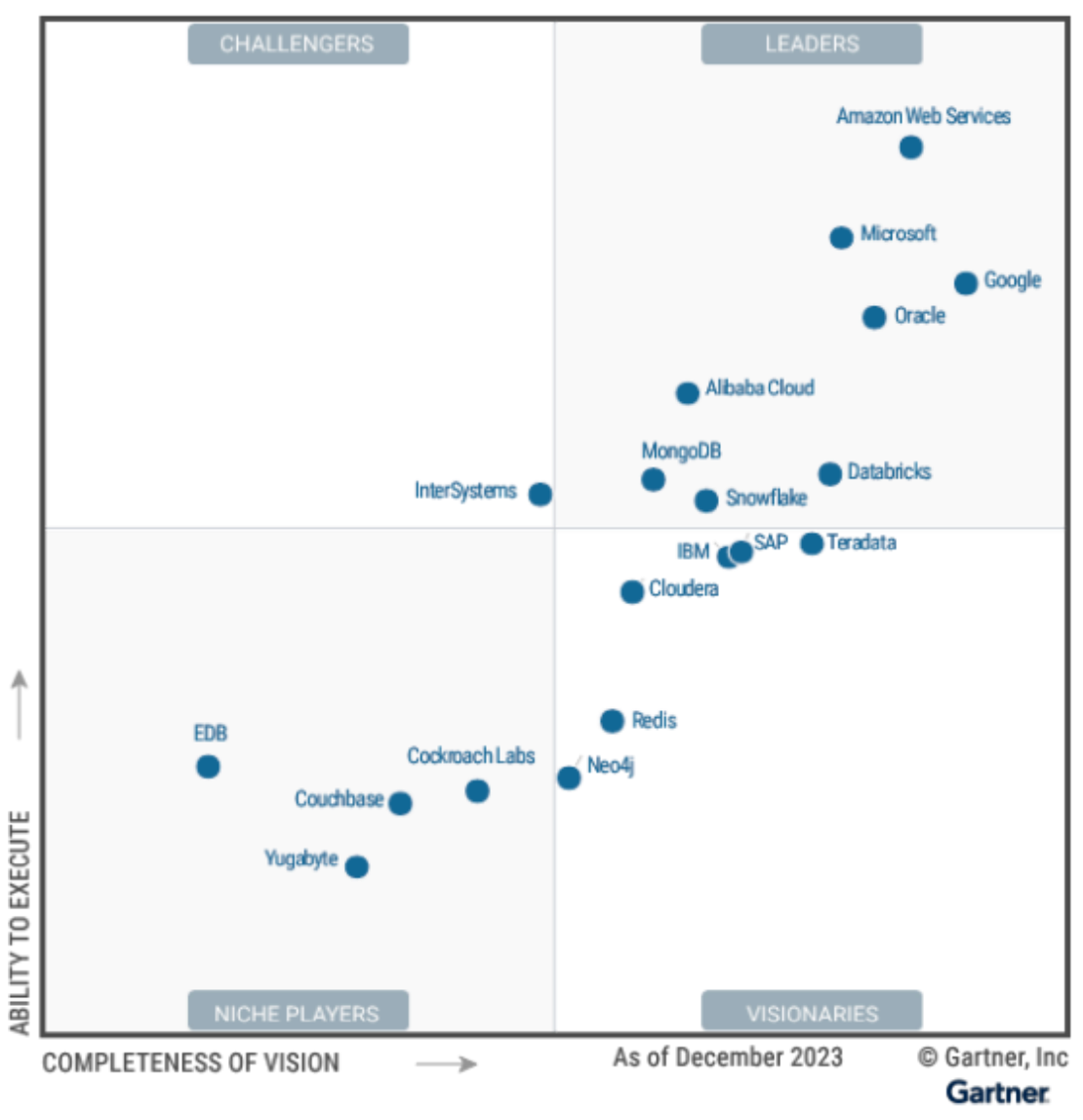
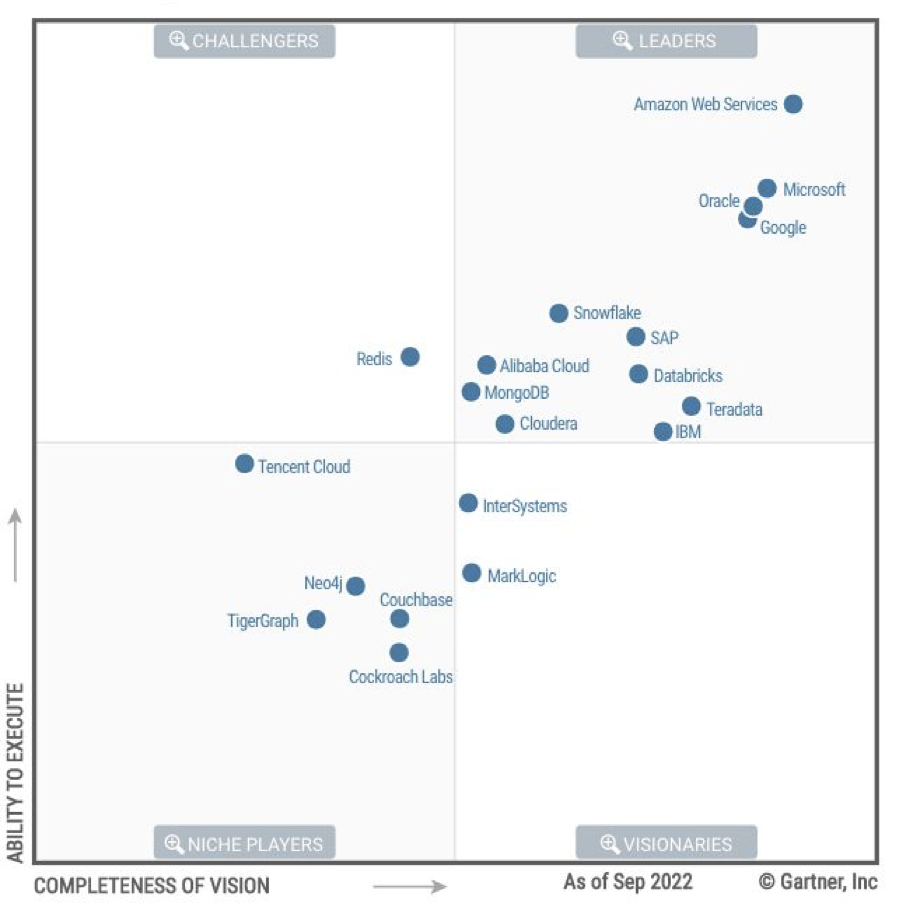
在昨天进行的SQL编程大赛中,所有 MySQL 选手的成绩都没有进入八强的。个人也对这个问题比较感兴趣,经过初步分析,重要的原因在于 MySQL 实现中没有比较好的并行加速的能力。而在 MySQL 的衍生版本中,倒是有几个版本提供了并行执行的能力。包括了 PolarDB 的 Elastic Parallel Query[2]、Amazon Aurora 的 Parallel query[3] 。所以,也打算验证一下,如果加上这些并行能力,是否能够更快。
结果综述
PolarDB MySQL 运行了与 MySQL “几乎”(仅添加Hint开启并行)相同的SQL(参考)运行最快为:3.821 s。相比在同一个集群,不开启并行的时间是 6.647s,速度提升了 42.5% 。此外也测试了Aurora的相同的规格,几经调试依旧无法使用其并行能力。
在相同的SQL实现下,PolarDB MySQL 可能是所有 MySQL 版本中性能最好的。如果,感觉还有什么版本可能有更好的性能,欢迎留言。
数据与SQL
这次是尝试使用 MySQL 高性能的完成“第二次SQL编程大赛”的进阶挑战。完整的题目描述可以参考:赛题说明[4]。这里实现的 PolarDB MySQL 版本 SQL 参考:gt.polardb.sql@GitHub[1](或参考本文结尾部分)。
PolarDB的规格选择
这里选择与试题类似的4c8g规格,详细参数如下:
主要参数:
- CPU架构:x86
- 产品版本:企业版
- 小版本号:8.0.2(与 MySQL 8.0.18 完全兼容)
- IMCI只读节点个数:0
- 初始只读节点个数:0
- 初始读写节点个数:1
- 节点规格:4 核 8GB(通用)
- 存储类型:PSL5
在 PolarDB 上并行执行
PolarDB 的并行执行可以使用 Hint 较为方便的开启:
SELECT
/*+PARALLEL(8)*/
...
可以通过执行计划观察,实际是否使用了并行:
| -> Gather (merge sort; slice: 1; workers: 8) (cost=2024861688.70 rows=1995124000) (actual time=1774.761..2159.495 rows=1000000 loops=1)
-> Sort: <temporary>.p_id (cost=1705198767.38 rows=249390500) (actual time=480.641,781.971,239.446..503.108,818.048,250.387 rows=125000,220305,60043 loops=1,1,1)
-> Stream results (actual time=1.631,2.232,1.396..380.381,630.231,168.213 rows=125000,220305,60043 loops=1,1,1)
-> Left hash join (t_01.a_s = p_01.a_s), (t_01.d_s = p_01.d_s), extra conditions: ((p_01.seq >= ((t_01.p_seat_to - t_01.seat_count) + 1)) and (p_01.seq <= t_01.p_seat_to)) (cost=25015432.30 rows=249390500) (actual time=1.621,2.220,1.387..200.048,332.885,86.841 rows=125000,220305,60043 loops=1,1,1)
-> Parallel table scan on p_01, with parallel partitions: 8 (actual time=0.002,0.003,0.002..48.149,74.839,20.489 rows=125000,220305,60043 loops=1,1,1)
-> Materialize (shared access, partitions: 8, partition_keys: a_s,) (actual time=0.001,0.002,0.001..24.240,34.098,9.331 rows=125000,220305,60043 loops=1,1,1)
-> Gather (slice: 1; workers: 8) (cost=1146187.18 rows=997560) (actual time=158.204..362.897 rows=1000000 loops=1)
-> Window aggregate (cost=1090064.43 rows=124695) (actual time=160.066,167.128,157.433..296.715,314.531,278.945 rows=125000,149658,102922 loops=1,1,1)
-> Repartition (hash keys: passenger.departure_station, passenger.arrival_station; merge sort; slice: 2; workers: 8) (cost=514229.38 rows=124695) (actual time=160.059,167.121,157.424..223.566,236.036,217.548 rows=125000,149658,102922 loops=1,1,1)
-> Sort: passenger.departure_station, passenger.arrival_station (cost=12554.66 rows=124695) (actual time=152.998,157.330,149.335..172.035,180.041,168.003 rows=125000,132932,111478 loops=1,1,1)
-> Parallel table scan on passenger, with parallel partitions: 745 (actual time=0.052,0.058,0.046..57.559,65.907,54.511 rows=125000,132932,111478 loops=1,1,1)
-> Hash
-> Table scan on t_01
-> Materialize (shared access) (actual time=0.002,0.003,0.001..0.744,0.935,0.666 rows=2000,2000,2000 loops=1,1,1)
-> Gather (slice: 1; workers: 8) (cost=3416.33 rows=2000) (actual time=6.884..7.646 rows=2000 loops=1)
-> Window aggregate with buffering (cost=3293.83 rows=250) (actual time=1.955,2.233,1.724..3.692,3.760,3.633 rows=250,292,196 loops=1,1,1)
-> Repartition (hash keys: t_include_no_seat.d_s, t_include_no_seat.a_s; slice: 2; workers: 1) (cost=3161.31 rows=250) (actual time=1.930,2.215,1.691..2.759,2.922,2.589 rows=250,292,196 loops=1,1,1)
-> Sort: t_include_no_seat.d_s, t_include_no_seat.a_s, t_include_no_seat.if_no_seat, t_include_no_seat.t_id (actual time=1.383,1.383,1.383..2.070,2.070,2.070 rows=2000,2000,2000 loops=1,1,1)
-> Table scan on t_include_no_seat (actual time=1.381,1.381,1.381..1.685,1.685,1.685 rows=2000,2000,2000 loops=1,1,1)
-> Materialize with deduplication (shared access) (actual time=0.001,0.001,0.001..0.295,0.295,0.295 rows=2000,2000,2000 loops=1,1,1)
-> Table scan on <union temporary> (cost=2.50 rows=0) (actual time=0.001..0.290 rows=2000 loops=1)
-> Union materialize with deduplication (actual time=2.330..3.003 rows=2000 loops=1)
-> Table scan on train (cost=101.25 rows=1000) (actual time=0.050..0.380 rows=1000 loops=1)
-> Table scan on train (cost=101.25 rows=1000) (actual time=0.023..0.348 rows=1000 loops=1)
|
这里的诸如Gather (merge sort; slice: 1; workers: 8)等内容,显示对应的部分会通过多线程并行执行。
执行时间统计
这里运行了该 SQL 三次的结果统计如下:
real 0m3.863s
user 0m0.379s
sys 0m0.100s
real 0m3.917s
user 0m0.414s
sys 0m0.123s
real 0m3.821s
user 0m0.422s
sys 0m0.128s
说明:这里,因为PolarDB是运行在云端,故仅需关注这里的 real 部分的时间。
不开启并行时 PolarDB 的性能
该组数据可用对比:
real 0m6.743s
user 0m0.394s
sys 0m0.120s
real 0m6.647s
user 0m0.393s
sys 0m0.120s
real 0m6.665s
user 0m0.407s
sys 0m0.125s
并行执行的一些状态参数
mysql> show global status like '%pq_%';
+-------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------+-------+
| PQ_fallback_one_worker | 0 |
| PQ_local_workers_created | 297 |
| PQ_migrant_workers_created | 0 |
| PQ_net_exchange_fail_connect | 0 |
| PQ_refused_over_computing_resource | 0 |
| PQ_refused_over_max_queuing_time | 0 |
| PQ_refused_over_total_workers | 0 |
| PQ_remote_workers_created | 0 |
| PQ_running_local_workers | 0 |
| PQ_running_migrant_workers | 0 |
| PQ_running_remote_workers | 0 |
| PQ_sched_adative_resource_dec_count | 0 |
| PQ_sched_adative_resource_inc_count | 0 |
+-------------------------------------+-------+
使用 Aurora 的并行执行
这里也尝试使用 Aurora 的并行查询进行优化,但是并没有成功。Aurora 的并行执行并没有 Hint 可以控制,而是优化器根据需要选择使用。在本次测试中,在一个 4c32gb 的Aurora实例上,几经尝试,都未能实现并行。故未成功测试。在非并行时,Aurora的执行时间为 6.921s。
开启Aurora并行执行
要使用 Aurora 的并行执行能力,需要先创建最新版本的Aurora,在选择的参数组(parameter group)时,该参数组需要打开 aurora_parallel_query 参数。在实例创建完成后,可以通过如下命令查看并行查询是否打开:
mysql> show global variables like '%aurora_parallel_query%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| aurora_parallel_query | ON |
+-----------------------+-------+
Aurora上的执行时间
这里记录相关SQL的执行时间如下:
real 0m6.921s
user 0m1.022s
sys 0m0.076s
[ec2-user@xterm-256color- delete_me]$ time mysql --local-infile=true -hpq-testing.cluster-cjzowaj9vqpd.ap-northeast-1.rds.amazonaws.com -ub_admin -p-f7HNhmp_frX game_ticket < aurora.sql > aurora.ret
mysql: [Warning] Using a password on the command line interface can be insecure.
real 0m6.955s
user 0m1.012s
sys 0m0.076s
[ec2-user@xterm-256color- delete_me]$ time mysql --local-infile=true -hpq-testing.cluster-cjzowaj9vqpd.ap-northeast-1.rds.amazonaws.com -ub_admin -p-f7HNhmp_frX game_ticket < aurora.sql > aurora.ret
mysql: [Warning] Using a password on the command line interface can be insecure.
real 0m7.154s
user 0m0.970s
sys 0m0.138s
最后
PolarDB MySQL 在并行执行开启的情况下性能提升了42.5%,最终执行时间为 3.821 s。有可能是所有 MySQL 兼容的发型版本中性能最快的。
gt.polardb.sql
-- explain analyze
WITH
t_no_seat_virtual AS (
select
train_id as t_id,
departure_station as d_s,
arrival_station as a_s,
seat_count,
seat_count*0.1 as seat_count_no_seat
from train
),
t_include_no_seat AS (
select t_id,d_s ,a_s ,seat_count, 0 as if_no_seat
from t_no_seat_virtual
union
select t_id,d_s ,a_s ,seat_count_no_seat, 1 as if_no_seat
from t_no_seat_virtual
)
SELECT
/*+PARALLEL(8)*/
p_01.p_id, -- output 01
p_01.d_s, -- output 02
p_01.a_s, -- output 03
t_01.t_id as t_id, -- output 04
IF(
if_no_seat,
"" ,
ceil((p_01.seq-t_01.p_seat_to + t_01.seat_count)/100)
) as t_carr_id, -- output 05
CASE IF( !isnull(t_01.t_id) and if_no_seat,-1,ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)%5))
WHEN 1 THEN CONCAT( ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) ,"A")
WHEN 2 THEN CONCAT( ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) ,"B")
WHEN 3 THEN CONCAT( ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) ,"C")
WHEN 4 THEN CONCAT( ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) ,"E")
WHEN 0 THEN CONCAT( IF( (p_01.seq-t_01.p_seat_to + t_01.seat_count)%100 = 0, "20" ,ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5)) ,"F")
WHEN -1 THEN "无座"
ELSE NULL
END as seat_index -- output 06
FROM
(
select
/*+PARALLEL(8)*/
ROW_NUMBER() over(PARTITION BY departure_station,arrival_station) as seq ,
passenger_id as p_id,
departure_station as d_s,
arrival_station as a_s
from
passenger
) as p_01
LEFT JOIN
(
select
/*+PARALLEL(8)*/
seat_count,
sum(seat_count)
over (
PARTITION BY d_s,a_s
ORDER BY if_no_seat,t_id
) as p_seat_to ,
t_id,
d_s ,
a_s ,
if_no_seat
from
t_include_no_seat
) t_01
ON
p_01.seq >= p_seat_to-seat_count + 1
and p_01.seq <= p_seat_to
and p_01.d_s = t_01.d_s
and p_01.a_s = t_01.a_s
ORDER BY p_01.p_id
参考链接