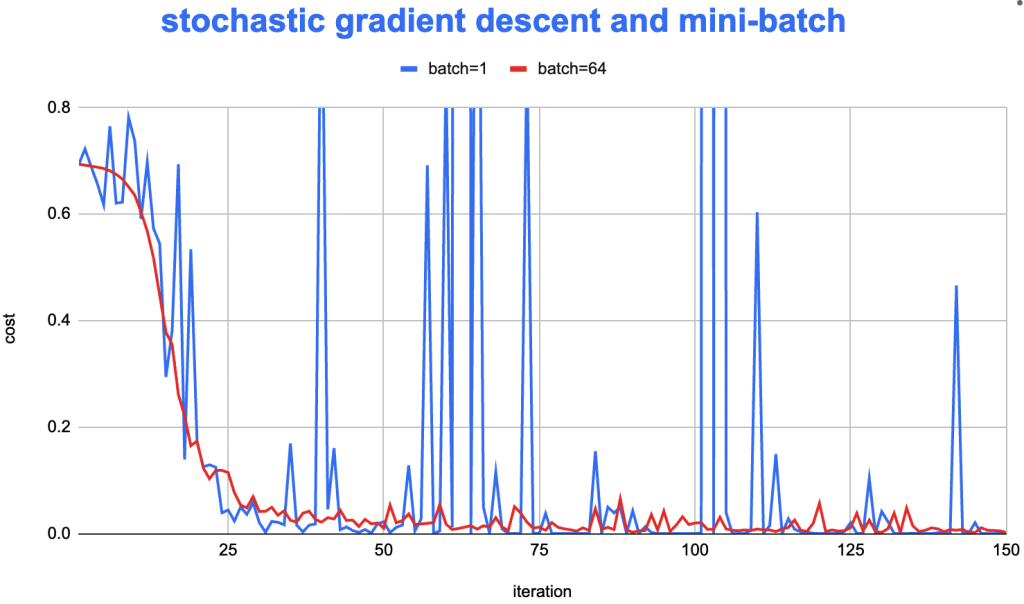
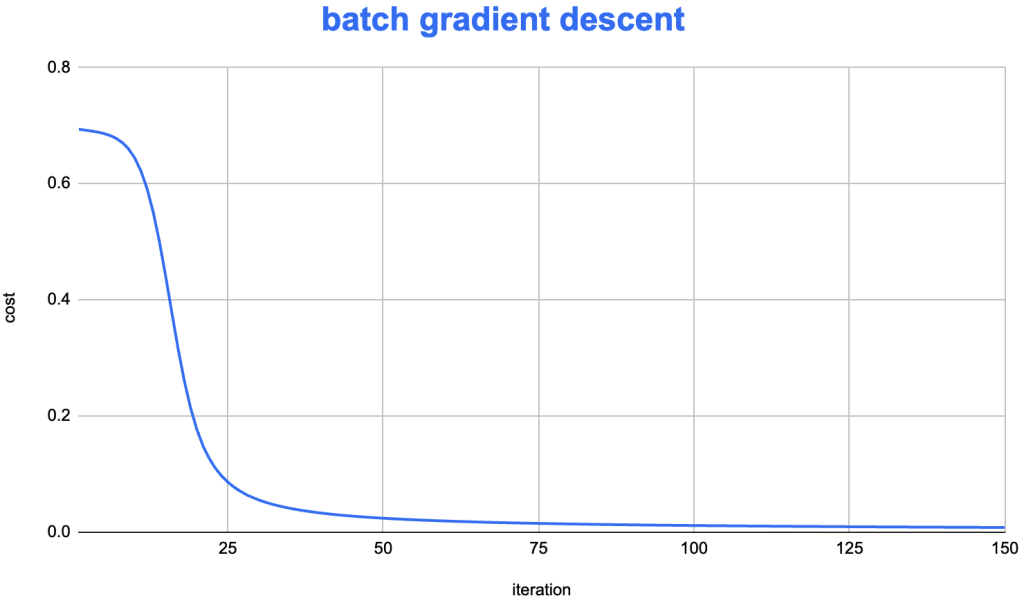
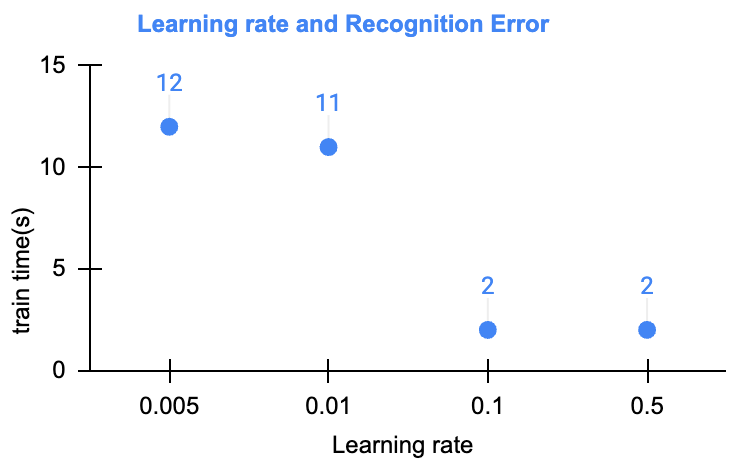
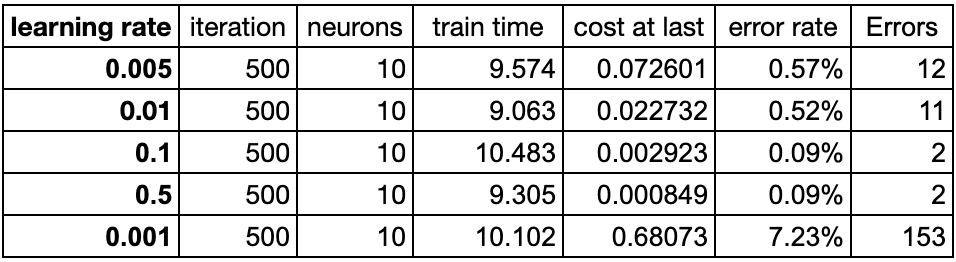
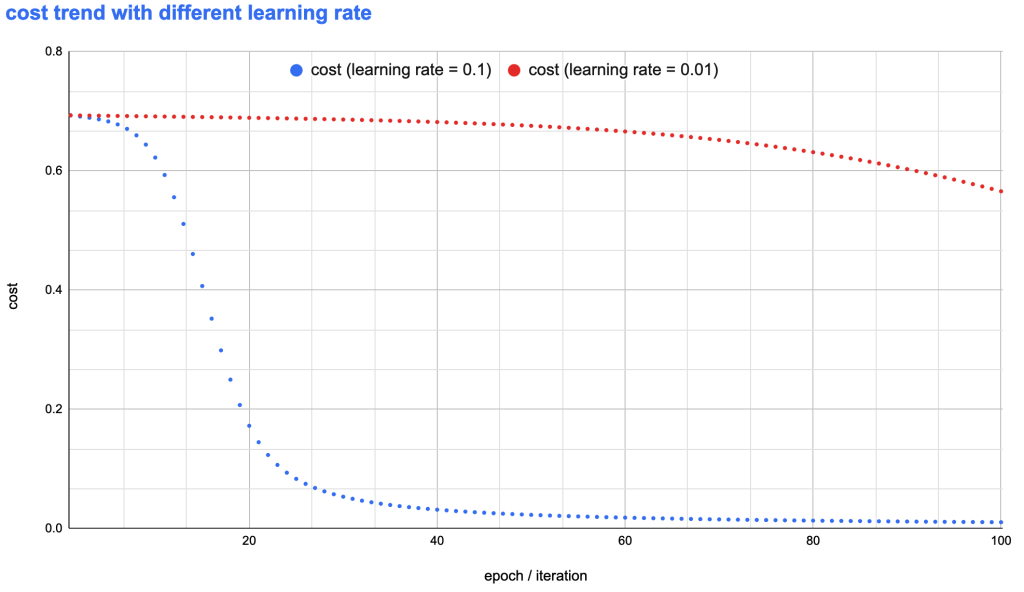
for "a-small-batch-of-samples X^{t} " in "all-samples"
forward propagation on X^{t}
backward propagation on X^{t}
update W/b
W^{[l]} = W^{[l]} - lr * dW^{[l]}
b^{[l]} = b^{[l]} - lr * db^{[l]}
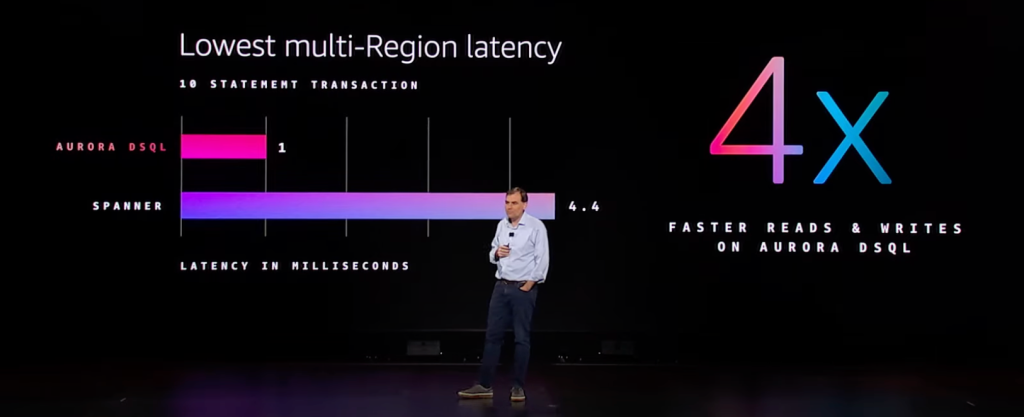
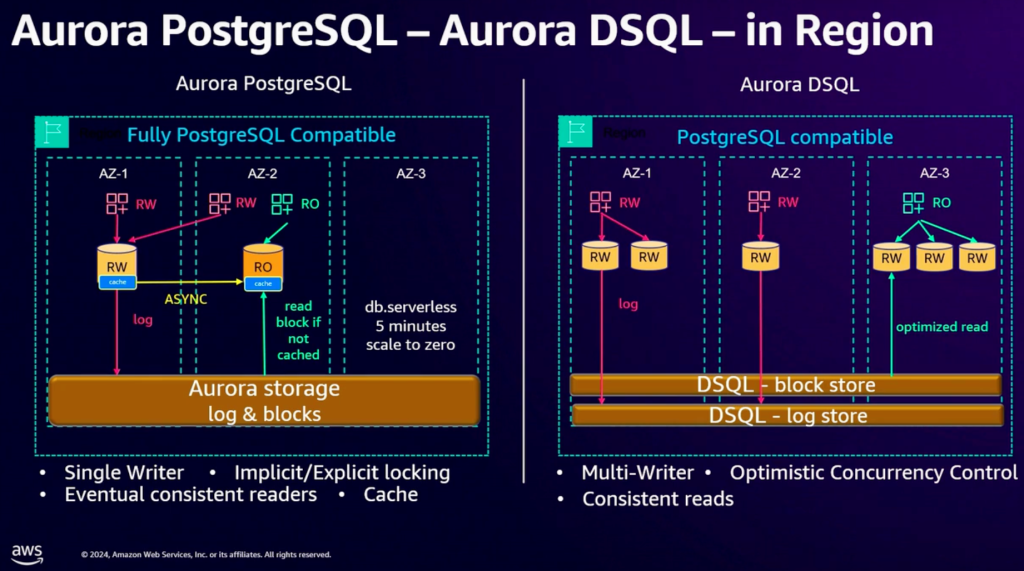
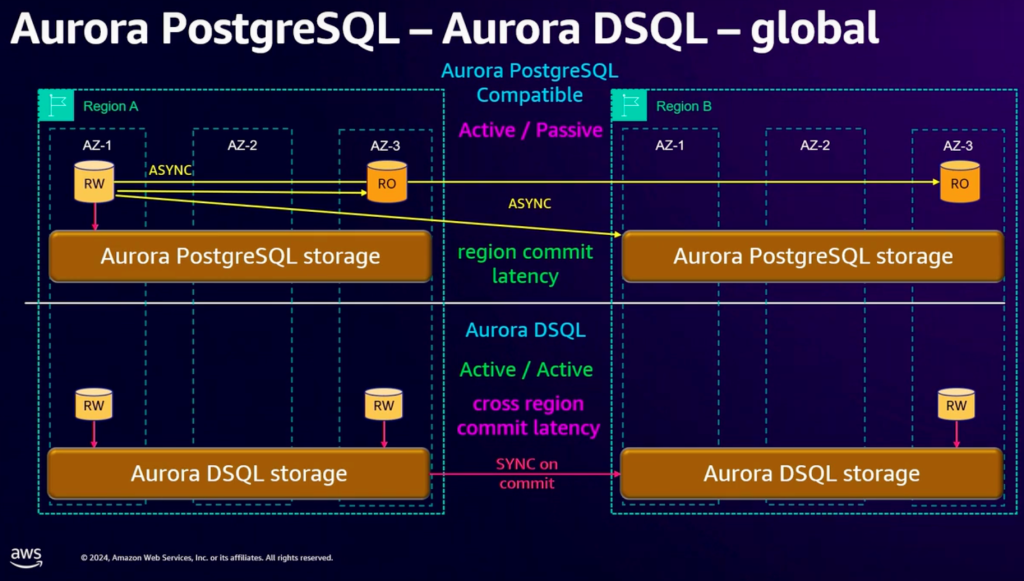
Aurora DSQL 提供了多可用区、多区域的多点一致性写入的内容。在技术层面,Aurora DSQL 通过把数据库的 log 模块和 block (或者说是cache)模块做了分离,从而更好的实现多点/多区域分布式能力,这与 Google AlloyDB 是比较类似的;此外,在跨区域强一致性实现上,则使用“Amazon Time Sync Service” [3] 来保障多个区域之间事务顺序的一致性。
在产品层面,分为两个场景,一个是 Aurora DSQL(region内模式)和一个 Aurora DSQL Global 模式(多 region 内模式)。在 Region 内场景下,相比于普通 Aurora PostgreSQL ,Aurora DSQL 在多个可用区内都可以提供强一致的读写接入点,而Aurora PostgreSQL只在一个可用区提供写,其他可用区仅提供只读节点。
在跨 Region 的场景下,Aurora DSQL 则提供了同步的、跨区域的多点写入能力。这对于业务在全球分布的客户,则可以进一步的降低业务的复杂度。而原来的 Aurora Global Database 仅提供单个 Region 的写入能力,并且,在其他 Region 的读节点需要承受一定的数据访问延迟,这对于很多的在线业务场景可能是无法接受的,或者需要在应用层面做针对性的改造。