Oracle 云(即Oracle Cloud Infrastructure,简称OCI )的免费策略大概是所有云厂商中最为彻底与直接的。对于注册的账号,可以持续免费使用主要的云资源,包括虚拟主机(VM.Standard.E2.1.Micro)、数据库(1OCPU 16GB内存)等。
相比于 AWS 的 一个月免费、GCP的 $300 代金券,OCI在免费策略上是最具诚意的云厂商。在使用方式上,也更具有诚意,不太因为使用超时、忘记关闭、规格选择错误等因素,而造成误收费,这些在AWS、GCP上都是很容易发生的。
创建免费的数据库
创建免费的 HeatWave MySQL 实例
在创建数据库时,就可以选择“Always Free”选项,这时,在后续规格选择的时候,就不会误选成计费实例了。
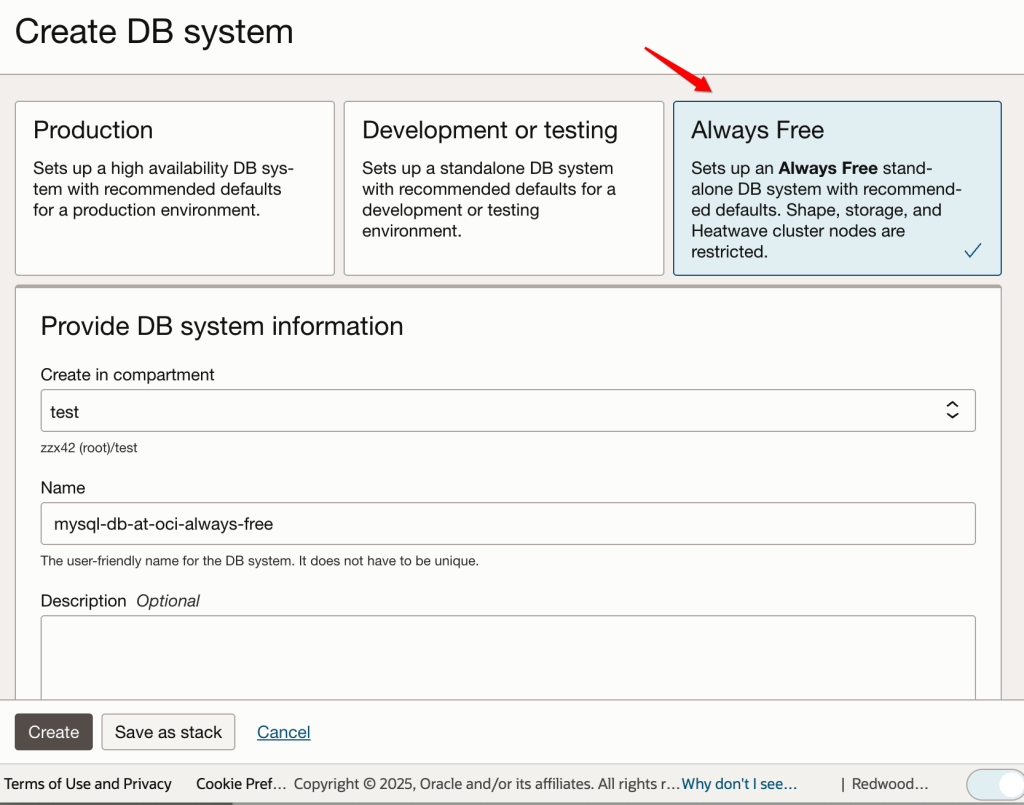
开启免费的 HeatWave 实例
HeatWave是最近几年Oracle/MySQL最重要的发展方向,可以非常好的支持各种复杂与分析类的查询,很好的弥补了MySQL在分析能力上的短板。
“Always Free” 也非常友好的支持了 HeatWave 相关的特性,可以让开发者非常好的体验HeatWave相关功能。
创建实例账号
创建数据库的管理员账号:

查看免费实例
在完成实例创建后,实例详情,可以看到“Always Free”标签:

创建虚拟主机
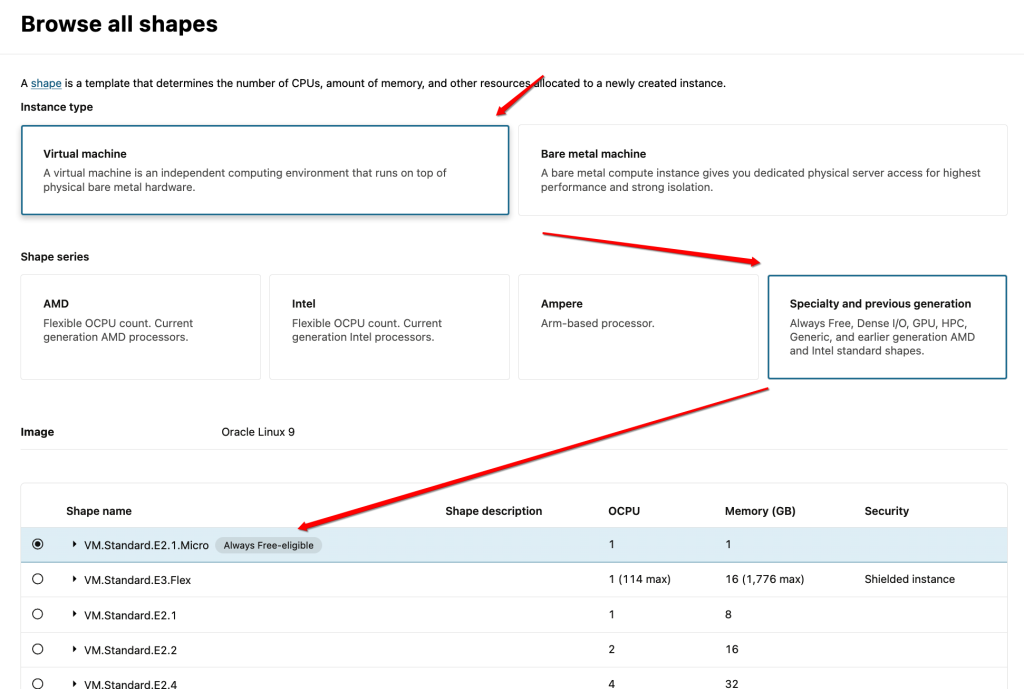
选择免费的虚拟主机规格
这里需要注意,目前支持的免费规格,需要在分类“Virtual Machine->Specialty and previous generation”中选择:
虚拟主机的基础选项

查看实例状态
在虚拟主机的实例列表页,可以查看该实例,并且看到免费标签“Always Free”:


