前几天Aurora Serverless正式GA, 第一时间体验了一下,看看到底怎样。
概述
Lambda的无服务技术是AWS在云产品形态上的一次重大创新,它把云计算最重要的“弹性”能力再向前推了一步。Aurora Serverless MySQL是Serverless技术在数据库上的应用。Aurora Serverless理念非常好,长远来看,对于用户来说,可以根据实际系统压力进行结算,比一次性购买预留实例更加实惠。这是云计算,对于“弹性”概念的又一次升级。
对于云厂商来说,当云的规模足够大时,相比使用预留实例的方式,通过这种系统控制的自动弹性能力,可以极大提高整体的系统利用率。一个简单、极端但是可以说明效果的例子是这样的:如果有两套系统,一套是服务东半球的用户,一套是服务西半球的用户,那么相比给两套系统都预留最大要求容量的资源,这种全自动的弹性可能只需要使用75%或者更少的资源(最低是50%),就可以服务好这两套系统业务。当你服务的业务的高低峰错峰越明显,资源体量越大,那么这种自动弹性的能力带来的效益可能就越大。
那么,我们来看看实际使用中,会带来哪些好处,又或者可能会有哪些“坑”需要小心。
购买
Aurora Serverless MySQL目前只支持MySQL5.6版本,购买过程中配置选项很少,主要需要用户配置,允许弹性的范围,包括如下三部分
- 实例最大可以扩容(scaling-up)到多少
- 实例最小可以缩容(scaling-down)到多少
- 另外,是否允许实例完全没有压力时,暂停实例(scaling to zero)
如果候选了Pause选项,默认实例在连续五分钟没有任何压力时,实例自动被暂停,下一次请求过来后,实例再自动恢复。
控制台
控制台包含了如下信息:
(1) 实例详情,包括主要配置、endpoint、备份计划等信息。
(2) 监控指标,这里提供了共29个监控指标,粒度为1分钟。包括Database Capacity、CPU Utilization、DB Connections等。
(3) 弹性扩缩容的记录,这里记录每次弹性出发的时间点,以及何时完成弹性扩缩容。
实测
这里购买了一个最小为2 capacity units,最大为8 capacity units的实例,内存分别对应为4GB和16GB。
新建数据库表:
CREATE TABLE `a` ( `id` int(11) NOT NULL DEFAULT '0', `num` int(11) DEFAULT NULL, `bid` int(11) DEFAULT NULL, KEY `IND_NUM` (`num`) ) ENGINE=InnoDB
初始化数据(多个如下命令并行):
for i in `seq 0 30000`;do mysql -uzhou -p -hzhou-aurora-1.cluster-cjzowaj9vqpd.ap-northeast-1.rds.amazonaws.com -poraHz#nhTv%8 -v supu -e " insert into a values (rand()*100000,rand()*10000,rand()*10000)"; done
重复运行简单查询:
#!/bin/bash for i in `seq 1 500000` ;do sleep 0.5 && TZ=Asia/Shanghai date +%H:%M:%S.%N && time mysql -uzhou -p -hzhou-aurora-1.cluster-cjzowaj9vqpd.ap-northeast-1.rds.amazonaws.com -poraHz#nhTv%8 supu -e "select * from a where num=4484 limit 1" -q > 1.log 2>2.log ;done
运行大压力SQL(并行几个就可以把系统压力加上去):
select * from a,a as b where a.bid = b.id;
scaling-up测试
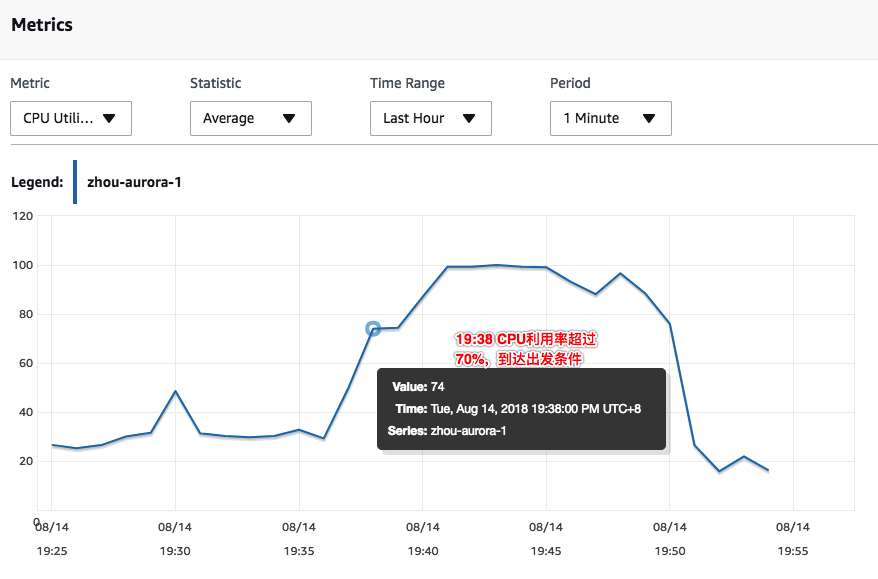
在给系统增加多个select * from a,a as b where a.bid = b.id;并行运行以后,系统压力很快就上去了。
系统压力在19:38分CPU利用超过70%,17:43开始出发scaling-up。即五分钟后开始触发scaling-up。
这是一个,关于执行query响应时间稳定性的趋势图,可以看到,在完成scaling-up之后,系统响应会更加稳定:

(点击查看大图)
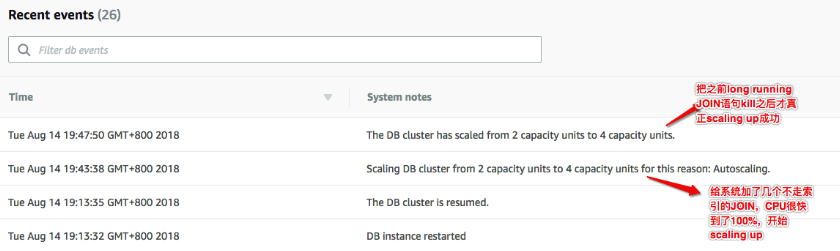
另外,这里发现一个问题,在系统压力加上去后,scaling-up动作一致没有成功完成。原因在于,Aurora Serverless在出发scaling-up之后,会选取一个scaling point开始去支持scaling的动作,执行这个动作必须避开如下情况: long running query或者long running transaction。
在上面的案例中,系统中有多个long running query,所以一直没有scaling-up成功,直到我登上数据库,把long running的query全部kill,Aurora才成功完成scaling-up。
这是一个非常严重的问题,在系统压力很大的时候,很可能存在长时间运行的query或者transaction,这些query可能是系统压力大的“因”,也有可能是“果”,但,这是非常常见的。这可能导致,scaling-up在很多情况下都无法成功,也就达不到当系统压力较大时,自动scaling-up这个目的。
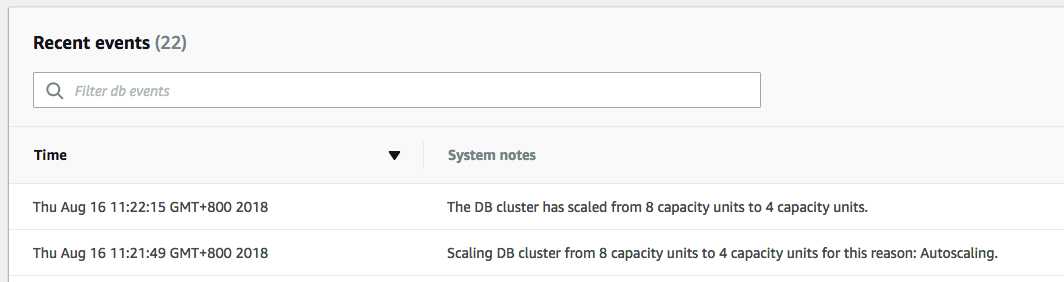
scaling-down测试
scaling-down的触发条件是CPU利用率小于30%,并且,连接数低于40%。当系统压力下降时,会触发scaling-down:
scaling to zero / paused测试
特别是对于个人测试环境来说,这是一个非常好的特性。当我,晚上不再使用这个实例的时候,实例相当于会自动停掉,是非常节约成本的。
看下图日志,可以看到:18:24分我去食堂吃饭了,系统很快进入了paused状态。19:13我回来继续测试,系统开始重新恢复,这里显示,系统恢复时间约为17秒。但是在实际测试过程中,从paused状态再入恢复到可用,实际感受约25秒。
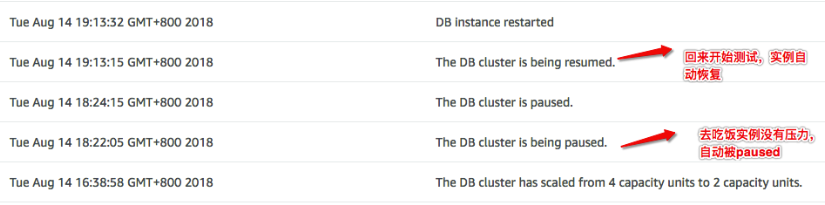
但是,这里也发现了另一个问题。scaling to zero的触发条件必须是系统没有任何query,且系统没有任何连接。很多时候,系统没有任何连接是比较难的,比如在实测时就出现了这个情况,由于某个终端下建立的MySQL连接,但是该终端由于某个原因异常断开了,但是,这时这个MySQL连接在Server端很可能会一直保持,这会导致,Aurora无法scaling to zero。这种断掉的连接,在服务端可能要经历非常长的“超时”设置才会被断开。
没有正确断开的连接,也会导致Aurora无法scaling to zero,而没有正确断开的连接,在实际管理操作中这是比较常见的。
其他概念
cooldown
scaling-up的操作有3分钟的cooldown,只有在上次scaling操作之后至少3分钟才会触发。Scaling-down的cooldown为15分钟。
1.5分钟和5分钟
触发scaling-up需要系统达到触发条件,并持续1.5分钟,才会触发。Scaling-down则需要达到触发条件5分钟才会开始触发。
scaling point
scaling-up操作过程中,如果没有满足条件的scaling point,那么在尝试五次scaling操作之后,系统将会放弃。

总结
如果系统压力是缓慢增长,Aurora Serverless那么这种scaling策略可能非常有效。
但是,在实测中也发现一些问题,比如,scaling-up操作需要寻找到没有long running query和transaction的scaling point,实际情况中这个要求是很高的,系统压力较大时,尤其是系统压力突然增大时,很可能会由于找不到scaling point而导致scaling-up失败。再比如,如果希望scaling to zero,那么系统不仅没有query,而且不能有任何的连接,而这在实际情况中也是比较难控制的。
Aurora Serverless MySQL给用户带来的实惠是,真正的按使用量付费,数据库压力大的时候,系统自动进行升级,用户需要支付更大实例的费用,数据库压力小的时候,系统自动降级,则只需支付较少的费用,当完全没有压力的时候,则无需支付任何计算(包括内存)费用,只需支付存储费用。听起来比较美好,但是要在生产中比较好的使用,还需要一定的“磨合”。
–EOF–
Leave a Reply