Database
-

整体上,今年的魔力象限与去年的厂商完全相同,各厂商的相对位置变化也并不是很大。一些值得注意的点如下:
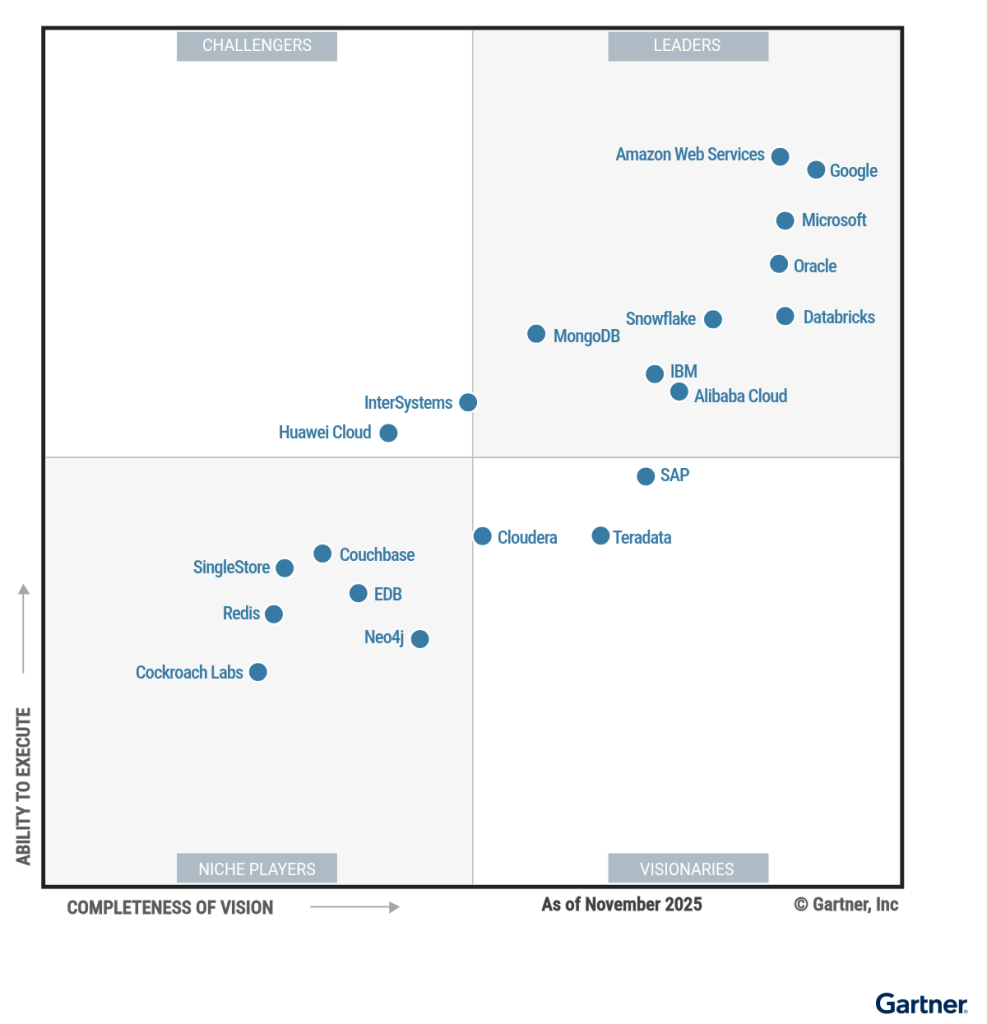
- Redis 从 Visionaries 跌到 Niche Player 象限;这反应了 Redis 在社区所面临的困境,一方面是开源商业化的挑战;另一方,则是来自于 Valkey 社区–一个更加开放的 Key-Value 产品的竞争。
- Neo4j 也从 Visionaries 跌到 Niche Player 象限。
- 在第一军团(即Google AWS Microsoft Oracle)中,Oracle 位置略有下降。确实,Oracle 早就已经不再是一家数据库厂商了。
- Databricks 和 Snowflake 凭借在数据处理上的领先,在横坐标(Visionaries)上前进了一大截
- 此外,虽然没有在象限图中(仅前20的厂商),但依旧在Gartner关注对象中的厂商包括:Actian Broadcom ClickHouse InfluxData MotherDuck OceanBase PingCAP Tencent Cloud TigerGraph Yugabyte
象限中的中国数据库厂商

进入这次魔力象限的中国厂商与去年相同:阿里云数据库、华为云数据库。相比去年,两个厂商的位置变化也不太大,可以参考右图。
阿里云数据库在 Vision 象限继续向前移动了一点。华为云则保持了相对位置几乎不变。
此外,出现在“Honorable Mentions”部分的中国厂商有:
- OceanBase
- PingCAP
- Tencent Cloud
历史魔力象限列表
2025-11 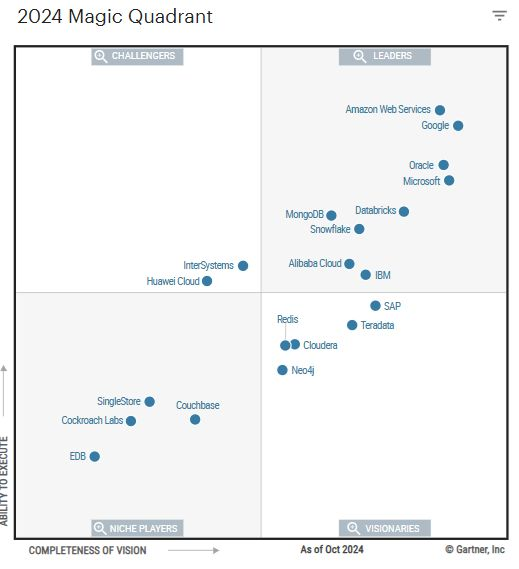
2024 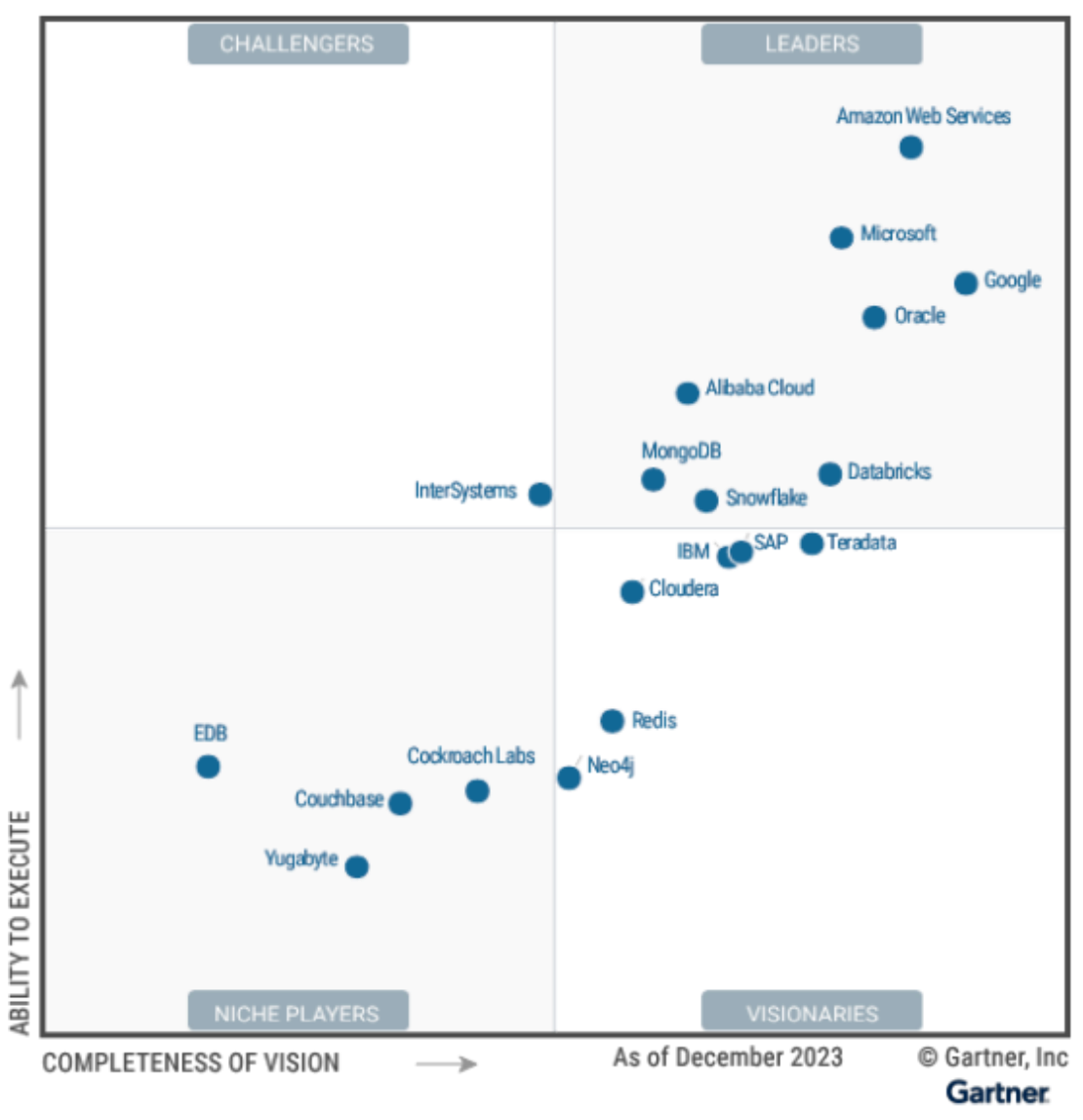
2023 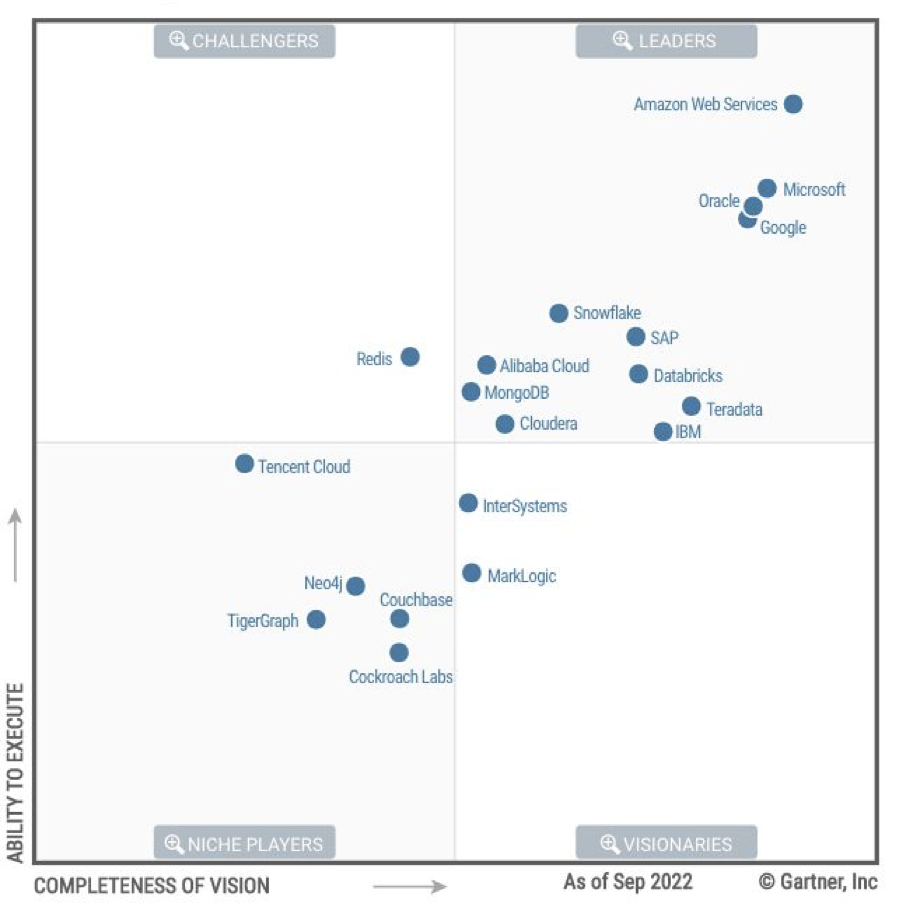
2022 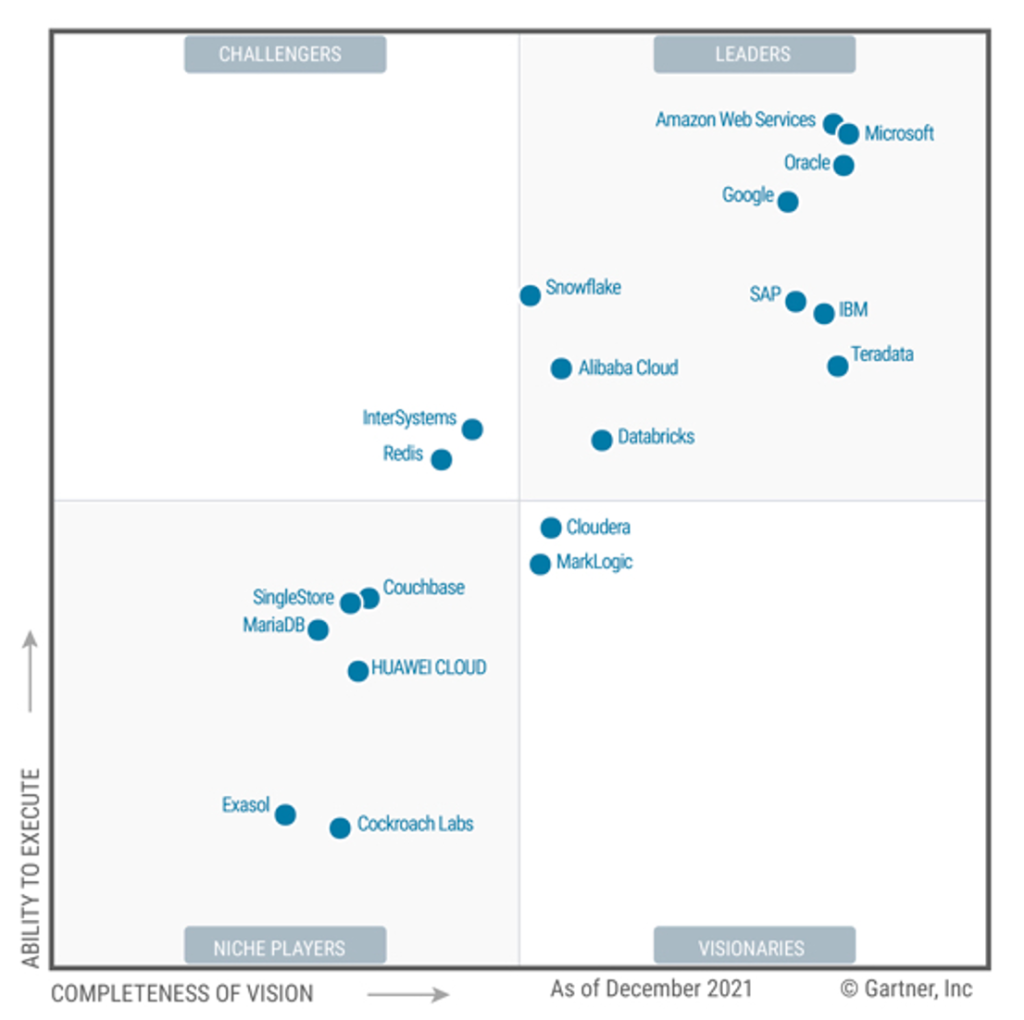
2021 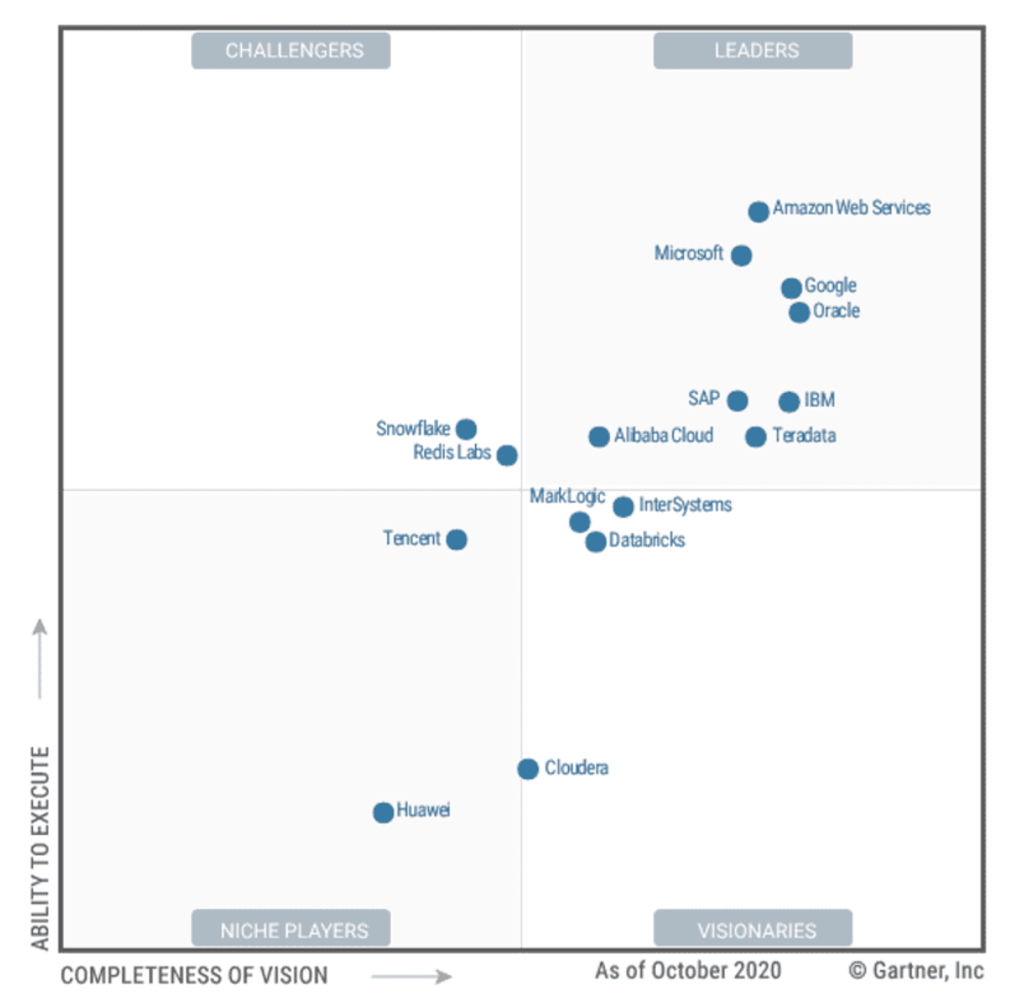
2020 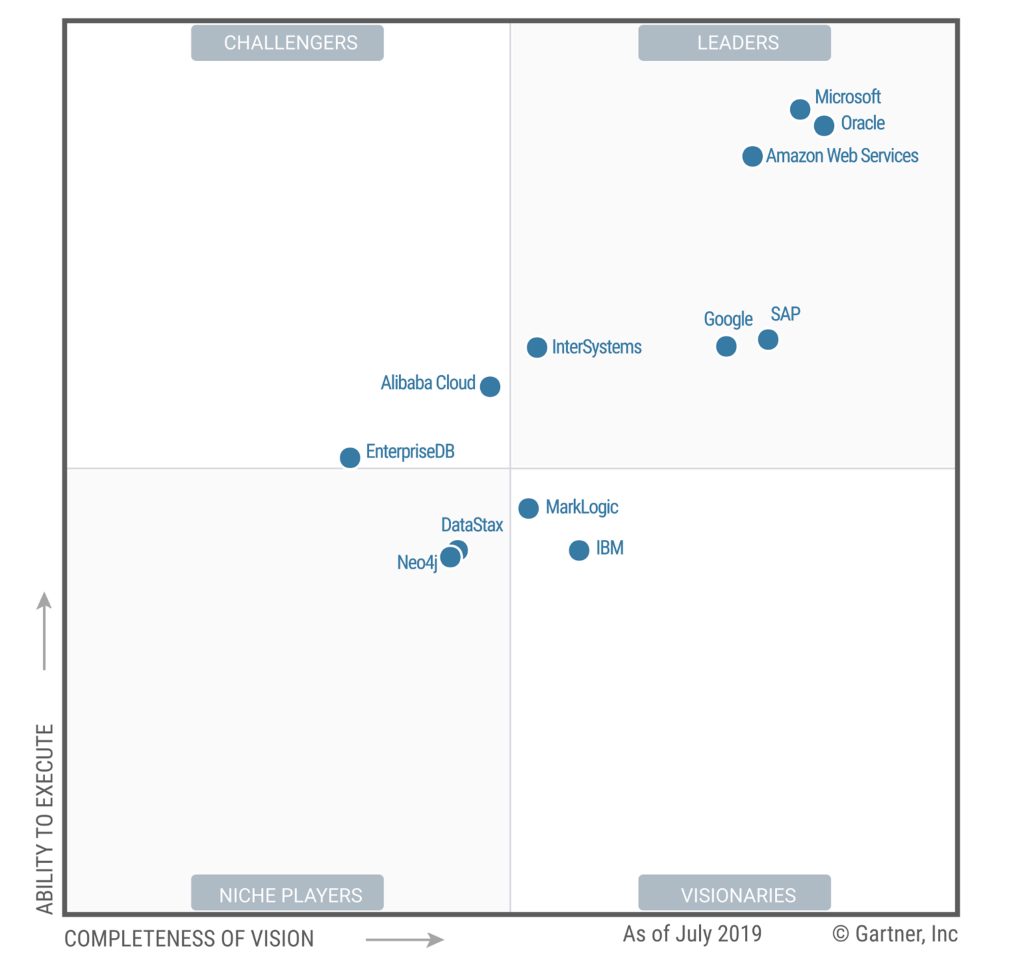
2019 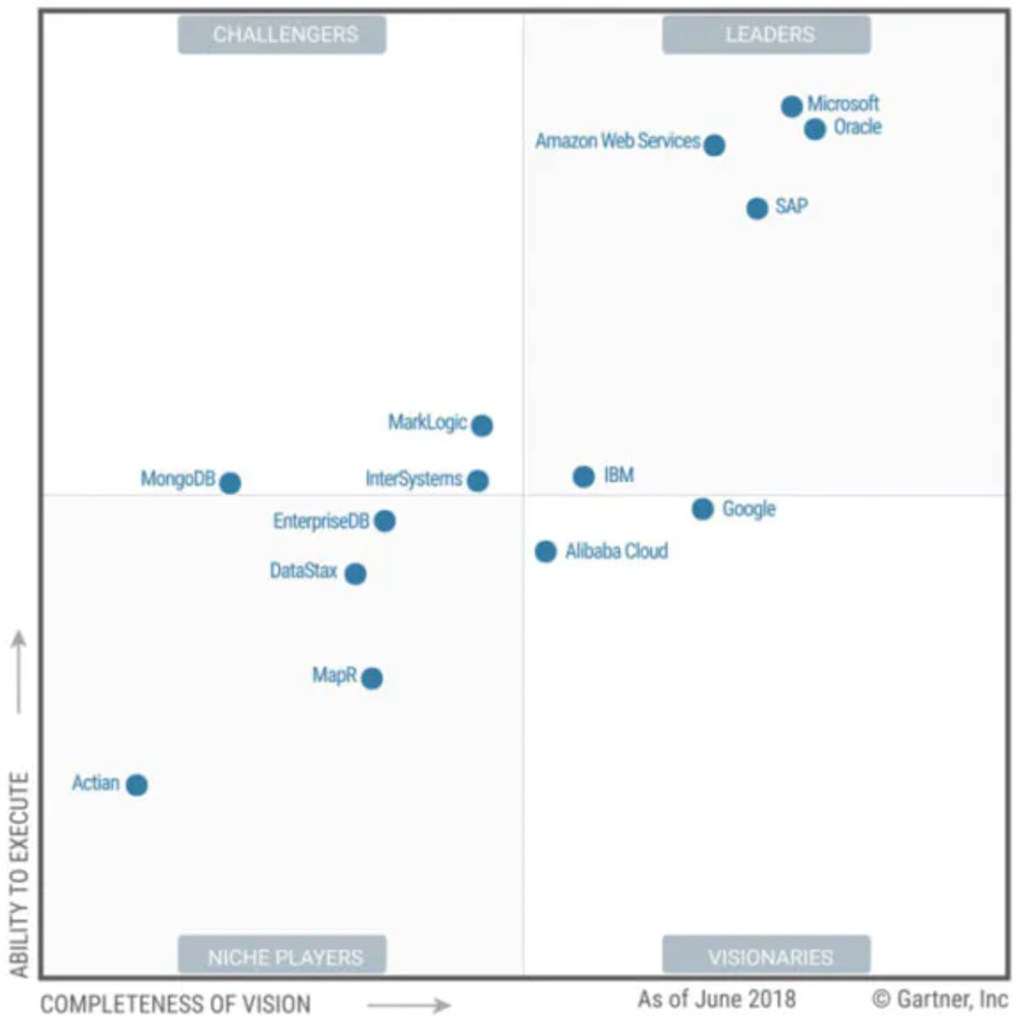
2018 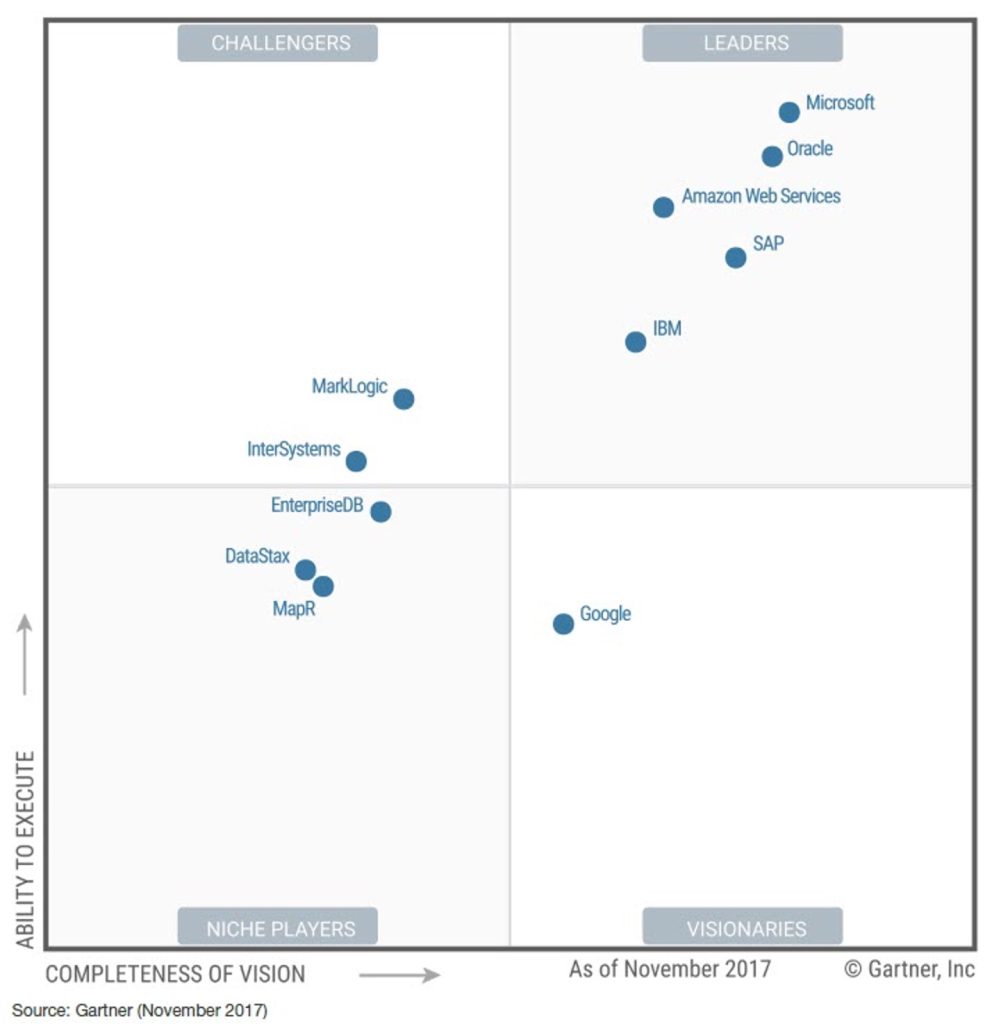
2017 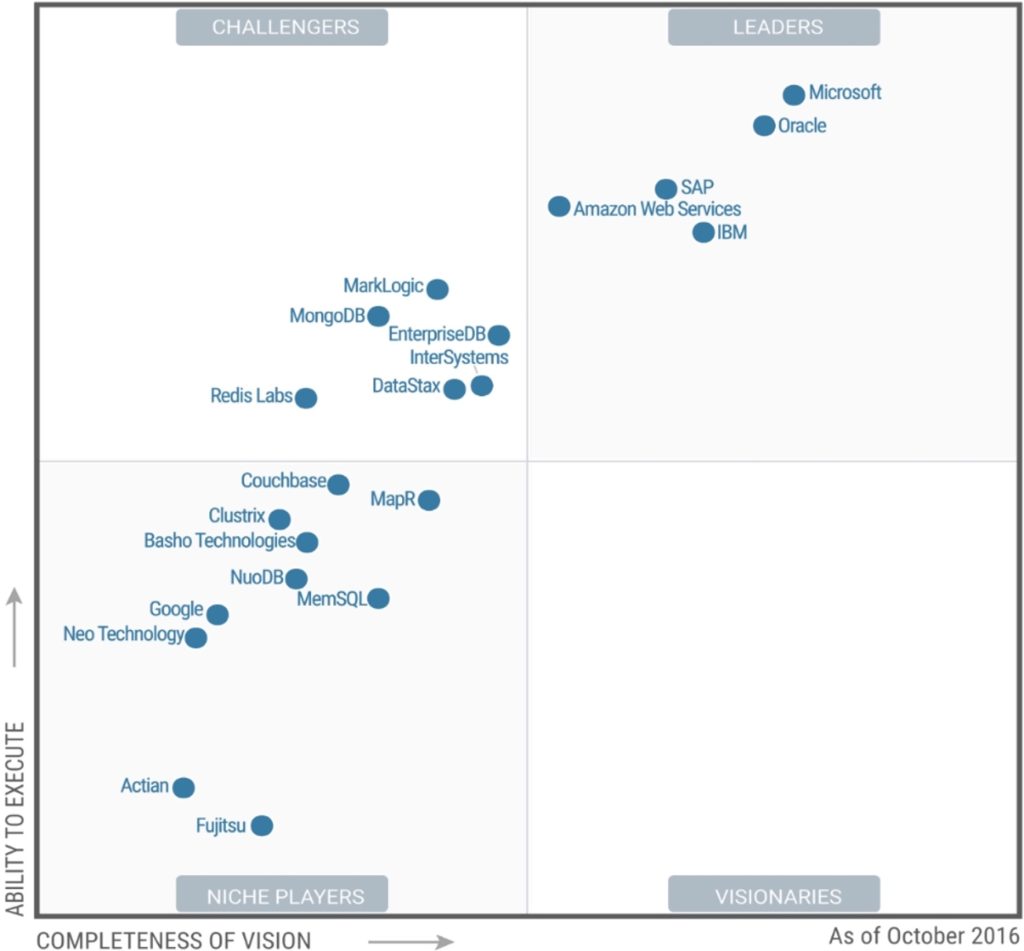
2016 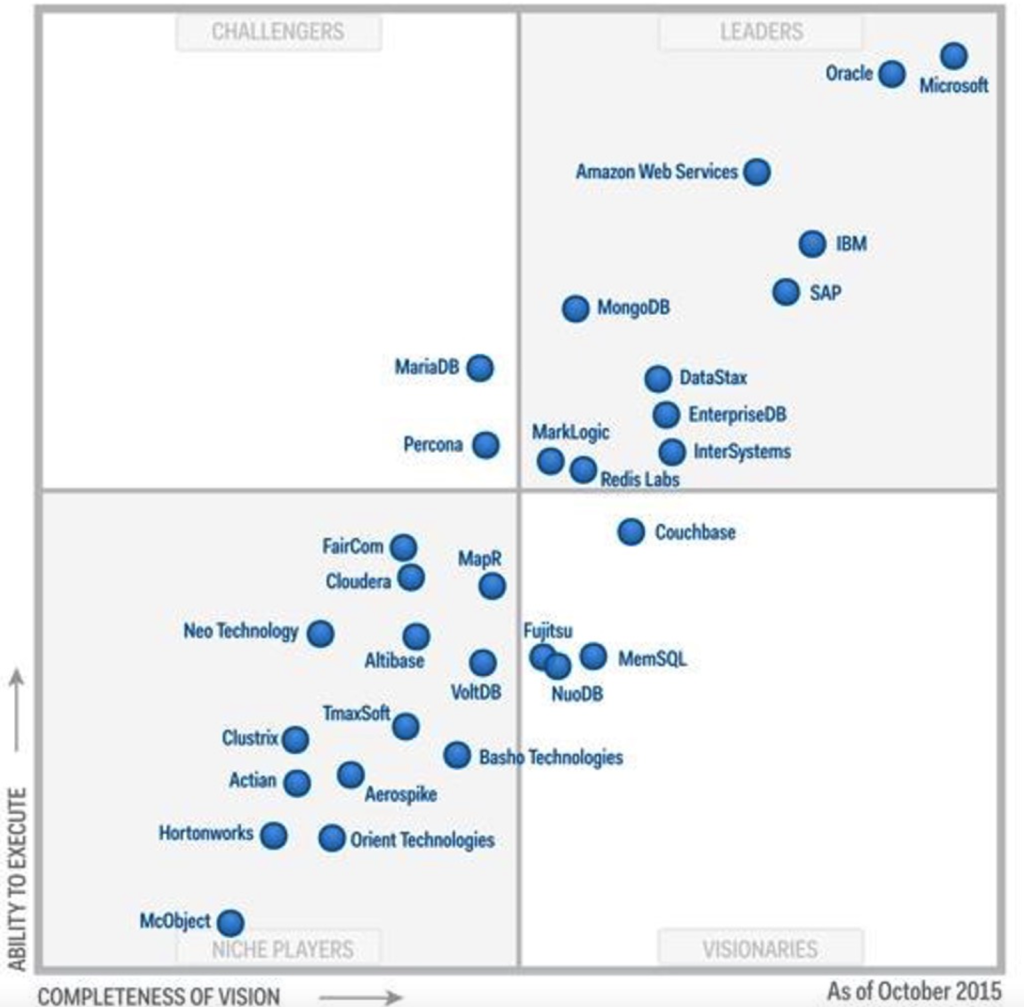
2015 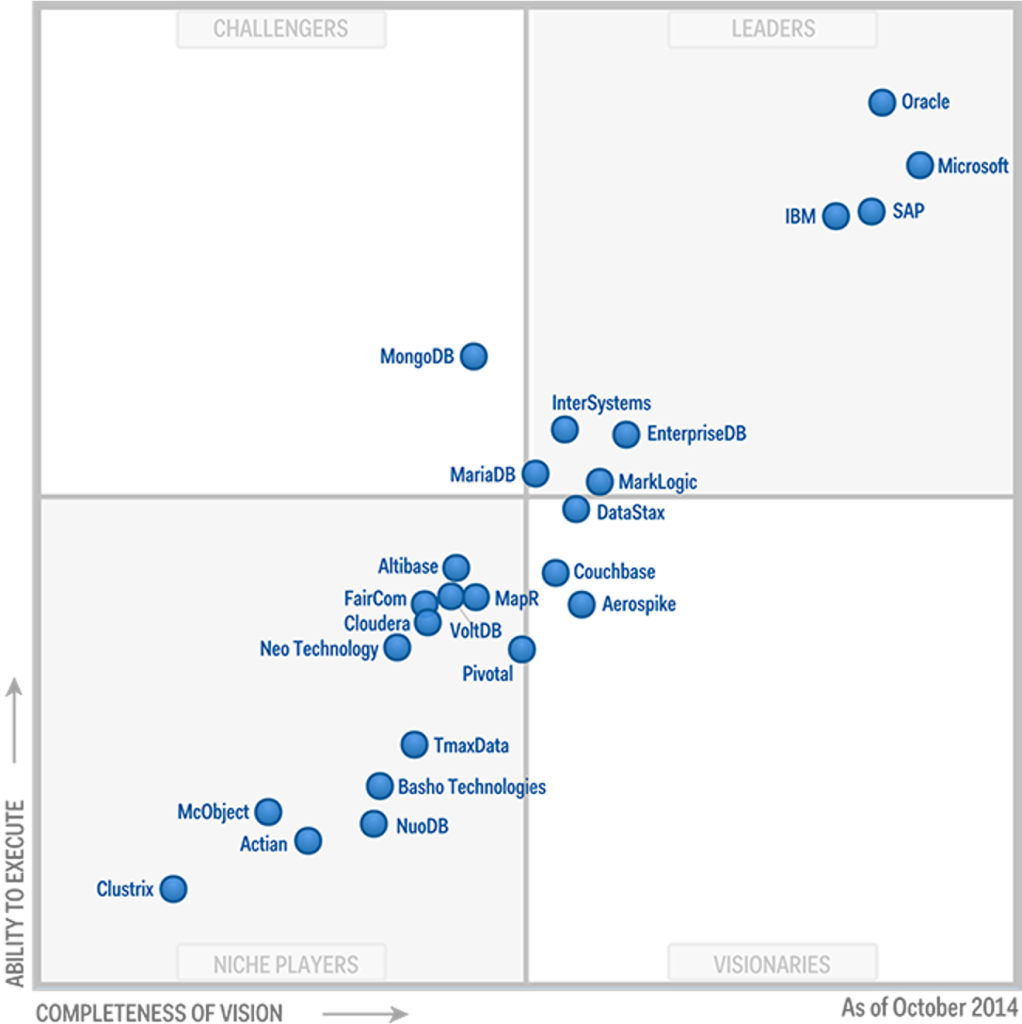
2014 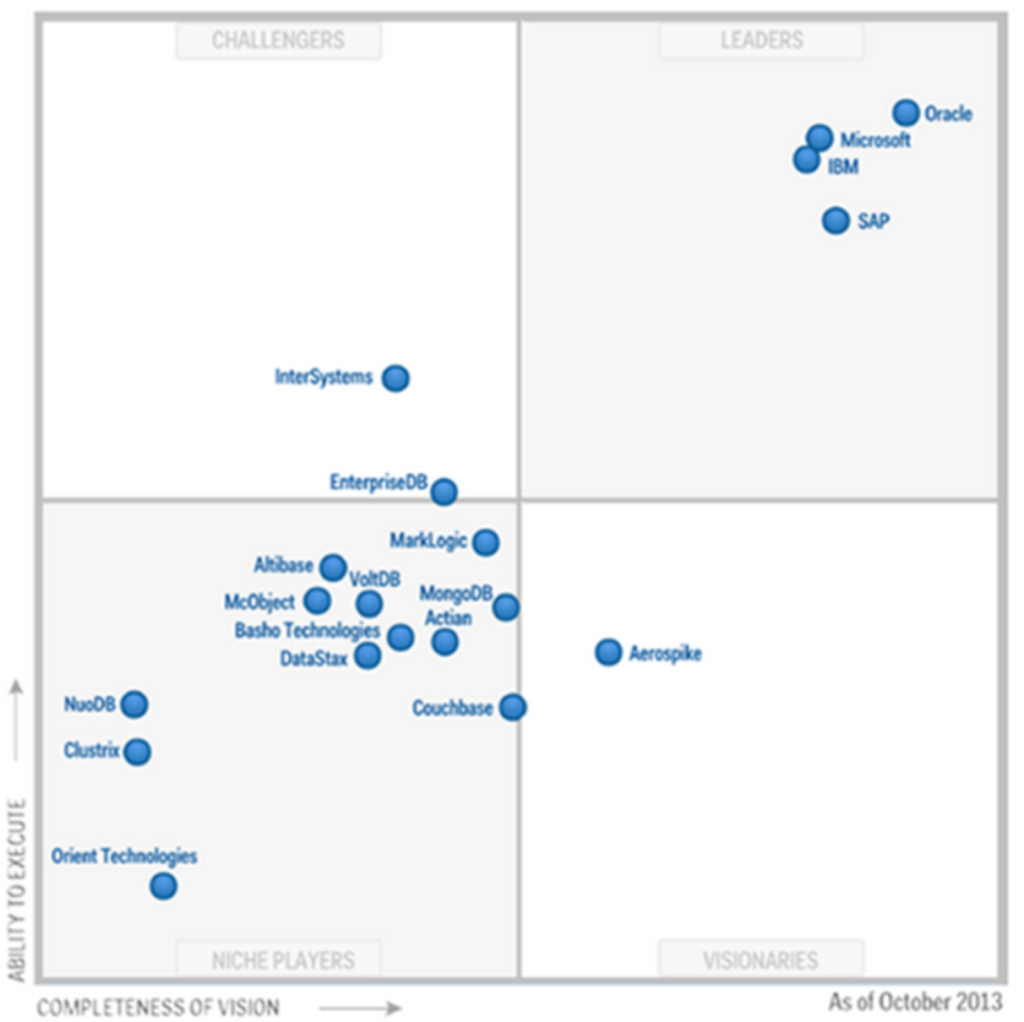
2013 其他
作者最近几年持续对 Gartner 云数据库魔力象限保持关注,历史相关文章包括:
-
在
Oracle官方文档Using LogMiner to Analyze Redo Log Files[2]中,对该功能有详细的介绍,包括了LogMiner的配置与使用、数据过滤、补充日志(Supplemental Logging)、使用示例等。Oracle 何时引入的LogMiner?
自 1999 年发布 Oracle 8i 的时候,正式引入 LogMiner 功能(参考:Redo Log Analysis Using LogMiner[1])。该功能支持以
SQL的形式分析redo中的数据,最初考虑的应用场景,主要还是偏于故障恢复、异常诊断、审计等,但是该功能的潜力很大,现在已经逐步成为Oracle CDC的主流方案之一。目前已经有很多的集成/同步工具都使用
LogMiner进行变化数据获取,虽然,目前官方依旧不推荐这么做,文档中的原文如下:“Note:LogMiner is intended for use as a debugging tool, to extract information from the redo logs to solve problems. It is not intended to be used for any third party replication of data in a production environment.”根据经验来看,
LogMiner用于数据集成并没有什么太大的问题。打开补充日志
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;查看归档日志
SQL> SELECT name FROM v$archived_log ORDER BY FIRST_TIME DESC FETCH FIRST 3 ROWS ONLY; NAME ---------------------------------------------------------------------------------------------------- /u03/app/oracle/fast_recovery_area/ORCLCDB/archivelog/2025_04_24/o1_mf_1_761_n0mbccbd_.arc /u03/app/oracle/fast_recovery_area/ORCLCDB/archivelog/2025_04_24/o1_mf_1_760_n0mbcc62_.arc /u03/app/oracle/fast_recovery_area/ORCLCDB/archivelog/2025_04_24/o1_mf_1_759_n0m6tdfp_.arc添加需要解析的日志文件
BEGIN DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/PATH_TO_YOUR_ARCHIVE/o1_mf_1_761_n0mbccbd_.arc', OPTIONS => DBMS_LOGMNR.NEW ); END; /例如,实际的SQL可能是如下的样子:
BEGIN DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/u03/app/oracle/fast_recovery_area/ORCLCDB/archivelog/2025_04_24/o1_mf_1_955_n0mwc01v_.arc', OPTIONS => DBMS_LOGMNR.NEW ); END; / o1_mf_1_955_n0mwc01v_.arc o1_mf_1_909_n0mv4sc3_.arc o1_mf_1_908_n0mv4ohs_.arc启动LogMiner
启动时,可以带不同的参数以指定
LogMiner不同的行为。使用在线数据字典启动
EXECUTE DBMS_LOGMNR.START_LOGMNR( - OPTIONS => DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG);使用日志中的数据字典启动
EXECUTE DBMS_LOGMNR_D.BUILD( - OPTIONS => DBMS_LOGMNR_D.STORE_IN_REDO_LOGS);获取
LogMiner中的变更数据获取变更数据
SELECT SCN, TIMESTAMP, OPERATION, SQL_REDO, SQL_UNDO, SEG_OWNER, TABLE_NAME, USERNAME FROM V$LOGMNR_CONTENTS WHERE OPERATION IN ('INSERT', 'UPDATE', 'DELETE') -- AND SEG_OWNER = 'TEST_USER' AND (TABLE_NAME = 'T2' OR TABLE_NAME = 't2') ORDER BY TIMESTAMP DESC FETCH FIRST 3 ROWS ONLY;退出 LogMiner
EXECUTE DBMS_LOGMNR.END_LOGMNR();解析未归档的 Redo 日志
除了解析归档之外,LogMiner 可以直接解析当前正在使用的 redo 文件。先根据小节“获取当前正在使用的redo文件”中的SQL获取当前正在使用的 redo 文件,然后在添加日志文件时,像上述添加归档一样添加即可。
BEGIN DBMS_LOGMNR.ADD_LOGFILE( LOGFILENAME => '/u04/app/oracle/redo/redo003.log', OPTIONS => DBMS_LOGMNR.NEW ); END; /使用上述(小结“获取变更数据”)的SQL可以获得如下的输出:
SCN TIMESTAMP OPERATION SQL_REDO ---------- --------- ------------ --------------------------------------------- 3175619 24-APR-25 INSERT insert into "SYS"."T2"("ID") values ('31'); 3175846 24-APR-25 INSERT insert into "SYS"."T2"("ID") values ('32');一些常见的 SQL
获取归档日志
获取最新的
ARCHIVE LOG的列表,以及对应的SCN号范围:SELECT FIRST_CHANGE#, TO_CHAR(FIRST_TIME, 'YYYY-MM-DD HH24:MI:SS'), NEXT_CHANGE# , TO_CHAR(NEXT_TIME, 'YYYY-MM-DD HH24:MI:SS'), NAME FROM V$ARCHIVED_LOG ORDER BY NEXT_CHANGE# DESC FETCH FIRST 3 ROWS ONLY;强制切换归档日志文件
ALTER SYSTEM SWITCH LOGFILE;获取当前正在使用的redo文件
SELECT A.GROUP#,A.MEMBER, B.STATUS FROM V$LOGFILE A JOIN V$LOG B ON A.GROUP# = B.GROUP# WHERE B.STATUS = 'CURRENT';参考
- [1] Redo Log Analysis Using LogMiner Oracle8i New Features@oracle.com
- [2] Using LogMiner to Analyze Redo Log Files 21c@oracle.com
-
Docker 大大简化了数据库的安装,特别是在产品测试阶段的时候,可以让开发者以最快速的方式体验技术产品,尤其是当这个技术产品已经非常复杂的时候。
Oracle 官方提供了哪些镜像
Oracle 镜像官方页面
Oracle 在官方站点中列出了所有支持的产品,以及对应的仓库列表。 Oracle 镜像仓库的官方页面:
仓库官方页: https://container-registry.oracle.com/

找到软件对应的子仓库
这里关注 Oracle Database 相关的仓库,故选择第一个仓库列表页。在这里可以看到有很多的子仓库,可以用于安装不同的 Oracle 数据库版本或组件:

选择版本与镜像站点
进入单个子仓库,在页面的最底下可以看到,该仓库有哪些版本的镜像可以使用,例如,这里选择了
express子仓库,在页面最底端找到支持的版本列表: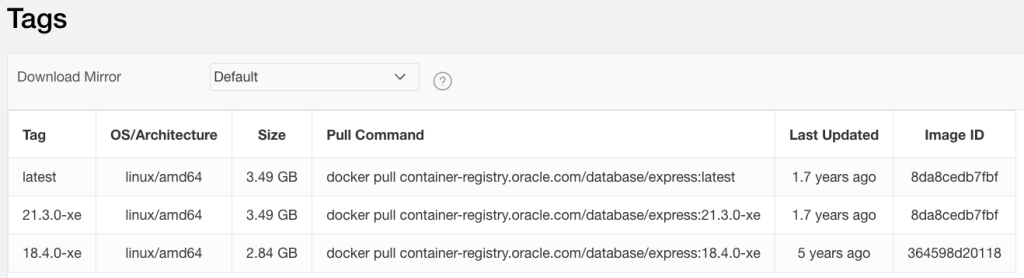
另外,这里还提供了一些可供选择的镜像列表,开发者可以根据自己的地理位置选择合适的镜像站点。
安装 Oracle 数据库
拉取镜像
docker pull container-registry.oracle.com/database/express:latest or: docker pull container-registry.oracle.com/database/express:21.3.0-xe or: docker pull container-registry.oracle.com/database/express:18.4.0-xe这里的测试选择了
express:18.4.0-xe版本进行安装。查看本地的镜像:docker image ls Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg. REPOSITORY TAG IMAGE ID CREATED SIZE container-registry.oracle.com/mysql/community-server 9.1 f1f889678a73 6 months ago 606 MB container-registry.oracle.com/database/express 18.4.0-xe 364598d20118 4 years ago 6.03 GB创建 Oracle 数据库的容器
docker container create \ -it \ --name oracle-18ex \ -p 1521:1521 \ -e ORACLE_PWD=oracledocker \ container-registry.oracle.com/database/express:18.4.0-xe启动容器
docker start oracle-18ex观察启动状态
docker logs -f oracle-18ex Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg. ORACLE PASSWORD FOR SYS AND SYSTEM: oracledocker Specify a password to be used for database accounts. Oracle recommends that the password entered should be at least 8 characters in length, contain at least 1 uppercase character, 1 lower case character and 1 digit [0-9]. Note that the same password will be used for SYS, SYSTEM and PDBADMIN accounts: Confirm the password: Configuring Oracle Listener. Listener configuration succeeded. Configuring Oracle Database XE. Enter SYS user password: **************** Enter SYSTEM user password: ************* Enter PDBADMIN User Password: ************* Prepare for db operation 7% complete Copying database files 29% complete Creating and starting Oracle instance 30% complete 31% complete 34% complete 38% complete 41% complete 43% complete Completing Database Creation 47% complete 50% complete Creating Pluggable Databases 54% complete 71% complete Executing Post Configuration Actions 93% complete Running Custom Scripts 100% complete Database creation complete. For details check the logfiles at: /opt/oracle/cfgtoollogs/dbca/XE. Database Information: Global Database Name:XE System Identifier(SID):XE Look at the log file "/opt/oracle/cfgtoollogs/dbca/XE/XE.log" for further details. Connect to Oracle Database using one of the connect strings: Pluggable database: bd127ae4faab/XEPDB1 Multitenant container database: bd127ae4faab Use https://localhost:5500/em to access Oracle Enterprise Manager for Oracle Database XE The Oracle base remains unchanged with value /opt/oracle ######################### DATABASE IS READY TO USE! ######################### The following output is now a tail of the alert.log: 2025-04-17T03:40:43.663079+00:00 XEPDB1(3):Resize operation completed for file# 10, old size 358400K, new size 368640K 2025-04-17T03:40:44.483587+00:00 XEPDB1(3):CREATE SMALLFILE TABLESPACE "USERS" LOGGING DATAFILE '/opt/oracle/oradata/XE/XEPDB1/users01.dbf' SIZE 5M REUSE AUTOEXTEND ON NEXT 1280K MAXSIZE UNLIMITED EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO XEPDB1(3):Completed: CREATE SMALLFILE TABLESPACE "USERS" LOGGING DATAFILE '/opt/oracle/oradata/XE/XEPDB1/users01.dbf' SIZE 5M REUSE AUTOEXTEND ON NEXT 1280K MAXSIZE UNLIMITED EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO XEPDB1(3):ALTER DATABASE DEFAULT TABLESPACE "USERS" XEPDB1(3):Completed: ALTER DATABASE DEFAULT TABLESPACE "USERS" 2025-04-17T03:40:44.930766+00:00 ALTER PLUGGABLE DATABASE XEPDB1 SAVE STATE Completed: ALTER PLUGGABLE DATABASE XEPDB1 SAVE STATE登录容器中的 Oracle 数据库
在上面的输出中可以看到,安装时会默认创建如下数据库:
Database Information: Global Database Name:XE System Identifier(SID):XE根据在上述
docker命令中指定的密码,则可以使用如下的命令登录数据数据库:docker exec -it oracle-18ex sqlplus sys/oracledocker@XE as sysdba or: docker exec -it oracle-18ex sqlplus system/oracledocker@XE登录后,会有如下提示输入:
Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg. SQL*Plus: Release 18.0.0.0.0 - Production on Thu Apr 17 03:56:27 2025 Version 18.4.0.0.0 Copyright (c) 1982, 2018, Oracle. All rights reserved. Last Successful login time: Thu Apr 17 2025 03:49:37 +00:00 Connected to: Oracle Database 18c Express Edition Release 18.0.0.0.0 - Production Version 18.4.0.0.0 SQL>授权协议与认证
如果你要使用 Oracle 数据库的企业版的话,在拉取镜像前则需要先登录官网“同意”相关的协议,并使用
docker login的方式进行认证,然后才可以拉取镜像。requested access to the resource is denied
如果没有认证或提前在官网统一协议,则可能遇到如下报错:
requested access to the resource is denied:docker pull container-registry.oracle.com/database/enterprise:12.2.0.1 Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg. Trying to pull container-registry.oracle.com/database/enterprise:12.2.0.1... Error: initializing source docker://container-registry.oracle.com/database/enterprise:12.2.0.1: reading manifest 12.2.0.1 in container-registry.oracle.com/database/enterprise: requested access to the resource is denied或者:
invalid username/password: authentication requireddocker pull container-registry-tokyo.oracle.com/database/enterprise:12.2.0.1 Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg. Trying to pull container-registry-tokyo.oracle.com/database/enterprise:12.2.0.1... Error: initializing source docker://container-registry-tokyo.oracle.com/database/enterprise:12.2.0.1: unable to retrieve auth token: invalid username/password: authentication required解决上述问题,首先需要登录Oracle镜像的官方站点,并同意相关协议,然后使用
docker login完成认证,后即可下载。登录Oracle仓库站点并同意协议
例如,如果需要下载“Oracle Database Enterprise Edition”,则需要先进入对应仓库站点:链接,并在页面的右侧栏点击协议并同意协议:
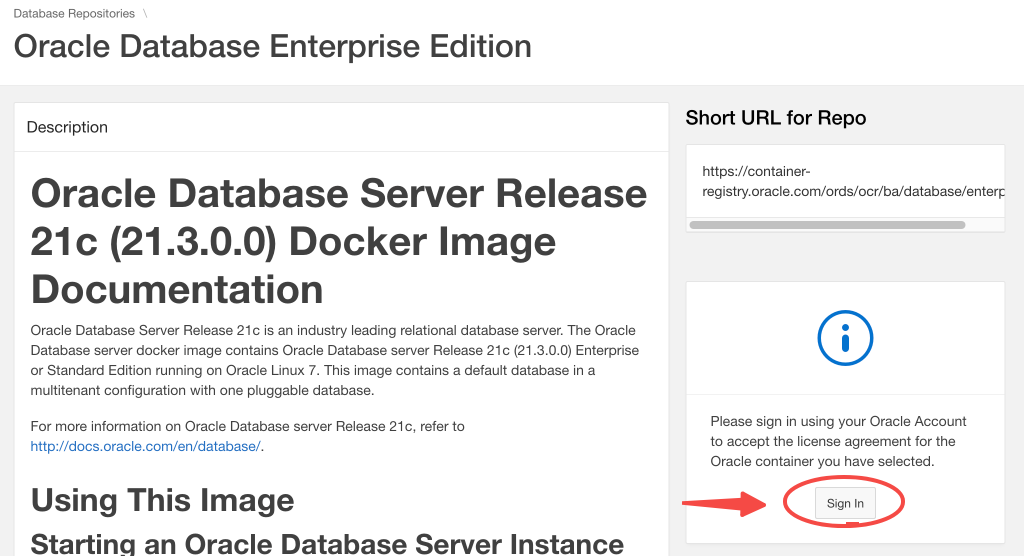
docker login
同意协议后,就可以使用
docker login登录账号并进行镜像的下载了。Enterprise Edition的Docker安装
在参考 Oracle 企业版官方文档(参考)进行安装部署的时候,在 AlmaLinux 部署时会遇到如下的问题:
docker exec -it oracle-1202ee sqlplus / as sysdba Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg. Error: crun: executable file `sqlplus` not found in $PATH: No such file or directory: OCI runtime attempted to invoke a command that was not found当前的绕过方案是,进入容器的
bash,然后再执行即可:[root@oracle-docker-test ~]# docker exec -it oracle-1202ee bash Emulate Docker CLI using podman. Create /etc/containers/nodocker to quiet msg. [oracle@8bb1ec09ec5e /]$ sqlplus / as sysdba SQL*Plus: Release 12.2.0.1.0 Production on Fri Apr 18 02:37:30 2025 Copyright (c) 1982, 2016, Oracle. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production SQL>创建容器时的参数
在创建容器的时候,可以使用命令行进行部分启动参数的配置。例如,默认启动时,是没有开启归档日志的(Archive Logs)的,则可以通过添加如下容器构建参数:
-e ENABLE_ARCHIVELOG=true完整的命令:
docker container create \ -it \ --name oracle-1202ee \ -p 1521:1521 \ -e ENABLE_ARCHIVELOG=true \ -e ORACLE_PWD=oracledocker \ container-registry.oracle.com/database/enterprise:12.2.0.1相关资源
- Oracle 镜像仓库官方站点:Oracle Container Registry
- Oracle 官方 GitHub 镜像列表:docker-images/OracleDatabase@GitHub
- Oracle 官方容器镜像使用说明:
-
Terraform 可以自动化的创建云端的资源,但是要想实现更高的灵活度,则需要更为灵活的使用Terraform的“Data Sources”能力。例如,在自动化的创建数据库时,云厂商允许创建的版本号是在动态变化的,例如,当前最新的允许的创建的MySQL版本通常是 8.0.40,但通常过了一个季度之后,就变成了 8.0.41。这时,对应的 Terraform 的脚本就需要调整或者传递参数就需要发生变化。而 Terraform 提供的 “Data Sources” 能力则可以很好的解决这个问题。
在 Oracle 的 Terraform 中可以使用 “Data Source: oci_mysql_mysql_versions” 实现该能力。
示例
首先使用 data 命令定义该对象:
data "oci_mysql_mysql_versions" "gmv" { compartment_id = oci_identity_compartment.oic.id }这里会获取该租户环境下支持的所有MySQL版本。
然后,再使用
output命令就可以获取并输出这些版本信息。详细的output命令如下:output "mysql_version" { value = data.oci_mysql_mysql_versions.gmv.versions }详细的输出示例如下:
mysql_version = tolist([ { "version_family" = "8.0" "versions" = tolist([ { "description" = "8.0.36" "version" = "8.0.36" }, { "description" = "8.0.37" "version" = "8.0.37" }, { "description" = "8.0.38" "version" = "8.0.38" }, { "description" = "8.0.39" "version" = "8.0.39" }, { "description" = "8.0.40" "version" = "8.0.40" }, { "description" = "8.0.41" "version" = "8.0.41" }, ]) }, { "version_family" = "8.4 - LTS" "versions" = tolist([ { "description" = "8.4.0" "version" = "8.4.0" }, { "description" = "8.4.1" "version" = "8.4.1" }, { "description" = "8.4.2" "version" = "8.4.2" }, { "description" = "8.4.3" "version" = "8.4.3" }, { "description" = "8.4.4" "version" = "8.4.4" }, ]) }, { "version_family" = "9 - Innovation" "versions" = tolist([ { "description" = "9.1.0" "version" = "9.1.0" }, { "description" = "9.1.1" "version" = "9.1.1" }, { "description" = "9.1.2" "version" = "9.1.2" }, { "description" = "9.2.0" "version" = "9.2.0" }, ]) }, ])获取特定大版本的各小版本
可以通过
data资源中新增filter模块以过滤出需要的对象。在 Terraform 中,关于 data 资源是否可以使用
filter,以及filter支持的完整度视乎并没有明确的说明。这需要更具不同的供应商的实现。常见的,在data resource中filter可以支持“列表匹配”、“通配符匹配”或者“正则匹配”。具体的匹配方式,则需要通过文档、或者测试区验证。添加带正则匹配的 filter
data "oci_mysql_mysql_versions" "gmv" { #Required compartment_id = oci_identity_compartment.oic.id filter { name = "version_family" values = ["8.0.*"] regex = true } }通过 HCL 语言获取最新的版本
output "latest_versions" { value = { for db_version in data.oci_mysql_mysql_versions.gmv.versions : db_version.version_family => sort([ for v in db_version.versions : v.version ])[length(db_version.versions) - 1] // 取排序后的最后一个版本 } }最后的输出如下:
latest_versions = { "8.0" = "8.0.41" "8.4 - LTS" = "8.4.4" "9 - Innovation" = "9.2.0" }参考链接
-
上周在 AWS re:Invent大会(类似于阿里云的云栖大会)上推出了新的产品 Aurora DSQL[1] ,在数据库层面提供了多区域、多点一致性写入的能力,兼容 PostgreSQL。并声称,在多语句跨区域的场景下,延迟只有Google Spanner的1/4。
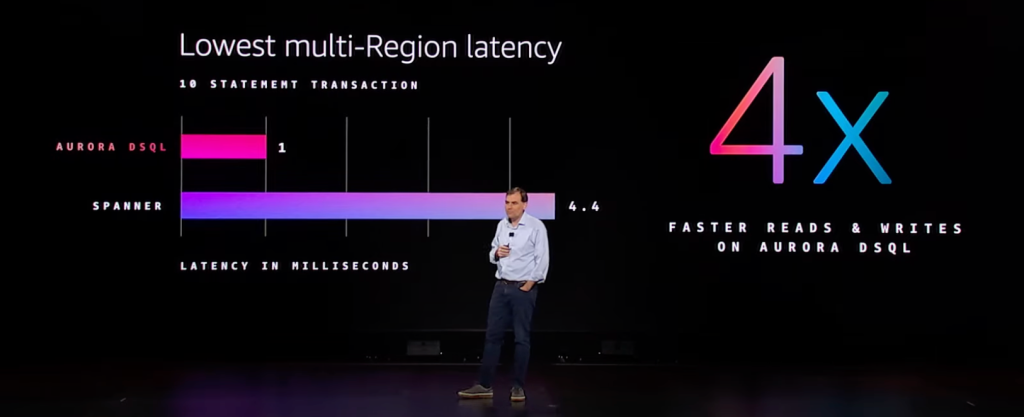
Aurora DSQL 提供了多可用区、多区域的多点一致性写入的内容。在技术层面,Aurora DSQL 通过把数据库的 log 模块和 block (或者说是cache)模块做了分离,从而更好的实现多点/多区域分布式能力,这与 Google AlloyDB 是比较类似的;此外,在跨区域强一致性实现上,则使用“Amazon Time Sync Service” [3] 来保障多个区域之间事务顺序的一致性。

在产品层面,分为两个场景,一个是 Aurora DSQL(region内模式)和一个 Aurora DSQL Global 模式(多 region 内模式)。在 Region 内场景下,相比于普通 Aurora PostgreSQL ,Aurora DSQL 在多个可用区内都可以提供强一致的读写接入点,而Aurora PostgreSQL只在一个可用区提供写,其他可用区仅提供只读节点。
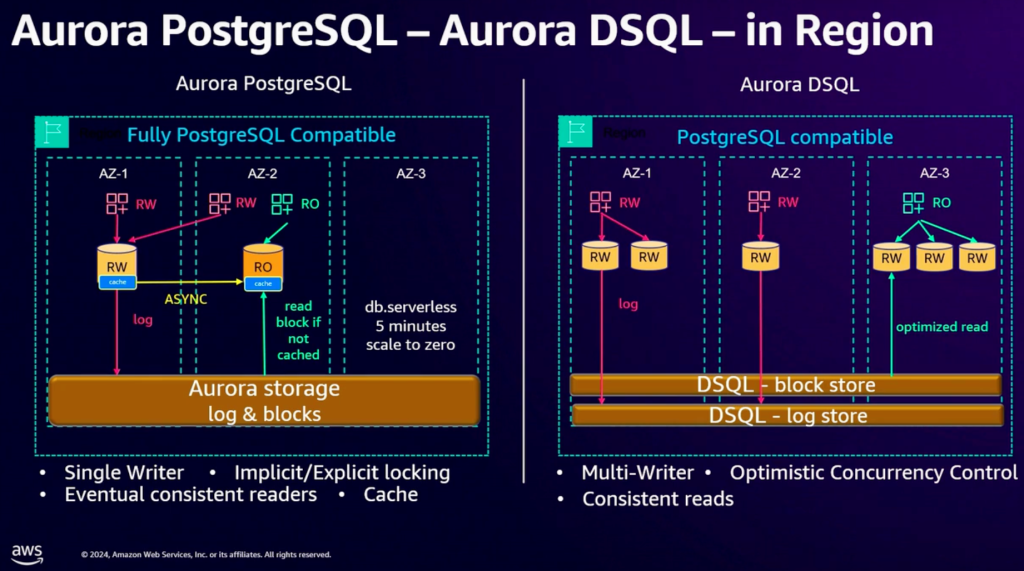
在跨 Region 的场景下,Aurora DSQL 则提供了同步的、跨区域的多点写入能力。这对于业务在全球分布的客户,则可以进一步的降低业务的复杂度。而原来的 Aurora Global Database 仅提供单个 Region 的写入能力,并且,在其他 Region 的读节点需要承受一定的数据访问延迟,这对于很多的在线业务场景可能是无法接受的,或者需要在应用层面做针对性的改造。
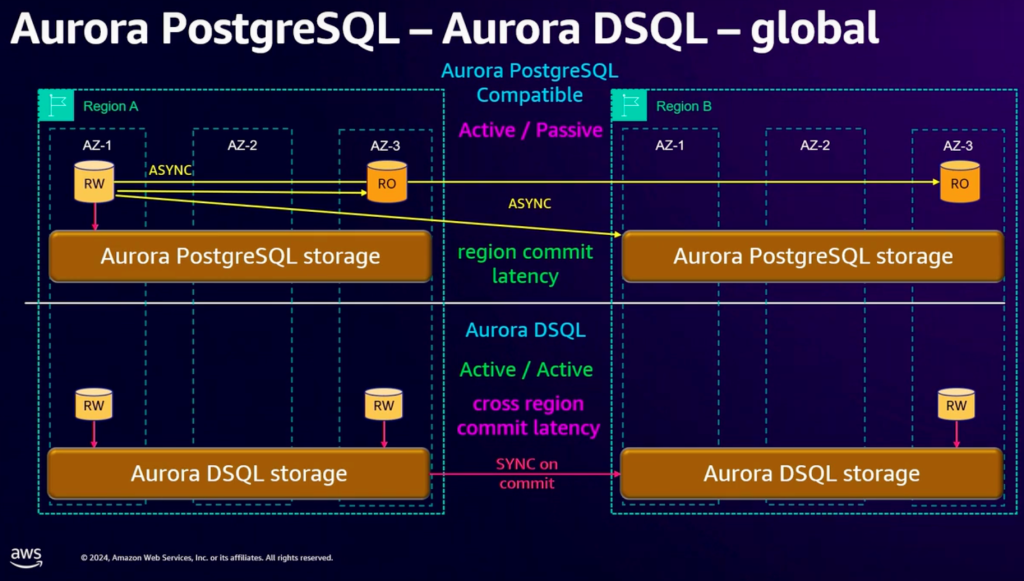
这是 Aurora 发布的10周年,AWS 依旧是创新、技术能力非常强的一家公司。此外,产品是在内测阶段,普通用户还无法体验。
参考文档
