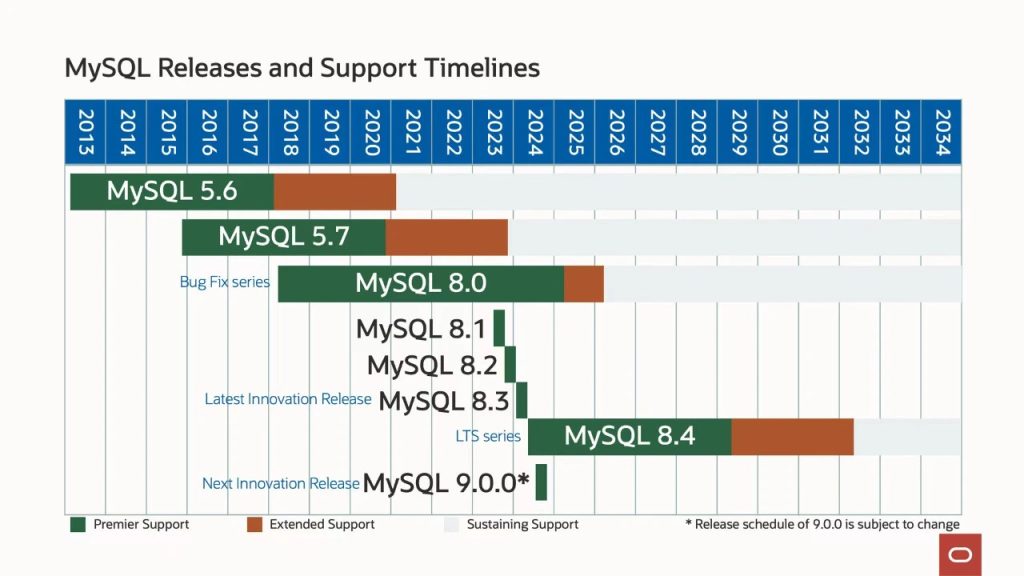
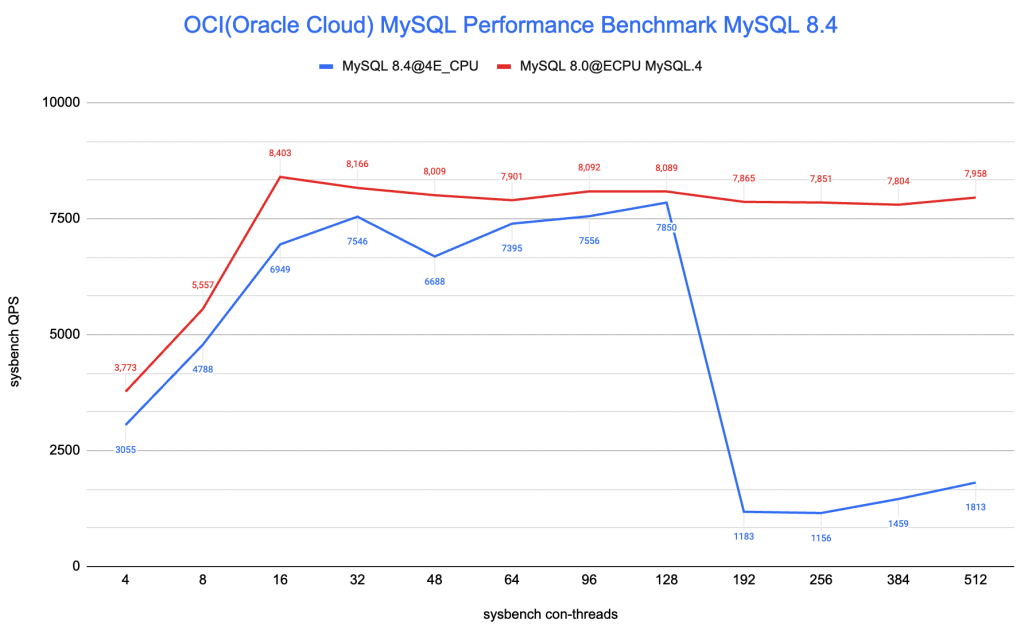
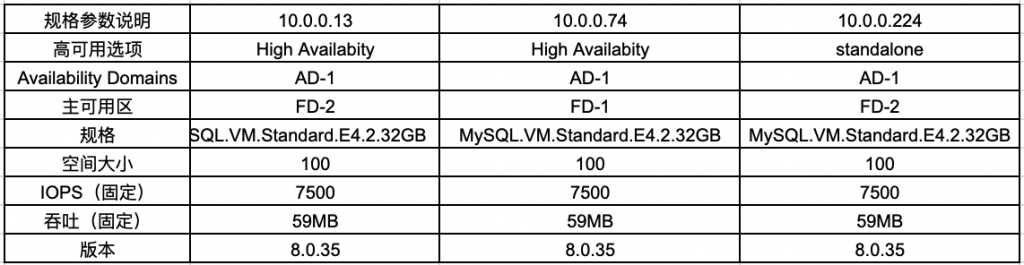
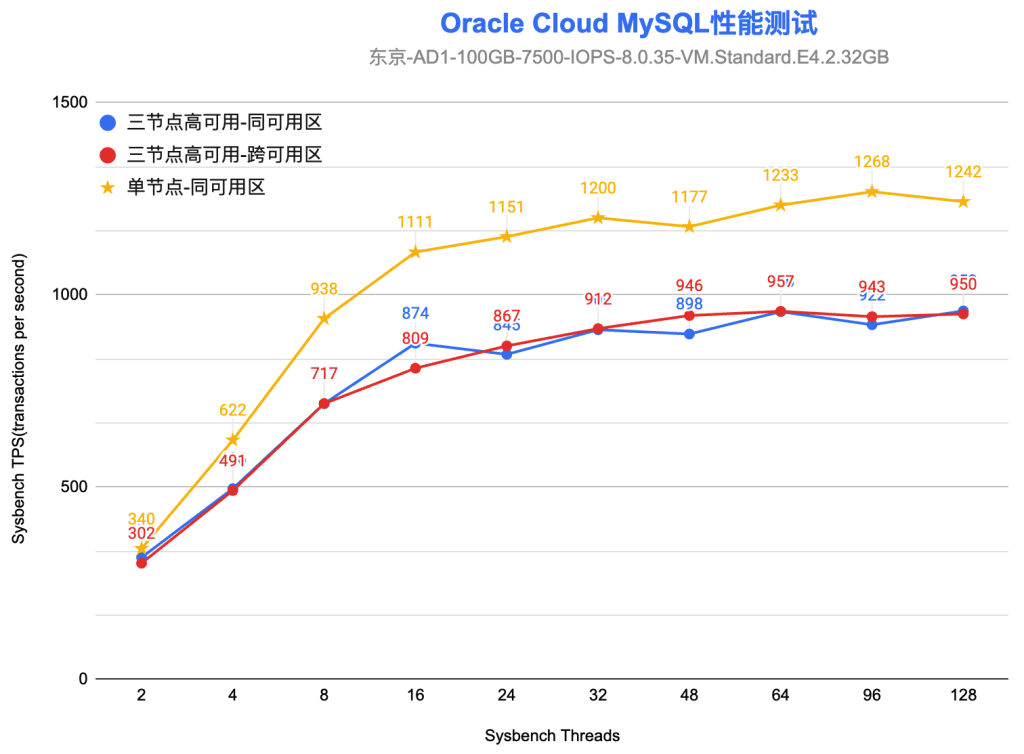
在开始创建Compute/Database资源之前,需要先完成认证,再将需要的基础资源准备好。基础资源包括VCN/Subnet等相关的网络基础组件。本文将通过简单的示例展示这些基础组件的创建。
目录
区域/Compartment/AD
和所有的Provider一样,我们会在Oracle Cloud的provider基础配置中配置好region。在资源创建的时候,核心资源都需要配置compartment_id,可以简单理解为,该资源属于哪个逻辑组(关于Compartment)。例如,一个典型的、简单的VCN的创建代码如下:
provider "oci" {
region = var.region
}
# 创建一个新的compartment,他的parent compartment是tenancy_id
resource "oci_identity_compartment" "oic" {
#Required
compartment_id = var.tenancy_id
description = "for database benchmark"
name = var.naming
}
resource "oci_core_vcn" "ocv" {
#Required
compartment_id = oci_identity_compartment.oic.id
cidr_block = "172.17.0.0/16"
display_name = var.naming
}创建一个具备“公网”能力的子网
这里说的“公网”能力,包括了两个方面:
- 一个是可以被公网访问,这样就可以ssh登录并管理
- 一个是可以访问公网,这样就可以通过wget/git/yum等工具安装软件
这里配置要求比较严谨,与AWS有一些类似。分为以下几个步骤:
- 创建一个VCN(oci_core_vcn),创建一个对应的子网(oci_core_subnet)
- 需要注意的是,在创建了VCN之后,OCI Terraform会默认的创建一组:默认的安全组(default_security_list_id)、默认的路由表(default_route_table_id)、默认的dhcp(default_dhcp_options_id)
resource "oci_core_vcn" "ocv" {
#Required
compartment_id = oci_identity_compartment.oic.id
cidr_block = "172.17.0.0/16"
display_name = var.naming
dns_label = var.naming
}
# Creates a subnet
resource "oci_core_subnet" "subnet_primary" {
availability_domain = data.oci_identity_availability_domain.oad.name
cidr_block = "172.17.1.0/24"
display_name = "domain_primary"
dns_label = "tfsubnet"
security_list_ids = [oci_core_vcn.ocv.default_security_list_id]
compartment_id = oci_identity_compartment.oic.id
vcn_id = oci_core_vcn.ocv.id
route_table_id = oci_core_vcn.ocv.default_route_table_id
dhcp_options_id = oci_core_vcn.ocv.default_dhcp_options_id
}- 创建一个具备互联网访问规则的网关
resource "oci_core_internet_gateway" "internet_gateway" {
compartment_id = oci_identity_compartment.oic.id
display_name = "InternetGateway"
vcn_id = oci_core_vcn.ocv.id
}
resource "oci_core_default_route_table" "route_table_for_internet" {
manage_default_resource_id = oci_core_vcn.ocv.default_route_table_id
display_name = "RouteTableForInternet"
route_rules {
destination = "0.0.0.0/0"
destination_type = "CIDR_BLOCK"
network_entity_id = oci_core_internet_gateway.internet_gateway.id
}
}- 最后,添加合适的端口访问规则:
resource "oci_core_security_list" "osl" {
compartment_id = oci_identity_compartment.oic.id
vcn_id = oci_core_vcn.ocv.id
display_name = "${var.naming}SecurityList"
ingress_security_rules {
protocol = "6" // tcp
source = "0.0.0.0/0"
stateless = false
tcp_options {
# source_port_range {
# min = 100
# max = 100
# }
# // These values correspond to the destination port range.
min = 22
max = 22
}
}
}Availability Domains
和Compartment一样,这是另一个Oracle Cloud上必须得,但是似乎必要性并不强的概念。在Oracle Cloud上,整体的资源位置从大到小:region -> Availability Domains -> Fault Domain。其中,Fault Domain可以理解为其他云的zone的概念,代表了一个IDC机房(可能是相邻的多个building),通常,3个Fault Domain构成一个Availability Domains。在一个Region通常只有一个Availability Domains,也有部分Region有2~3个Availability Domains。
在Terraform中,如果确定了Region,我们需要使用data.oci_identity_availability_domain获取对应availability_domain的信息:
data "oci_identity_availability_domain" "oad" {
#Required
compartment_id = oci_identity_compartment.oic.id
ad_number = 1
}创建计算资源(Compute)
选择合适的image
这里参考了example public_ip.tf@GitHub,使用了较为“直接”的方式(缺乏扩展性)获取需要镜像:
variable "instance_image_ocid" {
type = map(string)
default = {
# See https://docs.oracle.com/en-us/iaas/images/image/abf452f1-bf22-4837-b47b-79945ed26bee/
# CentOS-7
ap-tokyo-1 = "ocid1.image.oc1.ap-tokyo-1.aaaaaaaa4hzluwszvbv3m3m27pvly5qm6ldnjgibjxrexuhe4ky5ncijjsra"
}
}这里的ocid则是根据 Images@Oracle Cloud Infrastructure Documentation 列出的所有镜像选择而来。更具扩展性的做法应该是通过terraform data对象去获取。
计算实例的配置
在OCI中,计算实例的配置,相对来说是比较简单的:
# Creates an instance (without assigning a public IP to the primary private IP on the VNIC)
resource "oci_core_instance" "oi" {
availability_domain = data.oci_identity_availability_domain.oad.name
compartment_id = oci_identity_compartment.oic.id
display_name = var.naming
fault_domain = var.zone_primary
shape = var.vm_instance_type
shape_config {
memory_in_gbs = 2
ocpus = 1
}
source_details {
source_type = "image"
source_id = var.instance_image_ocid[var.region]
boot_volume_size_in_gbs = 50
}
create_vnic_details {
assign_public_ip = true
display_name = "Vnic${var.naming}"
subnet_id = oci_core_subnet.subnet_primary.id
hostname_label = var.naming
}
metadata = {
ssh_authorized_keys = var.publickey
}
preserve_boot_volume = false
}上面通过:
source_details描述了使用的镜像以及启动盘的大小create_vnic_details描述了VNIC的主要配置,包括所属子网、是否有绑定公网IP等metadata则描述了ssh的公钥信息,实现秘钥对登录
创建数据库实例
在OCI上创建MySQL实例比较简单,选项也不多,实际在通过Terraform配置也比较简单和顺利:
resource "oci_mysql_mysql_db_system" "om" {
display_name = var.naming
compartment_id = oci_identity_compartment.oic.id
availability_domain = data.oci_identity_availability_domain.oad.name
fault_domain = var.zone_primary
is_highly_available = true
admin_password = var.db_pass
admin_username = var.db_user
shape_name = var.rds_instance_type
data_storage_size_in_gb = 100
subnet_id = oci_core_subnet.subnet_primary.id
## this appear as optional in documentation
## but it is a must to add it
deletion_policy {
#Optional
# automatic_backup_retention = false
final_backup = "SKIP_FINAL_BACKUP"
is_delete_protected = false
}
}问题
400-InvalidParameter
参数值错误有很多,根据报错这里是automaticBackupRetention相关的参数值错误,对应在Terraform中是deletion_policy中的automatic_backup_retention配置项,该选项并不是必须的,暂时删除解决。
╷
│ Error: 400-InvalidParameter, Request contains an invalid value for 'com.oracle.oci.mysql.model.CreateDbSystemDetails$Builder["deletionPolicy"]->com.oracle.oci.mysql.model.CreateDeletionPolicyDetails$Builder["automaticBackupRetention"]'
│ Suggestion: Please update the parameter(s) in the Terraform config as per error message Request contains an invalid value for 'com.oracle.oci.mysql.model.CreateDbSystemDetails$Builder["deletionPolicy"]->com.oracle.oci.mysql.model.CreateDeletionPolicyDetails$Builder["automaticBackupRetention"]'
│ Documentation: https://registry.terraform.io/providers/oracle/oci/latest/docs/resources/mysql_mysql_db_system
│ API Reference:
│ Request Target: POST https://mysql.ap-tokyo-1.ocp.oraclecloud.com/20190415/dbSystems
│ Provider version: 5.42.0, released on 2024-05-19.
│ Service: Mysql Db System
│ Operation Name: CreateDbSystem
│ OPC request ID: ...
│
│
│ with oci_mysql_mysql_db_system.om,
│ on rds.mysql.tf line 6, in resource "oci_mysql_mysql_db_system" "om":
│ 6: resource "oci_mysql_mysql_db_system" "om" {
│参考链接
- Regions and Availability Domains@Oracle Cloud Infrastructure Documentation
- Data Source: oci_identity_availability_domain@OCI Terraform
- Terraform: Create a Virtual Cloud Network@Oracle Cloud Infrastructure Documentation
- Terraform: Create a Compute Instance@Oracle Cloud Infrastructure Documentation
- example public_ip.tf@GitHub
- oci_mysql_mysql_db_system@Terraform Docs