去年11月,Amazon RDS推出的新的形态:Multi-AZ Cluster(三可用区三节点)。相比“原来的多AZ”(两个可用区)架构,新的Cluster模式是三节点架构,提供了更低的事务延迟,同时有更好的读扩展能力。国内的云厂商中,阿里云和腾讯云很早就有了三节点形态,一起看看,他们有哪些异同,在实际的业务场景中,哪些情况可以选择这种形态。
AWS RDS三节点(Multi-AZ Cluster)是什么?
这里将其主要特点概括如下:
- 这是一种3*AZ部署模式,而原来的Multi-AZ是2AZ部署或者单AZ部署。
- 使用了数据库的逻辑复制,而原来的双AZ使用的是EBS层的复制,这就使得Cluster的副本节点都可以直接提供读能力,有更好的读扩展能力。
- 使用了类似MySQL半同步的复制技术,事务日志网络到达其中任意一个副本主节点事务就可以提交,所以主节点上的事务延迟会降低,性能会提升(对比基于EBS的两节点)。
- 支持Graviton 2的规格和NVMe-based SSD存储,可以提供更好的性能。
- 同时支持MySQL和PostgreSQL两个引擎。
与阿里云、腾讯云数据库三节点的区别
阿里云RDS提供的“三节点企业版”,支持MySQL引擎,通过Paxos协议(或其变种)同步。相比Amazon的方案,其中一个节点使用了日志存储,成本可以更低;三个节点,只有一个节点提供服务。腾讯云MySQL也支持三节点版本,使用了半同步复制,可以选择异步、半同步或者强同步三种模式,也只有一个节点可以提供服务。
相比AWS,阿里云与腾讯云的三节点模式都可以由用户自由选择可用区分布,即可以都在一个可用区,也可以分布在两个或三个可用区,给了客户更强的灵活性。
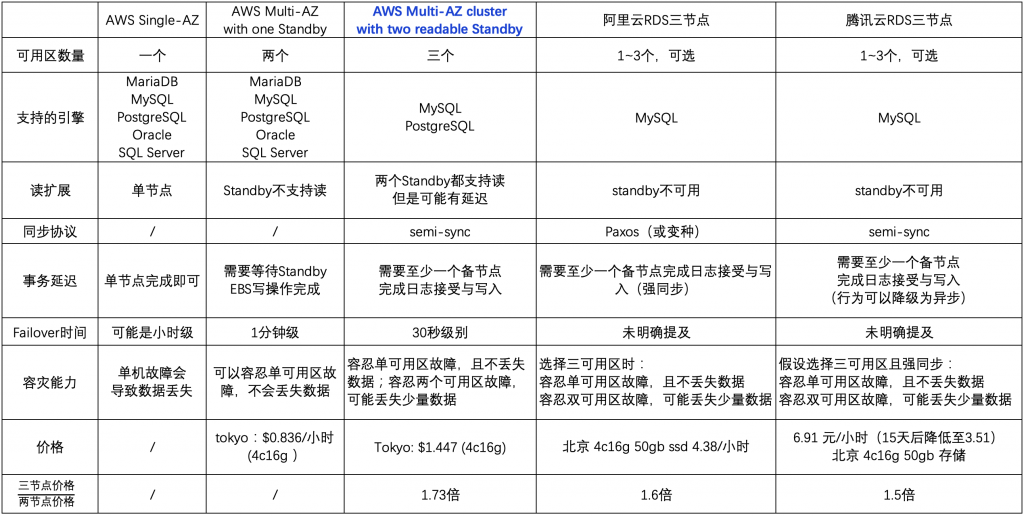
AWS RDS三节点与两节点的架构差异
官方给出了较为详细的产品架构图,如下:
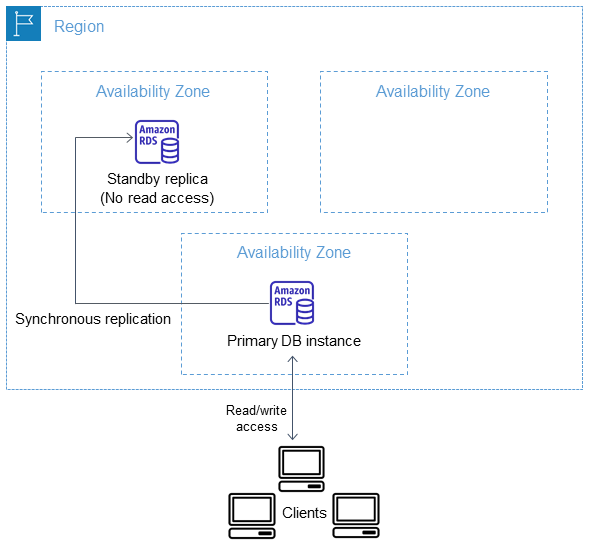
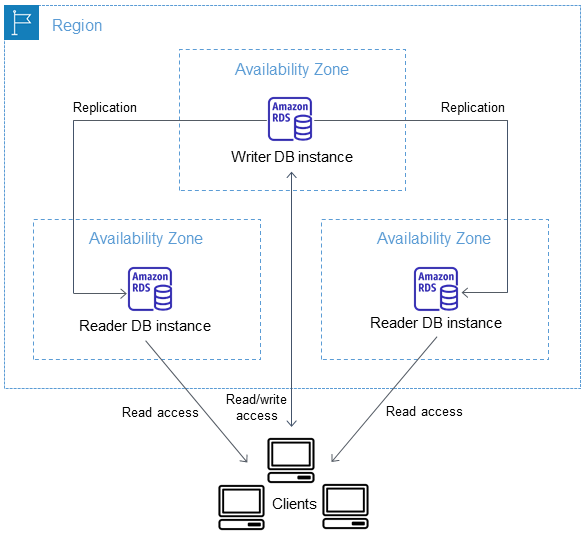
可以看到,原来的RDS多AZ(两节点)部署,使用了EBS底层同步复制,需要EBS复制完成后,主节点的事务才能提交,也因为是依赖底层复制,所以Failover的时间也会更长一些。当然,这种架构的优势在于简单,任何的数据库都可以使用,所以支持的数据库种类比较丰富。新的“三节点”形态则需要在内核层做一些改造,通用性要更差一些。这也是为什么这种架构目前支持的数据库种类还比较少,因为每一种数据库的支持在日志/复制/事务层都需要一定的改造,而且对于商业闭源数据库可能无法支持。
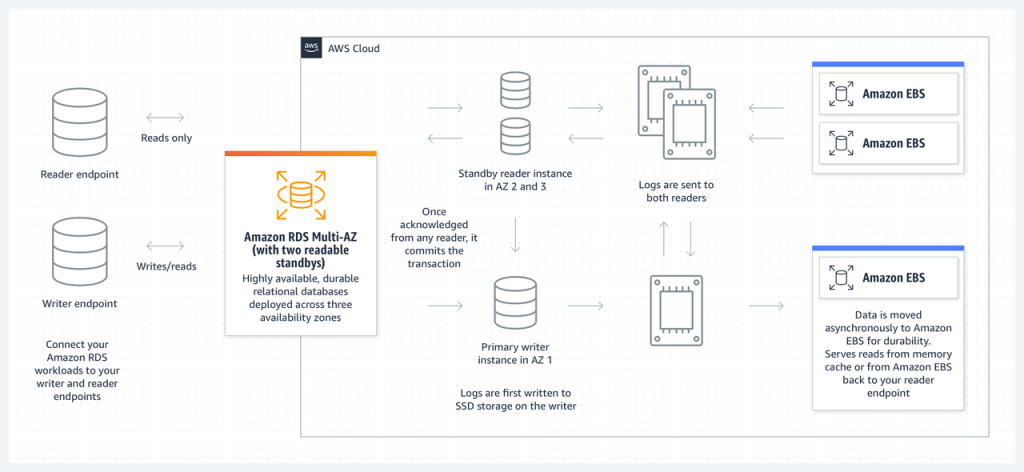
再补上两个更细致的架构对比图:
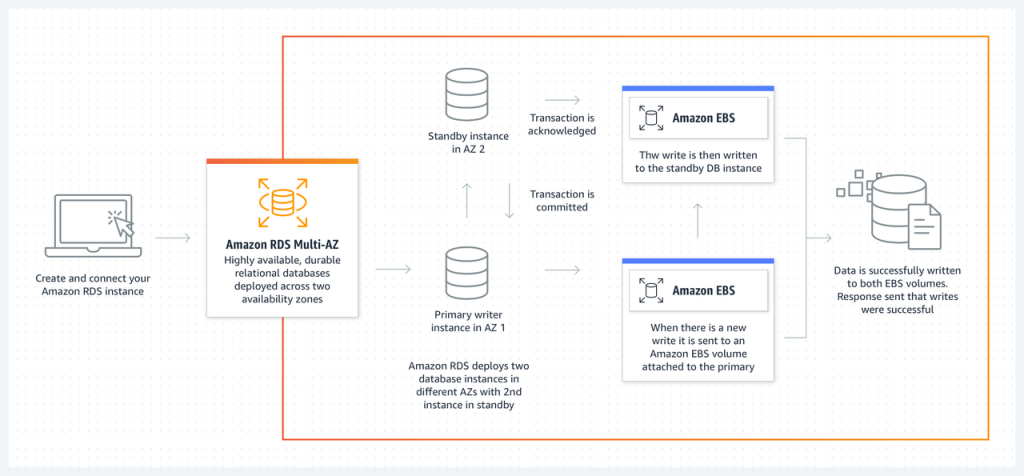
为什么AWS的三节点事务延迟更低,读扩展能力更强?
阿里云很早就支持了三节点企业版,相比两节点高可用版本来说,数据安全性更高,其代价是性能也有一定程度的下降、事务延迟也会略微增加。那为什么AWS三节点却声称提供了更低的事务延迟,更强的读扩展能力呢?
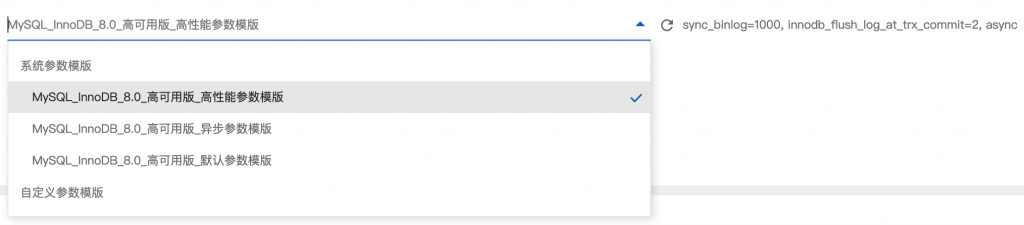
阿里云、腾讯云也都有自己的三节点形态。通常在底层使用Paxos(或者变种)的同步日志同步协议进行同步,以阿里云为例,使用了Paxos协议做日志同步,并且其中一个节点为日志节点,所以除了主节点,其他节点也就无法提供服务了(参考:MySQL · 产品特性 · RDS三节点企业版的高可用体系)。阿里云的两节点高可用版本(默认情况下选择的高性能参数模板)选择的async模式的,也就是主备并不是强同步的,而阿里云的三节点企业版则是同步的,所以自然三节点的性能会差一些。
但,AWS的两节点(普通的多可用区模式)默认就是主备强同步的,使用的是EBS层面的物理数据块的强同步复制(参考:Amazon RDS的同步复制是如何实现的 – Life, Database and Cloud Computing)。相比,相比阿里云使用的异步复制,AWS RDS两节点性能”应该”会更差的,当然,其安全性也会更高。AWS RDS的三节点则使用了逻辑复制,并且提供了两个备节点,其中任何一个成功则主库的事务就可以提交了。相比,两节点,数据多了一个“通路”,所以事务延迟可能更低。另外,AWS RDS的两节点使用了EBS层的物理复制,所以导致备节点无法直接提供服务,所以读扩展性也就没有三节点好了。
常见的业务场景
从上面的价格列表和产品功能说明可以看到,三节点相比两节点,提供了更高的灾难容忍级别,都可以接收单个可用区故障,依旧不丢失任何数据,但是价格也贵了约70%。所以,对于数据可靠性和一致性要求更高的场景,例如金融业务或其他有更强合规要求的业务,可以考虑使用该形态。
另外,相比阿里云和腾讯云,AWS RDS的三节点则有更广泛的适用场景。除了上述金融类场景外,普通的、读压力非常大(且介绍一定的延迟)的业务场景也可以使用,理论上,AWS RDS三节点价格虽然贵了70%,但是读的能力应该是原来的3倍左右。所以,如果是读密集型的场景,该形态的性价比还是比较高的。如果,业务恰好数据一致性要求非常高,合规上要求三可用区,又有比较大的读扩展性要求,那么就是这个形态的完美场景了。
创建与使用AWS RDS三节点
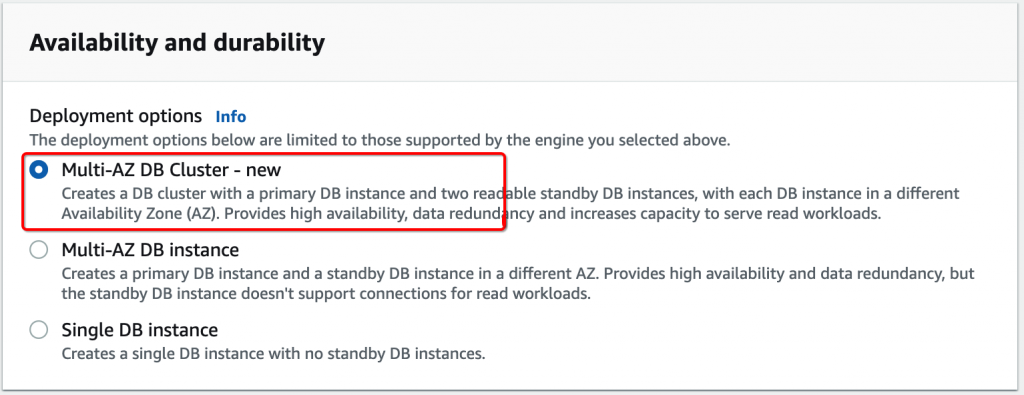
在创建RDS的时候,只需要选择Multi-AZ DB Cluster选项就可以了。实例完成创建后,可以看到集群有三个节点,分别在三个可用区。
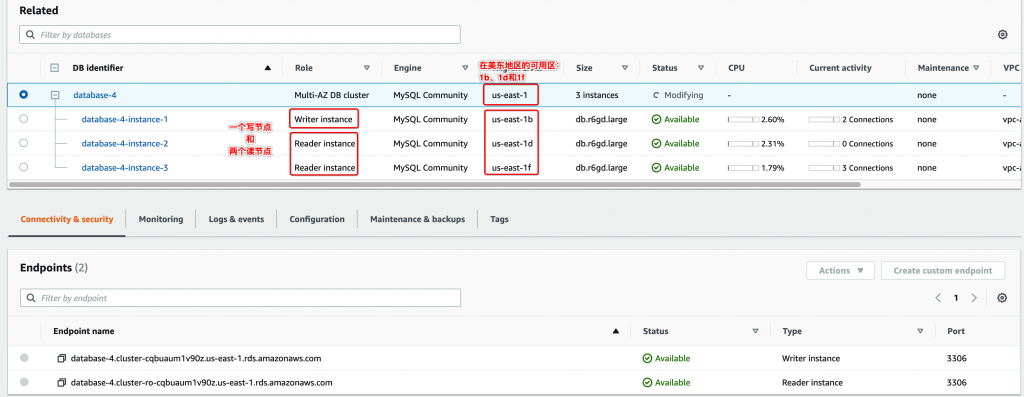
在完成实例创建之后,该集群提供了三个Endpoint给用户使用。Multi-AZ Cluster提供两类Endpoint:
- 集群写入的Endpoint、集群只读的Endpoint
- 单个写实例的Endpoint、单个只读实例的Endpoint(两个)
其中,集群级别的Endpoint是稳定的,在集群发生切换时,这两个Endpoint形态不会改变。而单实例级别的Endpoint则会随着切换后,角色发生变化(如从可写到只读),这些Endpoint应该尽量用作诊断,而不是实际业务。
另外,集群只读Endpoint会将流量发送到两个读节点中的一个(The reader endpoint connects to either of the two reader DB instances, which support only read operations),所以,读取的数据可能会出现延迟。
有了两节点,又做三节点,是在卷吗?
在两节点情况下,如果一个节点发生灾难需要重建,通常当数据量较大的时候,这个重建时间会比较长,这时候主节点通常都是以单节点的方式提供服务,如果重建时间超过十小时,那么仅单节点提供服务的风险还是比较高的。
从架构演进来看,国内云厂商做三节点和AWS RDS做三节点的逻辑是不一样的。国内厂商是因为,两节点数据可靠性有一些瑕疵(换来的是高性能),在此基础上推出三节点解决这个瑕疵(付出的代价也是性能)。
而AWS RDS的两节点的数据可靠性已经非常高了(付出了性能的代价),而三节点是通过逻辑复制、并且新增一个复制节点的方式(两个节点中任意一个复制成功则成功)提升了可靠性的同时,是提升了性能的。所以,AWS RDS的三节点,相比自己的两节点,性能更好了,读扩展能力更好了,适用的场景也更加广泛。
一些补充说明
- 阿里云RDS的两节点形态,提供了三种参数选择:
- 一种是异步,高性能:sync_binlog=1000, innodb_flush_log_at_trx_commit=2, async
- 一种是同步(使用了半同步技术)
- 另一种是异步,但是设置了”双1″,单个节点安全性更高
在本文档的描述中,为了简化,提到阿里云两节点形态时,通常是指默认的第一种形态,也就是异步高性能模式。
- 腾讯云的按量付费会在使用第4天和15天之后,计费价格会大幅度下调,所以上面按量付费价格并不能直接比较。
- 华为云RDS暂时不支持三节点形态。
- 在Amazon RDS站点中,Multi-AZ Cluster形态有时也被称为“Readable standby instances”。
- 为了控制主节点和备节点的延迟,可以通过参数rpl_semi_sync_master_target_apply_lag控制,当延迟达到该参数设置的值的时候,RDS会通过流控的方式限制主节点的写入。
- 虽然,文档中并没有明确指出,但是猜测Multi-AZ Cluster应该是基础MySQL的半同步做的实现,相比其他一致性协议,这种实现,在读取数据的如果从standby读取,那么就会有不一致。所以,需要一致性读,则需要总是从写节点读取数据。
Leave a Reply