概述:mysqldump是MySQL官方自带的备份工具,被广泛使用着。本文详细介绍了如何使用mysqldump获得一个一致的备份,以及可能遇到的一些问题。
1. 是什么备份的一致性?
一致性对于备份来说是非常重要的,如果一个备份不具备一致性,那么再恢复之后,可能会让软件出现各种奇怪的问题。我们来详细看看什么是备份的一致性,例如,一个备份流程中,首先耗时一分钟(12:00:00-12:01:00)完成了用户表U表备份,然后继续其他业务表A、B等的备份,于此同时,业务线程开始向用户表U写入新注册用户X的信息,接着,业务线程又向事件表E写入X用户的事件Y信息。接着,备份线程在完成其他业务表之后,开始并完成备份事件表E。
如果不考虑一致性,在备份事件表E的时候,会记录X用户的事件信息,但是在用户表U中却没有该用户的注册信息,也就出现了不一致的数据。如果事件U表记录的是,企业核心数据,例如账务、计费等信息,恢复这样数据,则难以达到备份与恢复的目的。

一致性的备份是指,所有备份中的数据,可以对应到数据库在某一时刻的状态。在上面的案例中,就要求,所有备份的数据与用户表U开始备份时刻的数据处于同一个状态。
2. mysqldump备份的一致性保障方式
2.1 使用 –lock-tables, -l
默认情况下,参数–opt是打开的,所以,不加任何相关参数的话,会默认带上参数–lock-tables,该参数,会在备份某个数据库之前,将该数据库的所有的表都加上锁,阻止所有的写入操作,所以,总是可以让单个数据库保持一致的状态。
2.2 使用–lock-all-tables, -x
另一个加锁的参数是–lock-all-tables, -x,与–lock-tables差别在于,该参数是在备份任务开始时,将需要备份的所有数据库的所有表,都加上锁,阻止所有的写入操作,所以,使用该参数,就可以获得整个实例级别的一致性,而–lock-tables参数是可以获得单个数据库级别的一致性。当然,如果你的实例中,数据库数量非常多,而且关联性并不大,则还是应该尽量使用-l参数,避免加锁时间过长。
2.3 使用最常用 –single-transaction
–single-transaction参数应该是mysqldump备份中最有用的参数了。对于InnoDB表,使用该参数一方面可以获得一致性的数据,另一方面,也不需要在备份期间持续的对数据库进行加锁操作。
一般来说,使用了该参数,就可以获得一个一致的备份,并且在备份过程中,无需阻塞读取或者写入操作。
3. 使用–single-transaction的一些例外情况
因为MySQL两层架构设计,导致了Server层和引擎层在很多功能上并不能很好的契合。在使用–single-transaction参数备份时,如果数据库层正在执行某些DDL,那么还是可能会出现不一致。
在mysqldump的文档中也明确提到,如果在mysqldump执行过程中,数据库上执行了ALTER TABLE, CREATE TABLE, DROP TABLE, RENAME TABLE, TRUNCATE TABLE等DDL,还是会有不一致出现。因为文档写得比较简单,而一致性又是一个比较大的问题,所以,这里详细探讨一下这种情况。
3.1 –single-transaction备份时,如果有ALTER TABLE,数据是否还一致?
在备份的过程中,如果有部分表执行了ALTER TABLE操作,这部分表是否还可以正常备份呢?这样的备份是否有一致性?
简单的回答,在使用–single-transaction参数备份时,如果执行了ALTER TABLE,并且该操作属于COPY(或INPLACE)类型,那么可能会导致备份数据出现错误,事实上,可能会导致,该表中的数据无法被备份出来。
这是一个mysqldump的限制。因为与MySQL事务、DDL实现机制、InnoDB事务机制都有较深的关系,所以,并不容易绕过,这个问题的底层原因在很早就已经在Bug系统中汇报了,但是一直都没有好的、彻底的修复策略,参考:MySQL Bug#28432。当然,也可能是修复的代价太高,而收益比较小。
从原理上,简单的来说,当对InnoDB表做DDL操作时,而且该DDL是一个COPY类型的(ALGORITHM为COPY的时候),MySQL会先对该表加上一个全局的锁,不允许任何的写操作,然后新建好一个临时表(新的结构),然后将原表中的数据拷贝到新的临时表中,完成拷贝之后,然后再将原表删除,并将新的临时表重命名为原表。在这个过程中,所有新拷贝的数据都使用新的事务ID,而原表的数据又被删除了。所以,在这个DDL之前开始的事务,都不再能够读取DDL之后的新表的数据,即便这个新表的数据本身并没有被其他任何事务修改。从事务一致性的角度来看,这应该是不可以被接受的,使用了Repeatable Read隔离级别的事务,在某个时刻开始之后,能够读取的数据,应该总是一致的。所以,也比较明确,这就是MySQL的一个已知的限制。
3.2 ALTER语句的ALGORITHM到底是COPY、INPLACE,还是INSTANT呢?
那么一个ALTER TABLE语句的DDL到底是COPY、INPLACE,还是INSTANT呢?这个问题没有一个简单答案,也不再本文的讨论范围之内,详细内容可以参考:
另外,因为INSTANT是8.0版本才引入的,所以,5.7的版本要么是COPY、要么是INPLACE。
3.3 延伸说明,ALTER语句对于事务隔离性的破坏
某些ALTER语句执行时,是会破坏事务的隔离性的。这里也做了一个简单的测试验证:
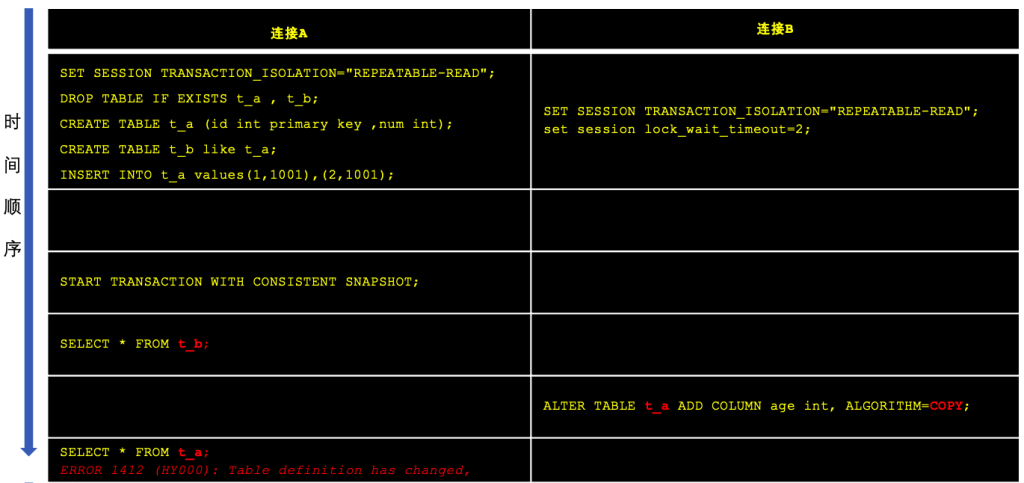
在上面的例子中可以看到,如果在实际的备份中,先备份t_b,而另一个线程对t_a进行了ALTER操作的DDL(注:并且是ALGORITHM为COPY)时,备份线程再读取t_a的数据,就会失败,在实际的mysqludmp备份中,就只能备份t_a的表结构(show create table可以执行,且显示的是新的表结构),但无法备份该表的数据。
3.4 –single-transaction与其他DDL语句
除了ALTER语句之外,其他还有CREATE TABLE, DROP TABLE, RENAME TABLE, TRUNCATE TABLE等语法,都会破坏InnoDB RR隔离级别下的一致性,所以也都会有类似的问题。这些DDL相比ALTER要更简单一些(没有ALGORITHM选项),如果在mysqldump执行过程中执行这些DDL(如果是上面示例中的顺序),也会有类似的不一致问题,这里就不再详述。
3.5 –single-transaction与FLUSH TABLES WITH READ LOCK
mysqldump在–single-transaction和–master-data(–source-data)结合使用的时候,会通过FTWRL命令将数据库锁住,并获取全局的、一致的日志位点。但是,因为MySQL的设计原因,FTWRL比较容易导致数据库阻塞,尤其是数据库的负载比较大的时候,参考:
- Xtrabackup: Handling FLUSH TABLES WITH READ LOCK
- Introducing backup locks in Percona Server@Percona 2014年
- FLUSH Statement@dev.mysql.com
- MySQL Bugs#71017 :mysqldump creates useless metadata locks
- FLUSH TABLE WITH READ LOCK详解@天士梦
所以,如果备份发生在主库,且负载比较大,则会有一定概率阻塞数据库,导致服务不可用。
4. 小结
虽然,说了这么多问题。但是,总体上mysqldump和–single-transaction组合起来用,通常都能够帮助你获得一份有效的、一致的备份。
但是,如果你是负责一个大型系统(数据库非常多)的备份,数据库实例的数量非常多,开发人员也非常多,那么虽然概率小,但依旧一定会遇上这些情况。希望本文能够帮助你理解这种现象,以及尽量避免这种情况的发生。例如,可以考虑在备库/副本上备份,或者使用Xtrabackup的物理备份作为补充等。
Leave a Reply