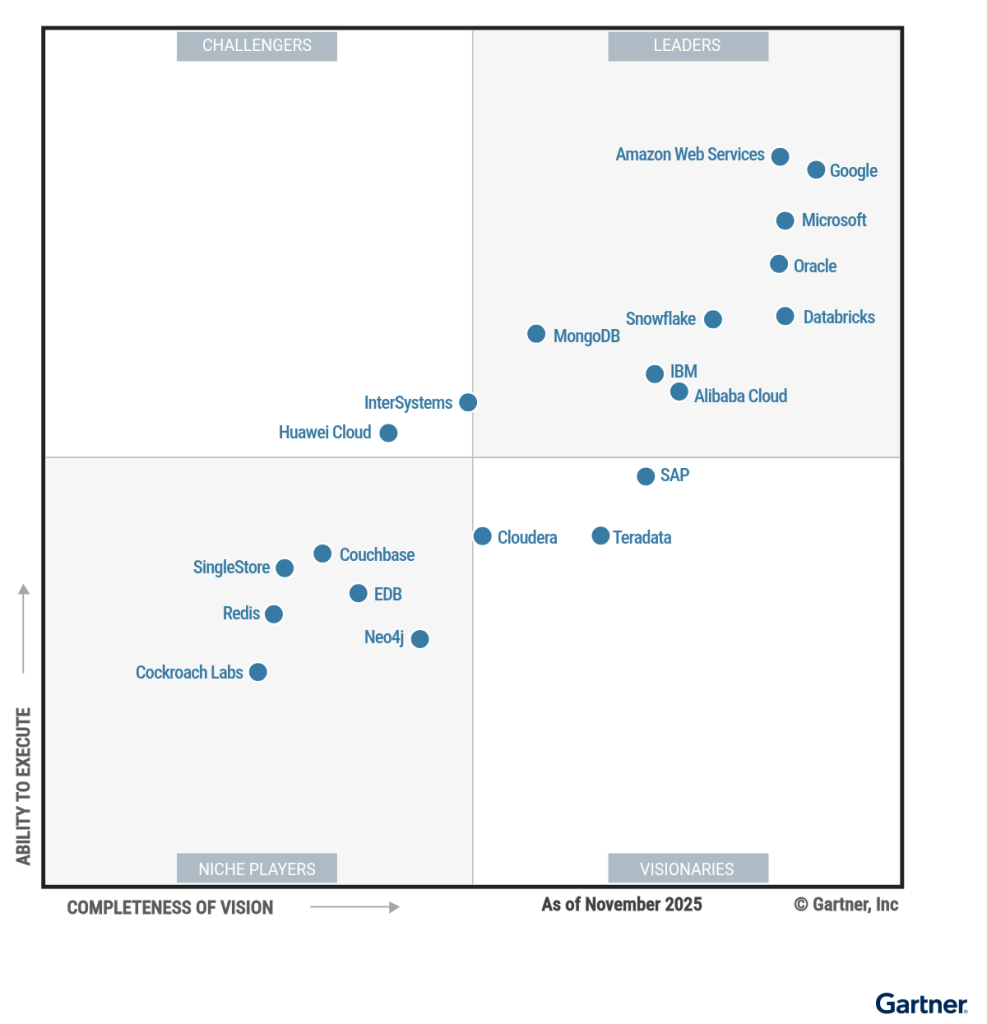
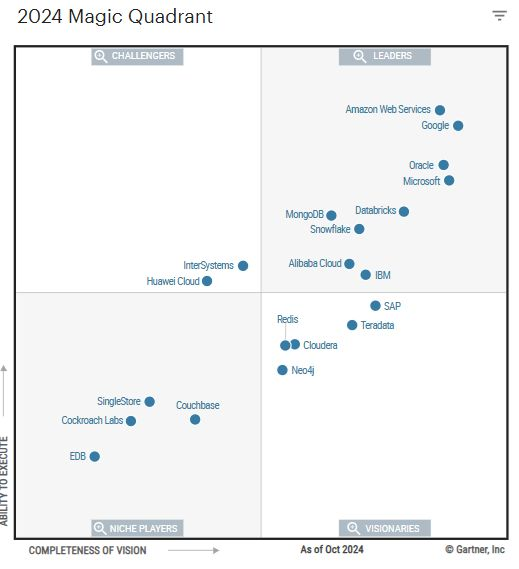
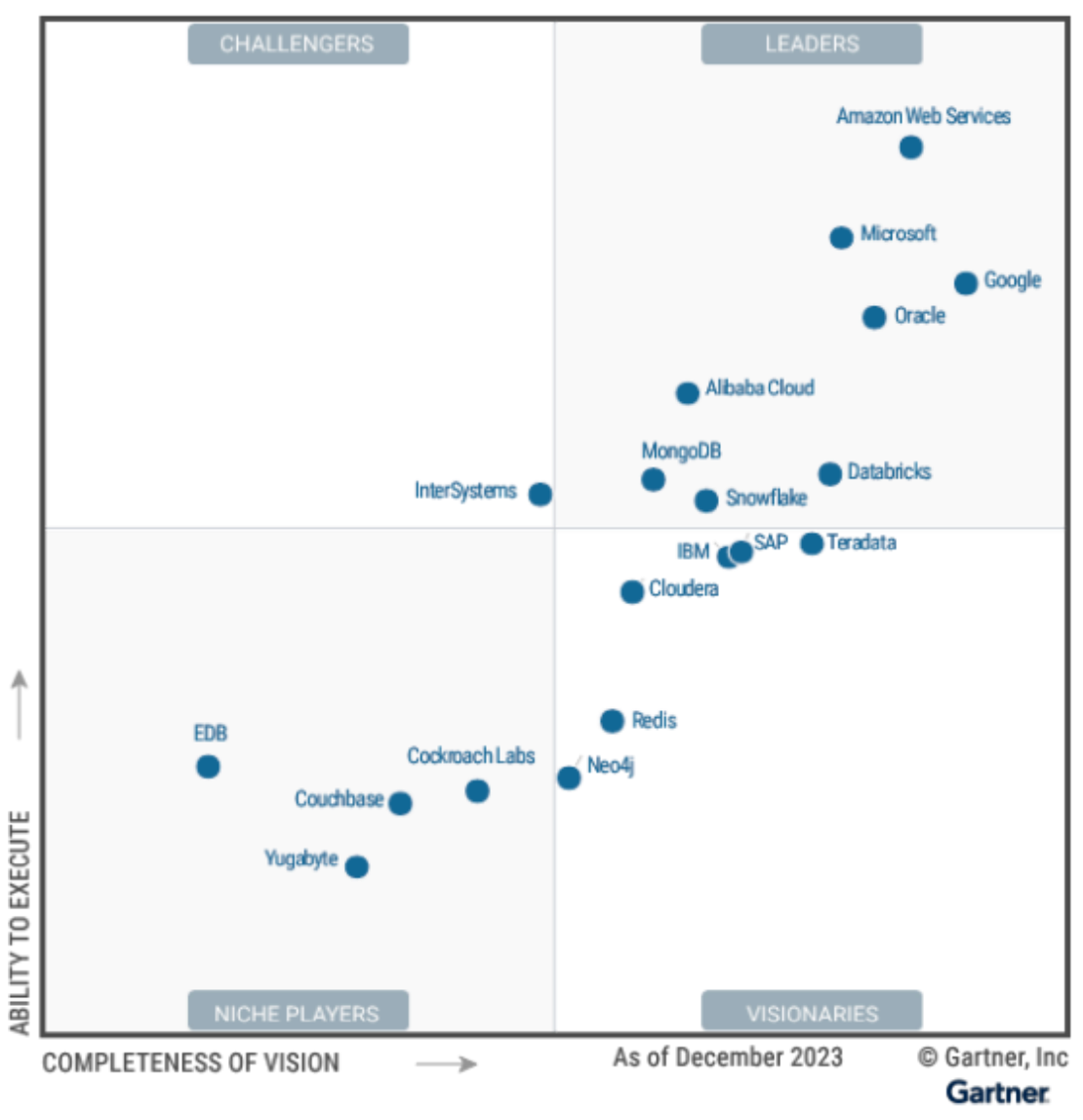
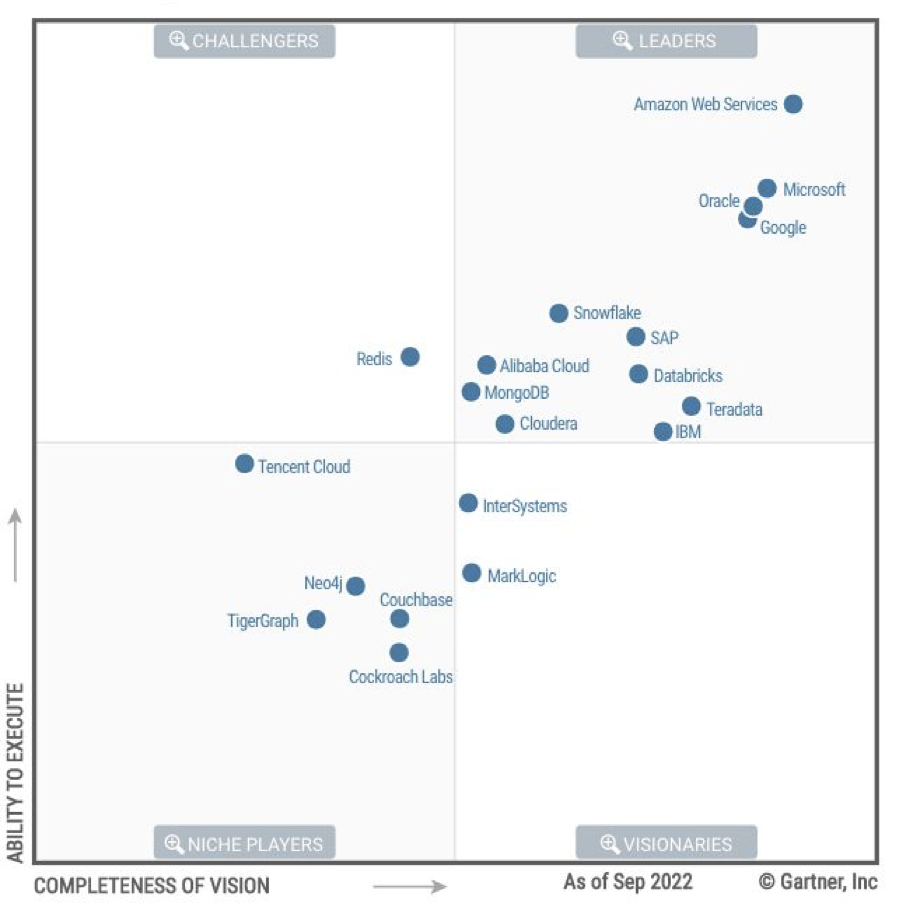
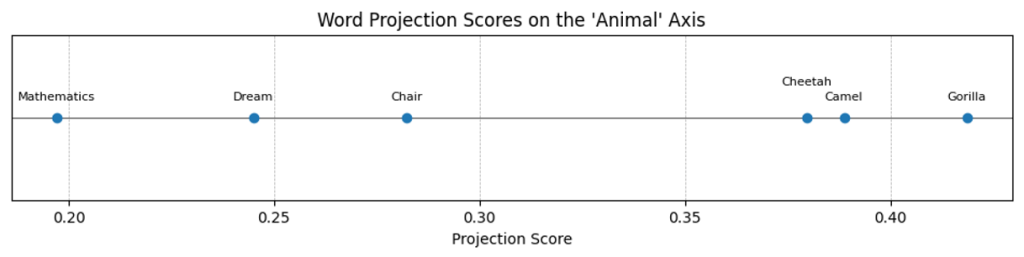
animals_words = ["Camel", "Gorilla", "Cheetah"]
un_animals_words = ["Dream", "Chair", "Mathematics"]
for word_list in (animals_words,un_animals_words):
projection_scores = np.dot(model.encode(word_list),
avg_animals_embeddings)
results.update({word: score for word,
score in zip(word_list, projection_scores)})
for word, score in results.items():
print(f"'{word}': {score:.4f}")
print(np.round(avg_animals_embeddings[:10], 4))
存储引擎在存储整数时,一般会使用最高位作为标志位,标记存储的整数是正数还是负数(参考),最高位也被称为“most significant bit (MSb)”。通常,最高位为1则表示正数,最高位为0,则表示负数。更进一步的,负数则会通过补码(参考:two’s complement)的方式表示。但是,InnoDB没有使用这种方法。
if (type == DATA_INT) {
/* Store integer data in Innobase in a big-endian format,
sign bit negated if the data is a signed integer. In MySQL,
integers are stored in a little-endian format. */
byte *p = buf + col_len;
for (;;) {
p--;
*p = *mysql_data;
if (p == buf) {
break;
}
mysql_data++;
}
if (!(dtype->prtype & DATA_UNSIGNED)) {
*buf ^= 128;
}
ptr = buf;
buf += col_len;
这段代码中,先将字节序做了颠倒(从最高字节位开始,逐个字节进行拷贝存储),即将 MySQL 层面的小端(little-endian)转化为了InnoDB层面的(big-endian)存储。而后,再对最高位进行了一次翻转,即这里的:*buf ^= 128操作。