年度总结是从前两年开始写的,鉴于考虑把“行业动态”的发布频率改为“月度”的,所以,也就同时要求自己每年都写一个数据库的年度总结了。在总结时,大家总是倾向于赋予最近一年过多的意义,但如果放在更长的时间尺度里面,可能不尽然。过去的2025年,并不是属于数据库的,而依旧是属于“AI”的,摆正这个位置后,在这个大背景下,我们再来看看数据库的发展情况吧。
1. 数据库与 AI
数据库与AI结合的方向包含了向量数据库、Memory、以及如何使用 AI 用好数据库。

OceanBase 是可能是国内数据库厂商中 AI 投入最大的厂商[43],除了持续建设向量存储与搜索技术外,今年还全新发布轻量向量数据库 seekdb [41];全新发布 PowerMem[42](兼容Mem0);此外,ODC 发布 DataPilot、诊断Agent等能力。

新的向量数据库 VexDB 正式发布,该数据库由清华研发团队,能够支持百亿千维向量数据毫秒级查询,召回准确度高,并在国际权威的 DABSTEP 非结构化数据分析测试中,VexDB 的数据代理系统以领先第二名超 10 个百分点的成绩夺冠[24]。

不约而同,在年底火山引擎 MySQL[50]、阿里云 MySQL[51]分别支持向量类型的索引与搜索能力,均使用 HNSW 索引,这非常大程度弥补了开源MySQL的弱项(仅能够进行向量存储,并不支持基于向ANN的检索算法)。

感受上,Google 也在各种方式尝试将AI技术更好的与数据库进行结合。具体的,在数据库与 AI 能力结合上,Google发布了 (1) MCP Toolbox for Databases[19] (2) 在控制台集成了Gemini 的 Text2SQL (3) 使用 Gemini 修复 Studio 中的错误[18] (4) 将数据库访问与管理集成到 Gemini CLI 中[20](说明:使用的是MCP Toolbox)。

阿里云数据库团队在 AI 结合上也做了大量探索,还是比较有意思的。包括尝试加速推理效率的 PolarKVCache [48];另外,Tair KVCache [56]团队似乎也在尝试通过文件系统、内存优化解决推理效率。目前,PolarKVCache 相关功能还处于内测阶段。LLM 推理过程中,在 Decoder 阶段由于KV Cache的问题,显存是巨大的瓶颈,如果通过硬件、软件结合的技术扩展缓存池的大小,可以大大增加推理的并发性,并更好的利用内存去加速推理。
此外,阿里云 RDS PostgreSQL 现推出AI插件“rds_ai”[6];PolarDB for AI [8][9]则内置了多种机器学习算法模型、NL2SQL等能力。
Zilliz Milvus 流行度进一步增强,GitHub Star 数量达到4万[60];Milvus 在过去一年则新增了如下的重要能力:RaBitQ 1-bit Quantization[57]、内置文本向量化[58]、Decay Ranker[59]、增强了JSON支持、Geospatial Data Type 等功能。
2. 云数据库或厂商的重要发布

AWS RDS/Aurora 支持了 MySQL 9.4/9.5[69],PostgreSQL 18[75],InfluxDB 3 [70],SQL Server Developer Edition[71] ;Aurora DSQL 现已全面推出[72];主要的数据库实例均支持了新的 Gravition 4 实例 [73][74];Aurora DSQL正式GA[77],且支持在几秒钟内创建集群[76]; 继续使用 Zero-ETL 方式打通数据库与Redshift 、SageMaker等平台[11][13];Aurora PostgreSQL 现在支持与 Kiro powers(MCP)集成[78]。

RDS 支持了 PostgreSQL 18[61]、SQL Server 2025 企业集群版、标准版[62]。RDS PostgreSQL、MySQL推出DuckDB分析实例[63][64][65];PolarDB 发布“文档数据库”MongoDB的访问能力[66],“PolarSearch”功能[4];阿里云 RDS 发布 Supabase 托管服务,帮助客户利用 Supabase / RDS PostgreSQL 能力快速构建全栈应用 [67];基于阿里云 DTS 构建了 RDS MySQL、PostgreSQL全球多活数据库(GAD)[7][68],Zero-ETL AnalyticDB等[5]。

MySQL/veDB支持 RockDB [79],ARM 架构规格[80],Sequence Engine[81],Flashback Query[82],多节点实例[83];此外,还发布了DBCopilot[84]、NL2SQL[85]、MongoDB 8.0[86];补充细节竞争力,例如提供SSL加密传输[23]、varchar的Online DDL、提升IN谓词时的性能等[21];支持 veDB-Search 混合检索[87]。

TDSQL-C MySQL 支持了创建“分析集群”(“LibraDB 内核”)[88]、全球数据库功能[89]、二级存储功能(Serverless 版)[90]。云数据库支持了PostgreSQL 18.0[91]、通过通过 SQL 调用大模型 API(PostgreSQL版 / tencentdb_ai )[92]、SQL Server 发布全新多节点架构(一主多备) [93]。TDSQL-C MySQL 版发布多项性能优化提升全缓存、大数据集等场景性能[94]。

HeatWave MySQL 新增支持 9.2.0、8.4.4 和 8.0.41 [95]、9.3.2[97]等版本、规格 MySQL.96 [96]等。PostgreSQL 增加了对 PostgreSQL 16 、pg_cron 和 pgaudit 等支持[98];Autonomous AI Database 内支持 Select AI RAG[99]、 API for DynamoDB[100]、最新备份克隆数据库[101]、数据库恢复到特定的 SCN [102]等。
Cloud SQL 支持了 PostgreSQL/MySQL 读取池自动扩缩容[103][104]、PostgreSQL 18[105]、MySQL 8.4[107]、AI 辅助故障排除等;AlloyDB 支持了 C4 系列(288vCPU)[106]、更新 alloydb_scann 扩展[108]、自然语言查询功能[109]、自动向量化[112];Spanner 支持了向量索引和近似最近邻 [110]、更新了优化器[111]、预过滤向量索引 [113]。

发布了“云原生”数据库HorizonDB[114][115]; 支持了Cassandra v5.0 [116]、MySQL 8.4[117]、PostgreSQL 机密计算[118]、PostgreSQL 18 正式发布[119]、Near-zero-downtime MySQL/PostgreSQL [120][121];Cosmos DB支持了全局二级索引[122]、Float16 的向量索引[123]、向量存储和搜索[124]、MCP工具[125]等。Azure DocumentDB 发布[126];SQL Server 2025 发布;Azure SQL 数据库 DiskANN 向量索引[127]。

TaurusDB 发布 PostgreSQL 引擎支持[128]、Serverless支持冷热分离能力[129]、开放弹性策略自定义[130]、支持动态脱敏[131]、增强智能DBA SQL限流[132];RDS支持MySQL 8.4[133];GeminiDB Redis 接口性能版基于存算分离架构,单分片最高可支持百万QPS[134];GaussDB 透明多写功能发布[135];GaussDB Doer 基于AI的智能助手;openGauss 发布 MCP Server[136]。

RDS 支持了数据库大版本升级[137]、线程池优化、持跨地域备份(PostgreSQL)[138];GaiaDB 支持双机房部署[139]、新增大规格[140]、一键从RDS同步[141];VectorDB 支持可视化[142]、新的CLI 支持[143]。
发布新的中文名“海扬数据库”[137];发布PowerRAG、共享存储和桌面版(2c6g环境运行)[138]、轻量向量数据库 seekdb [139];seekdb 支持嵌入式、Server两种模式;发布 PowerMem[140](兼容Mem0);ODC 发布 DataPilot、诊断Agent等能力。

发布基于对象存储(例如:S3)的版本 “TiDB X” [144],使用对象存储天然具备的“扩展性”、快照等能力去实现一个具备“PB”级别扩展的 OLTP 数据库[145][146]。

TeleDB 荣登 TPC-DS 全球测评总榜第二(10 TB)[147]。
3. 其他

在今年国产数据库目录新增了两个新的国产数据库[33]:大云海山数据库(He3DB for PostgreSQL)、崖山数据库。去年新增的国产数据库包括[34]:GaussDB(集中式/分布式版)、TaurusDB、KingBase、神州通用、Vastbase,分布式数据库还有 TiDB、达梦、PolarDB、GBase、虚谷、TDSQL、GoldenDB、OceanBase。整个国产数据库的目录大抵就是在这个范围内了,后续相信不会再增加太多。而这些数据库也可能就组成了未来中国10~30年、甚至更长时间的数据库基础设施的格局。
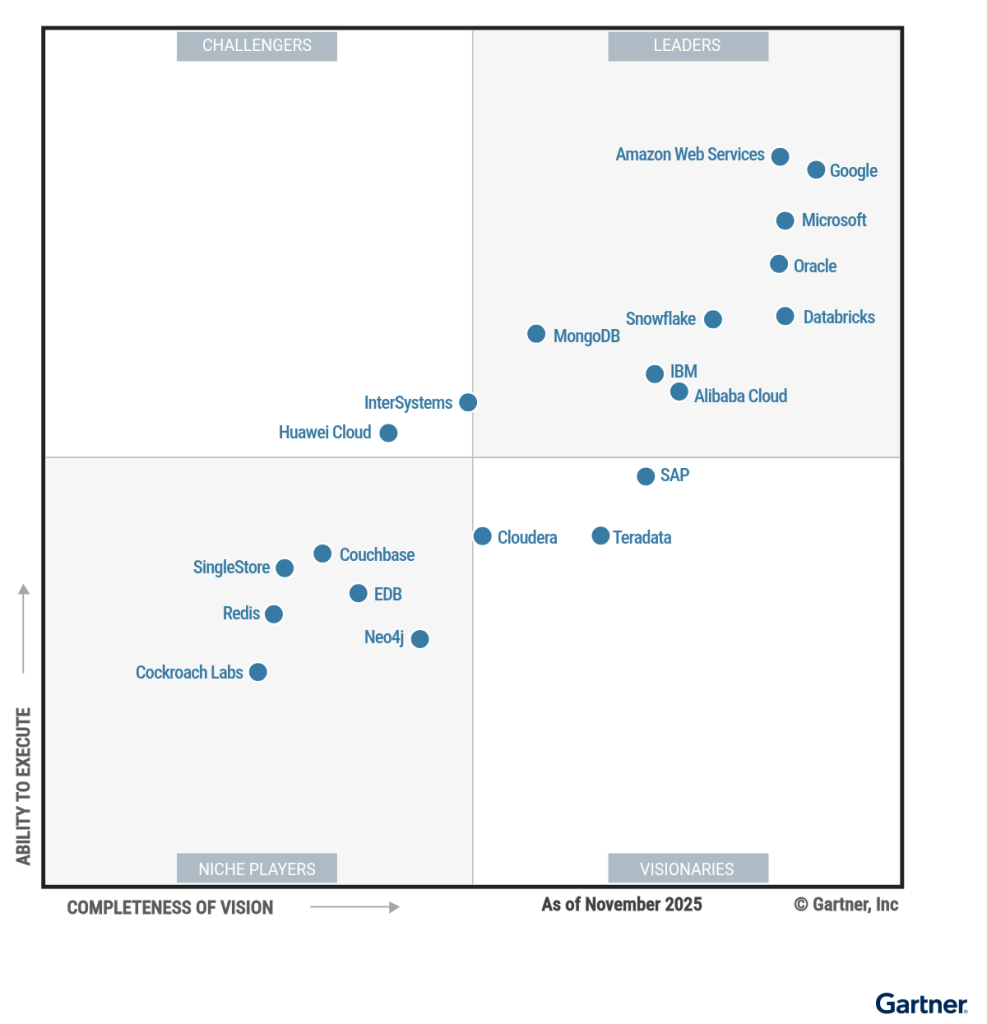
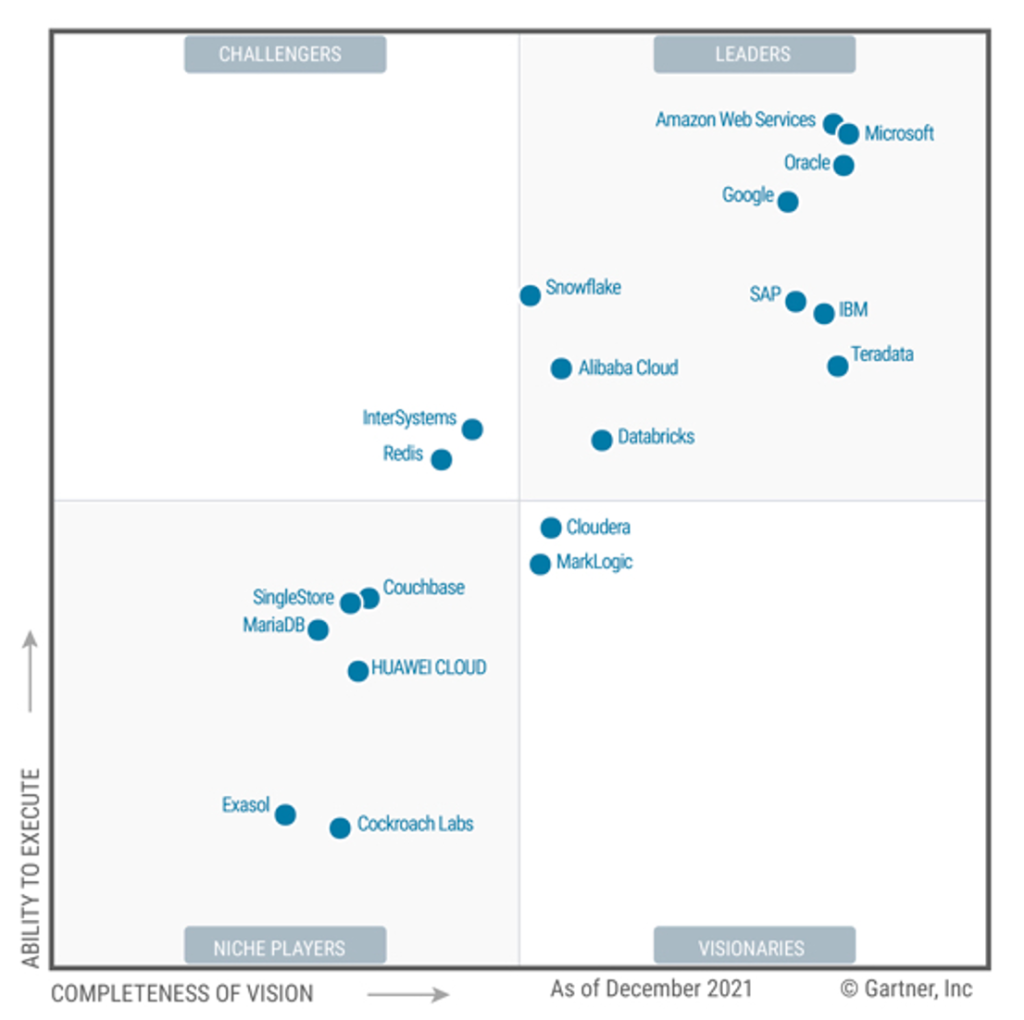
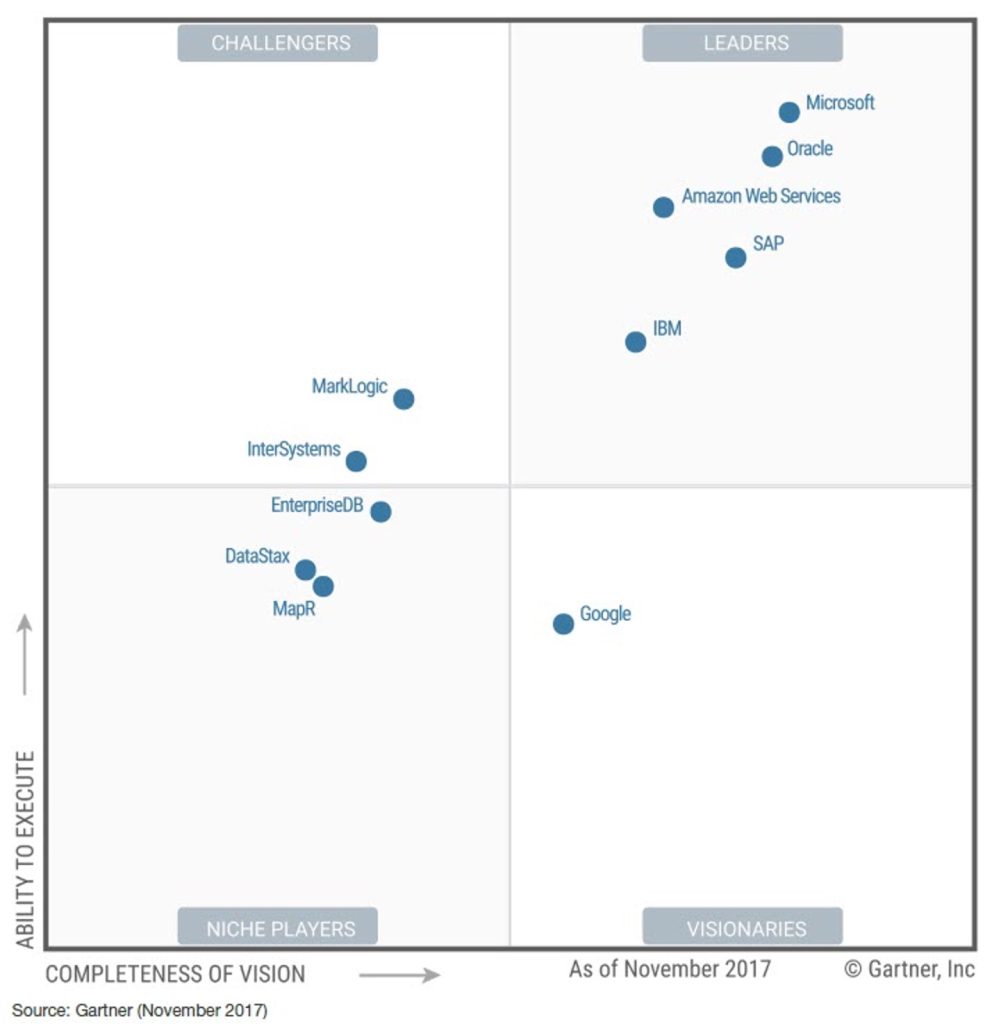
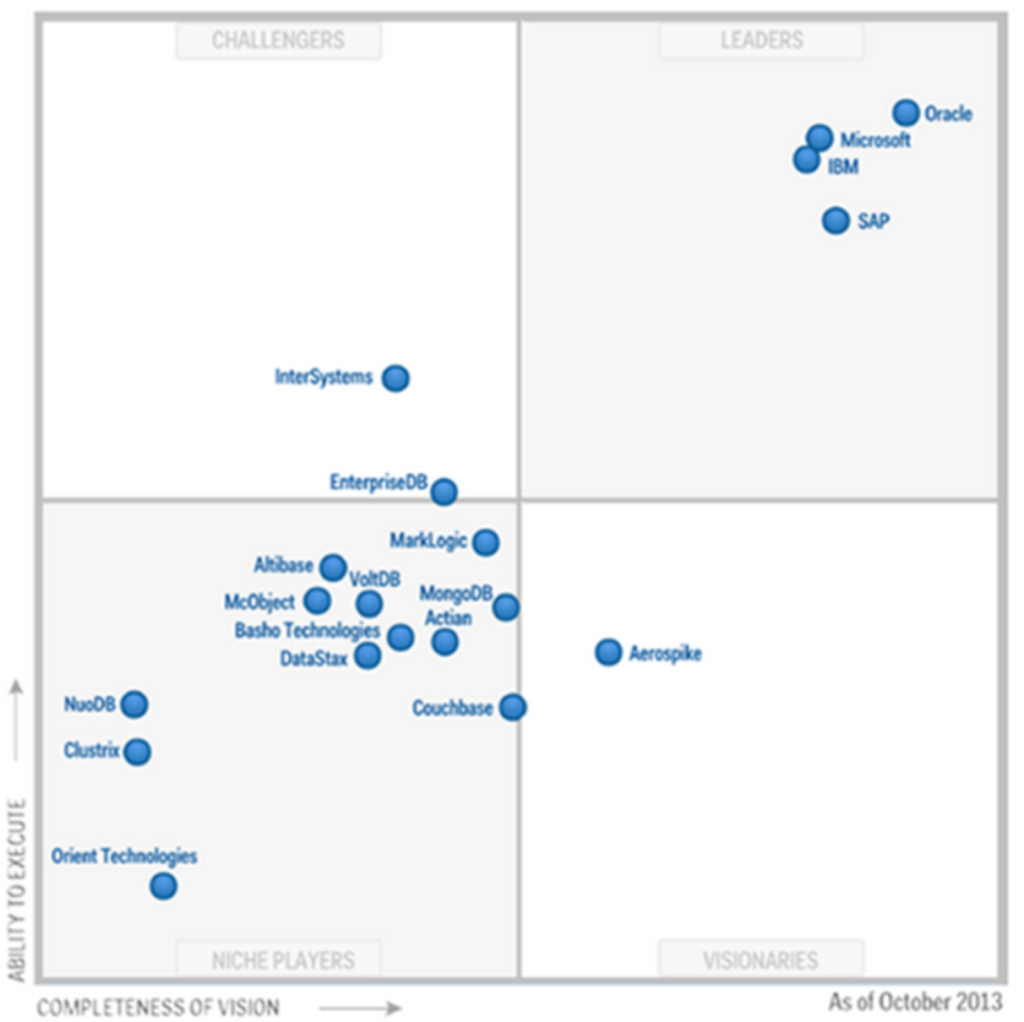
Gartner 2025云数据库魔力象限发布[149],阿里云依旧处于 Leaders 象限、华为云在 Challengers 象限。Redis、Neo4j从 Visionaries 象限落入 Niche Players。
阿里云 PolarDB 打破 TPC-C 记录[3][4],以更高的性能、更好的性价比超越之前OceanBase、TDSQL创下的记录。PolarDB本次使用的使用的版本为多主集群(Limitless),总计使用2340个数据节点,56,160个cores,1170个处理器。
达梦数据库创始人冯裕才教授获2024年“CCF最高科学技术奖”[2]。获奖理由:“冯裕才教授是我国著名数据库科技工作者,长期致力于我国自主数据库的研发和产业化工作,突破了数据库共享存储集群技术,开发了达梦系列数据库,打造了国内首家数据库上市企业“达梦数据”,为推动我国基础软件产业的发展做出了重要贡献。”;达梦发布2024年度报告,该年年度营收达10.4亿,同比增长31.49%,净利润为3.6亿[148]。
清华大学李国良入选ACM Fellow,以表彰其在人机协同(human-in-the-loop)数据集成与基于学习的数据库系统领域做出的重要贡献。此外,李国良还是 openGauss 社区技术委员会主席。[7]
4. 重要的收购与融资
在数据库领域,收购或融资相关的事件几乎都与“AI”相关。

MongoDB $2.2 亿收购 Voyage AI :Voyage AI 提供相比于通用模型效果更好的 Embedding 能力、以及 ReRank 模型等;这很好的补充了 MongoDB 在向量存储、搜索的能力[26][27]。

Elastic 收购 Jina AI:通过收购“Jina AI”,Elastic 公司可以快速的具备更强的向量处理技术,包括更好的向量算法、更好的 ReRank 功能,可以让 ElasticSearch 在 RAG 场景(或类似场景)有更强的竞争力[25]。
多云数据库平台服务商Tessell获 $6000万融资。此次融资将用于进一步扩大市场覆盖,并计划推出基于 AI 驱动的对话式数据库管理服务[150]。

Databricks收购Neon[28],该产品则基于云基础设施提供Serverless的PostgreSQL服务,并且提供诸如快速Branching等能力。

Snowflake 以 $2.5 亿收购了CrunchyData[29][30],该公司提供云端企业级全托管的PostgreSQL服务,同时支持基于相关数据的分析能力;

Supabase 今年有两次重大的融资,分别是 $2 亿美元(估值$20亿)[32]、$1 亿美元(估值$50亿)[31]。凭借在开发者中良好的采用率,并随着 “Vibe coding”的流行,该公司快速起飞,可以将其理解为未来自然语言编程的基础组件。

IBM 110亿美元收购数据流厂商 Confluent[54],该公司创建于2014年,最初致力于 Apache Kafka 的商业化,逐步扩展为完整的实时数据流平台。
IBM 计划收购 DataStax,该公司基于 Apache Cassandra 提供企业级的数据库存储与AI方案[151]。

MariaDB 宣布收购高可用产品 Galera Cluster。 通过此次收购,MariaDB可以向客户提供更具竞争力的企业级高可用方案;而对于 Galera 则可以获得更多可靠的客户[152]。

ClickHouse 宣布融资3.5亿美元C轮融资[153],主要用于全球化业务推进、AI与分析能力增强等方向。
5. 开源与商业

今年,Redis 将 SSPL 协议改成更容易被社区接受的 AGPL 协议, 并发布 8.0 版本[36]。但是,社区似乎已经开始逐步转向了Valkey,例如,Azure 已经计划于2027[15]、2028[16] 年停用Redis Enterprise与Azure Cache for Redis。Redis 在2024年将协议从 BSD 更改为了dual RSALv2+SSPLv1[37],而后多家大型公司“联合”起来fork了新的项目 Valkey 。
开源软件和商业软件的竞争,经过了MongoDB、Redis、ElasticSearch等与云厂商的探索,逐渐形成了某些模式:主线足够强大,则可以合作分润;主线如果稍有羸弱,则可能会被分叉出新分支;或者面临着云厂商的自研。因为对于云厂商来说,这部分收入与利润,足以支撑起在该方向的投入。
6. 相关阅读
Databases in 2025: A Year in Review
Another year passes. I was hoping to write more articles instead of just these end-of-the-year screeds, but I almost died in the spring …
![]() Andy Pavlo
Andy Pavlo
……
Databases in 2024: A Year in Review
Like a shot to your dome piece, I’m back to hit you with my annual roundup of what happened in the rumble-tumble game of databases …
![]() Andy Pavlo
Andy Pavlo
Jan. 01, 2025
Databases in 2023: A Year in Review
I am starting this new year the same way I ended the last: taking antibiotics because my biological daughter brought home a nasty sinus bug from Carnegie Mellon’s …
![]() Andy Pavlo
Andy Pavlo
Jan. 04, 2024
Databases in 2022: A Year in Review
This article originally appeared on the OtterTune website.
Another year has gone by, and I’m still alive. As such, it is an excellent time to reflect on what happened …
![]() Andy Pavlo
Andy Pavlo
Dec. 31, 2022
Databases in 2021: A Year in Review
It was a wild year for the database industry, with newcomers overtaking the old guard, vendors fighting over benchmark numbers, and eye-popping funding rounds. …
![]() Andy Pavlo
Andy Pavlo
Dec. 28, 2021
What Goes Around Comes Around… And Around…
Two decades ago, one of us co-authored a paper commenting on the previous 40 years of data modelling research and development [188]. That paper demonstrated that the relational model (RM) and SQL are the prevailing choice …
Michael Stonebraker, Andrew Pavlo
June 2024
This paper provides a summary of 35 years of data model proposals, grouped into 9 different eras. We discuss the proposals of each era, and show that there are only a few basic data modeling ideas, and most have been around a long time …
Michael Stonebraker, Joey Hellerstein
2005
参考链接
- [1] https://mp.weixin.qq.com/s/Wo6v2dQtqohj9LtYfUPPHQ
- [2] https://mp.weixin.qq.com/s/nR4iIK-6m6elVh4p-kLwgQ
- [3] https://www.tpc.org/tpcc/results/tpcc_results5.asp?print=false&orderby=tpm&sortby=desc
- [4] https://www.linkedin.com/posts/panfeng-zhou-a16a934_im-excited-to-share-that-weve-just-set-activity-7290434703789109248-7ymy/
- [5] https://www.tpc.org/tpcc/results/tpcc_result_detail5.asp?id=125012701
- [6] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/ai-rds-ai
- [7] https://mp.weixin.qq.com/s/-HjfyeW2ucyUWHh_Foah6A
- [8] https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/enable-the-polardb-for-ai-feature
- [9] https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/chatbi-best-practices
- [10] https://mp.weixin.qq.com/s/Ix4BSsMZL1YybEGCVadRxw
- [11] https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.Aurora_Fea_Regions_DB-eng.Feature.Zero-ETL.html
- [12] https://aws.amazon.com/blogs/aws/now-open-aws-asia-pacific-new-zealand-region/
- [13] https://aws.amazon.com/about-aws/whats-new/2025/10/amazon-aurora-postgresql-zero-etl-integration-sagemaker/
- [14] https://azure.microsoft.com/updates?id=502004
- [15] https://azure.microsoft.com/updates?id=499606
- [16] https://azure.microsoft.com/updates?id=499577
- [17] https://azure.microsoft.com/updates?id=500765
- [18] https://cloud.google.com/sql/docs/sqlserver/write-sql-gemini#fix-query
- [19] https://github.com/googleapis/genai-toolbox
- [20] https://docs.cloud.google.com/sql/docs/mysql/pre-built-tools-with-mcp-toolbox#mcp-configure-your-mcp-client-geminicli
- [21] https://www.volcengine.com/docs/6313/1840904
- [22] https://www.volcengine.com/docs/6313/1840828
- [23] https://www.volcengine.com/docs/6438/1864761
- [24] https://vexdb.com/
- [25] https://ir.elastic.co/news/news-details/2025/Elastic-Completes-Acquisition-of-Jina-AI-a-Leader-in-Frontier-Models-for-Multimodal-and-Multilingual-Search/default.aspx
- [26] https://www.mongodb.com/company/blog/news/redefining-database-ai-why-mongodb-acquired-voyage-ai
- [27] https://www.bloomberg.com/news/articles/2025-02-24/mongodb-buys-voyage-ai-for-220-million-to-bolster-ai-search?embedded-checkout=true
- [28] https://neon.com/
- [29] https://techcrunch.com/2025/06/02/snowflake-to-acquire-database-startup-crunchy-data/
- [30] https://www.crunchydata.com/
- [31] https://supabase.com/blog/supabase-series-e
- [32] https://fortune.com/2025/04/22/exclusive-supabase-raises-200-million-series-d-at-2-billion-valuation/
- [33] https://www.itsec.gov.cn/aqkkcp/cpgg/202508/t20250822_231110.html
- [34] https://www.itsec.gov.cn/aqkkcp/cpgg/202409/t20240930_194299.html
- [35] https://mp.weixin.qq.com/s/3TGIKrpPLeQ-gBHY67w0Eg
- [36] https://antirez.com/news/151
- [37] https://github.com/redis/redis/commit/0b34396924eca4edc524469886dc5be6c77ec4ed
- [38] https://www.pingcap.com/blog/introducing-tidb-x-a-new-foundation-distributed-sql-ai-era/
- [39] https://mp.weixin.qq.com/s/w8itCbW_–mG2LhSPL79FA
- [40] https://mp.weixin.qq.com/s/RX4K3nXEYSrmTxIeogMh2A
- [41] https://www.oceanbase.ai/
- [42] https://www.powermem.ai/
- [43] https://mp.weixin.qq.com/s/PEhpO3zJjswSS5OdZyA4xQ
- [44] https://azure.microsoft.com/en-us/updates?id=523814
- [45] https://azure.microsoft.com/en-us/updates?id=523803
- [46] https://azure.microsoft.com/en-us/products/horizondb
- [47] https://techcommunity.microsoft.com/blog/adforpostgresql/announcing-azure-horizondb/4469710
- [48] https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/polarkvcache-inference-acceleration?spm=a2c4g.11186623.0.0.24e23ba1PKfYAM
- [49] https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/polardb-ray?spm=a2c4g.11186623.0.0.24e23ba1PKfYAM
- [50] https://www.volcengine.com/docs/6313/1978527
- [51] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/vector-storage-1
- [52] https://mp.weixin.qq.com/s/j-CgF6CaP-kylz7aB2gWxA
- [53] https://www.volcengine.com/docs/6313/74505
- [54] https://investors.confluent.io/news-releases/news-release-details/ibm-acquire-confluent-create-smart-data-platform-enterprise
- [55] https://www.gartner.com/doc/reprints?id=1-2MC14I3H&ct=251121&st=sb
- [56] https://mp.weixin.qq.com/s/2BbfcnxgR4aPN7_LKRYlNQ
- [57] https://milvus.io/docs/ivf-rabitq.md
[58] https://milvus.io/docs/embedding-function-overview.md
[59] https://milvus.io/docs/decay-ranker-overview.md - [60] https://github.com/milvus-io/milvus
- [61] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/features-of-apsaradb-rds-for-postgresql
- [62] https://help.aliyun.com/zh/rds/apsaradb-rds-for-sql-server/features
- [63] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/duckdb-based-analytical-instance
- [64] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/htap-based-automatic-query-routing-is-available-for-apsaradb-rds-for-mysql
- [65] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/blue-green-deployment
- [66] https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/compatibility-with-document-databases/
- [67] https://help.aliyun.com/zh/rds/apsaradb-rds-for-postgresql/rds-supabase
- [68] https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/release-of-global-active-databases-in-apsaradb-rds-for-mysql
- [69] https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/MySQL.Concepts.VersionMgmt.html#mysql-preview-environment-version-9-5
[70] https://aws.amazon.com/about-aws/whats-new/2025/10/amazon-timestream-influxdb-3/
[71] https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/sqlserver-dev-edition.html
[72] https://aws.amazon.com/about-aws/whats-new/2025/05/amazon-aurora-dsql-generally-available/
[73] https://aws.amazon.com/about-aws/whats-new/2025/03/amazon-rds-postgresql-mysql-mariadb-m8g-r8g-database-instances-additional-regions
[74] https://aws.amazon.com/about-aws/whats-new/2025/03/amazon-aurora-r8g-database-instances-additional-aws-regions
[75] https://aws.amazon.com/about-aws/whats-new/2025/12/amazon-aurora-postgresql-18-1-rds-database-preview
[76] https://aws.amazon.com/about-aws/whats-new/2025/12/amazon-aurora-dsql-cluster-creation-in-seconds
[77] https://aws.amazon.com/about-aws/whats-new/2025/05/amazon-aurora-dsql-generally-available/
[78] https://aws.amazon.com/about-aws/whats-new/2025/12/amazon-aurora-postgresql-integration-kiro-powers
[79] https://www.volcengine.com/docs/6313/74512
[80] https://www.volcengine.com/docs/6313/74505
[81] https://www.volcengine.com/docs/6313/1467064
[82] https://www.volcengine.com/docs/6313/1521305
[83] https://www.volcengine.com/docs/6313/75366
[84] https://www.volcengine.com/docs/6956/1515364
[85] https://www.volcengine.com/docs/6956/1802899
[86] https://www.volcengine.com/docs/6447/1808426
[87] https://www.volcengine.com/docs/6357/1820181 - [88] https://cloud.tencent.com/document/product/1003/119870
[89] https://cloud.tencent.com/document/product/1003/118899
[90] https://cloud.tencent.com/document/product/1003/119284
[91] https://cloud.tencent.com/announce/detail/2140
[92] https://cloud.tencent.com/document/product/409/116227
[93] https://cloud.tencent.com/document/product/238/115279 - [94] https://cloud.tencent.com/document/product/1003/71714
- [95] https://docs.oracle.com/iaas/releasenotes/mysql-database/heatwave-920-844-8041.htm
[96] https://docs.oracle.com/iaas/releasenotes/mysql-database/TC-40271-heatwave-mysql96-new-shape.htm
[97] https://docs.oracle.com/iaas/releasenotes/mysql-database/heatwave-932.htm
[98] https://docs.oracle.com/iaas/releasenotes/postgresql/pg_cron-pgaudit.htm
[99] https://docs.oracle.com/iaas/releasenotes/autonomous-database-dedicated/adbd-selectai-rag.htm
[100] https://docs.oracle.com/iaas/releasenotes/autonomous-database-serverless/2025-12-autonomous-ai-database-api-for-dynamodb.htm
[101] https://docs.oracle.com/iaas/releasenotes/autonomous-database-dedicated/adbd-clone-latestbackup.htm
[102] https://docs.oracle.com/iaas/releasenotes/autonomous-database-dedicated/adbd-restore-db-scn.htm - [103] https://docs.cloud.google.com/sql/docs/postgres/read-pool-autoscaling
[104] https://docs.cloud.google.com/sql/docs/mysql/read-pool-autoscaling
[105] https://cloud.google.com/sql/docs/postgres/create-instance
[106] https://docs.cloud.google.com/alloydb/docs/choose-machine-type
[107] https://cloud.google.com/sql/docs/mysql/upgrade-major-db-version-inplace
[108] https://cloud.google.com/alloydb/docs/reference/ai/scann-index-reference
[109] https://cloud.google.com/alloydb/docs/ai/use-natural-language-generate-sql-queries
[110] https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors
[111] https://docs.cloud.google.com/spanner/docs/query-optimizer/versions
[112] https://docs.cloud.google.com/alloydb/docs/ai/generate-manage-auto-embeddings-for-tables
[113] https://cloud.google.com/spanner/docs/find-approximate-nearest-neighbors#filter-vector-index
[114] https://azure.microsoft.com/en-us/products/horizondb
[115] https://techcommunity.microsoft.com/blog/adforpostgresql/announcing-azure-horizondb/4469710
[116] https://azure.microsoft.com/updates?id=499753
[117] https://azure.microsoft.com/updates?id=501989
[118] https://azure.microsoft.com/updates?id=500795
[119] https://azure.microsoft.com/updates?id=523196
[120] https://azure.microsoft.com/updates?id=508403
[121] https://azure.microsoft.com/updates?id=500765
[122] https://azure.microsoft.com/updates?id=491257
[123] https://azure.microsoft.com/updates?id=523796
[124] https://azure.microsoft.com/en-us/updates?id=523803
[125] https://azure.microsoft.com/en-us/updates?id=523814
[126] https://azure.microsoft.com/updates?id=523735
[127] https://azure.microsoft.com/updates?id=523110
[128] https://mp.weixin.qq.com/s/3TGIKrpPLeQ-gBHY67w0Eg
[129] https://support.huaweicloud.com/usermanual-taurusdb/taurusdb_03_0195.html
[130] https://support.huaweicloud.com/usermanual-taurusdb/taurusdb_02_0210.html
[131] https://support.huaweicloud.com/kerneldesc-taurusdb/taurusdb_20_0069.html
[132] https://support.huaweicloud.com/usermanual-taurusdb/taurusdb_03_0163.html
[133] https://support.huaweicloud.com/productdesc-rds-mysql/zh-cn_topic_0043898356.html
[134] https://support.huaweicloud.com/redisug-nosql/nosql_05_0053.html
[135] https://mp.weixin.qq.com/s/3TGIKrpPLeQ-gBHY67w0Eg
[136] https://mp.weixin.qq.com/s/jEDXFwRYtAWmZ11HV-W-1w
[137] https://mp.weixin.qq.com/s/N1HgNddZSW4aebpTS26JGg
[138] https://mp.weixin.qq.com/s/Ax8Iov00ebfjsCy3Afub_Q
[139] https://www.oceanbase.ai/
[140] https://www.powermem.ai/
[137] https://cloud.baidu.com/doc/RDS/s/Umhbe5vhw
[138] https://cloud.baidu.com/doc/RDS/s/rmciw3o9v
[139] https://cloud.baidu.com/doc/GaiaDB/s/Umde6uvii
[140] https://cloud.baidu.com/doc/GaiaDB/s/elt5qt0i9
[141] https://cloud.baidu.com/doc/GaiaDB/s/Mmbz2f64q
[142] https://cloud.baidu.com/doc/VDB/s/Cm7bly8u6
[143] https://cloud.baidu.com/doc/VDB/s/Em1zvj00h
[144] https://www.pingcap.com/blog/introducing-tidb-x-a-new-foundation-distributed-sql-ai-era/
[145] https://mp.weixin.qq.com/s/w8itCbW_–mG2LhSPL79FA
[146] https://mp.weixin.qq.com/s/RX4K3nXEYSrmTxIeogMh2A
[147] https://www.tpc.org/tpcds/results/tpcds_results5.asp
[148] https://www.sse.com.cn/disclosure/listedinfo/announcement/c/new/2025-04-15/688692_20250415_LKHL.pdf
[149] https://www.gartner.com/doc/reprints?id=1-2MC14I3H&ct=251121&st=sb
[150] https://techcrunch.com/2025/04/09/tessell-snags-60m-to-drive-data-management-at-scale/
[151] https://www.datastax.com/blog/ibm-plans-to-acquire-datastax
[152] https://www.businesswire.com/news/home/20250527634819/en/MariaDB-Acquires-Galera-Cluster
[153] https://clickhouse.com/blog/clickhouse-raises-350-million-series-c-to-power-analytics-for-ai-era