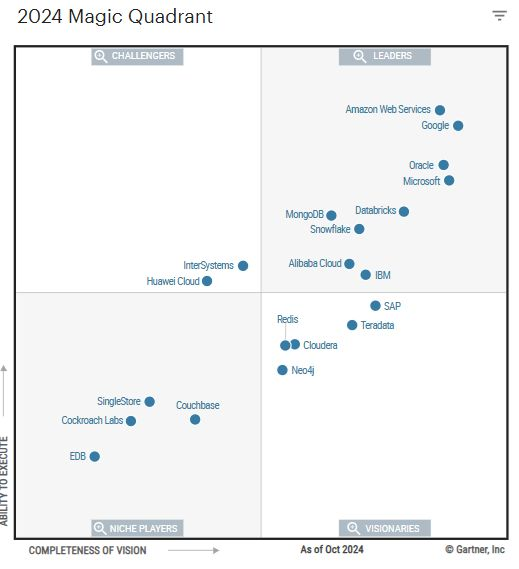
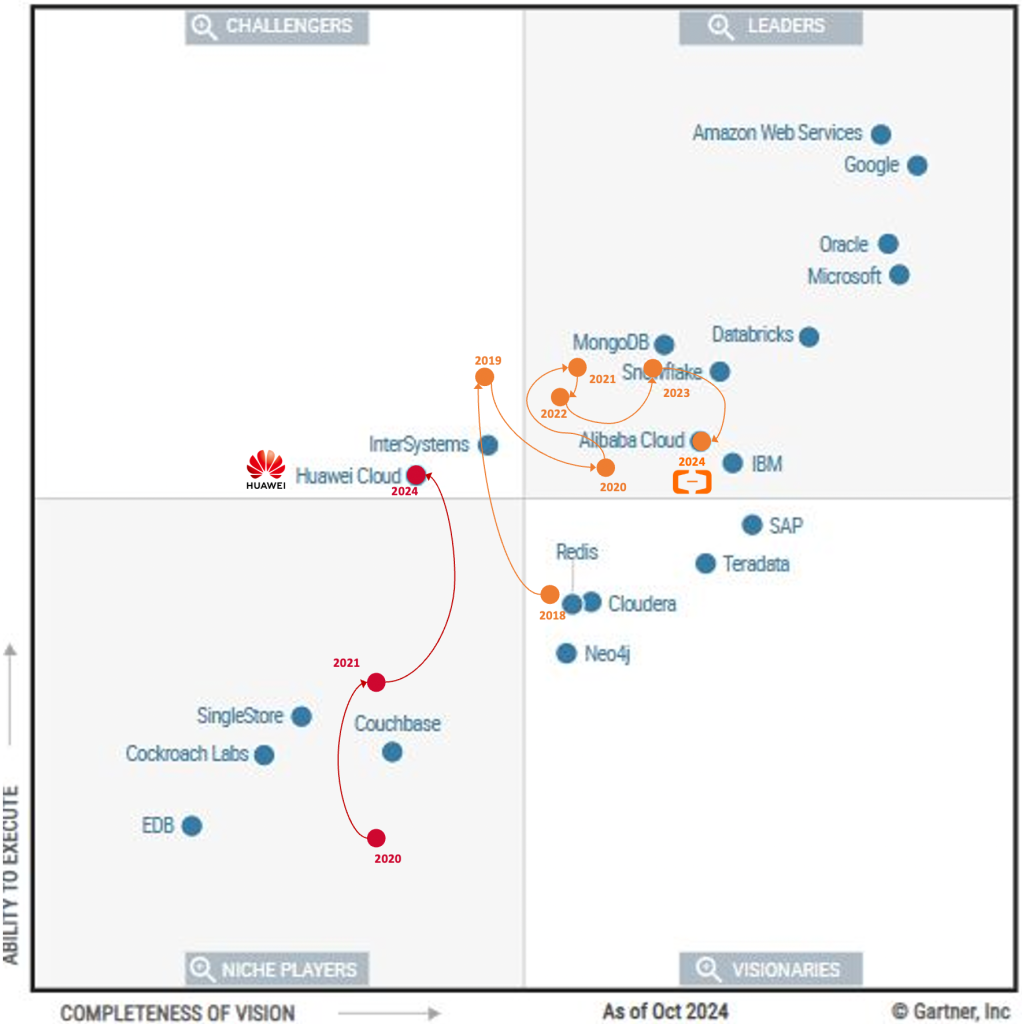
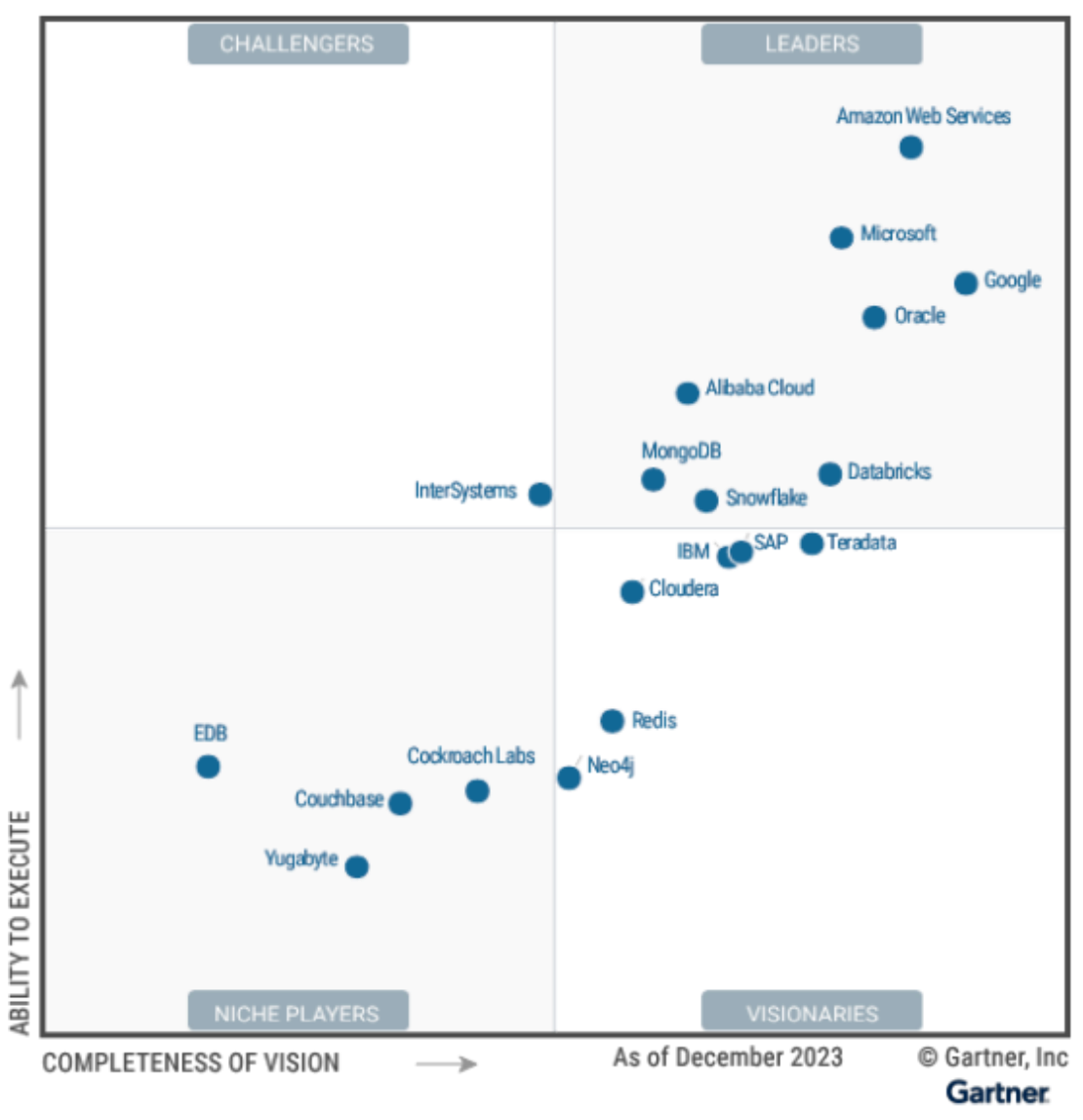
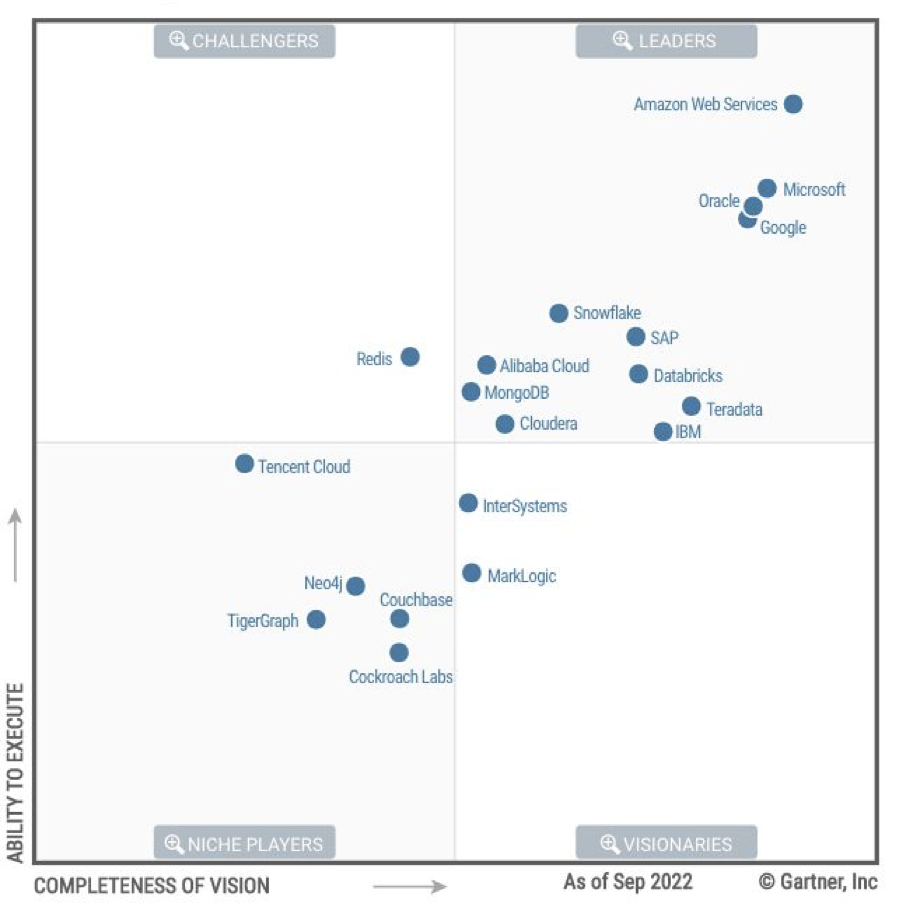
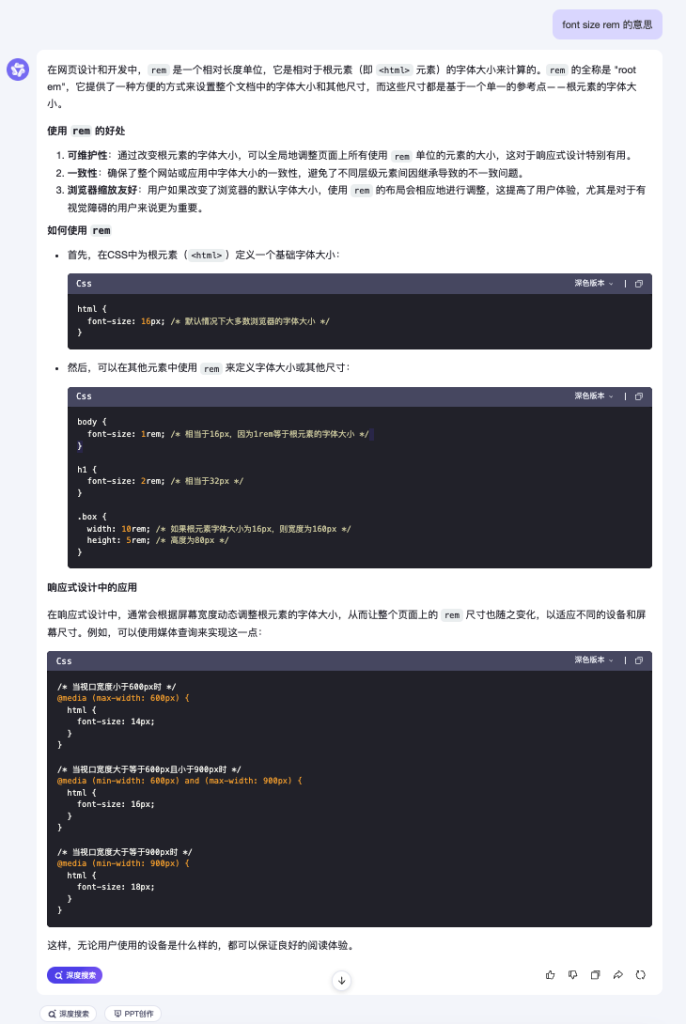
这是第二次 SQL 编程大赛[1],我依旧是评委之一,所以自己也尝试了独立完成该问题的挑战。这次大赛分为“普通挑战”和“进阶挑战”。其中普通挑战较为简单,本文主要讨论自己完成进阶挑战过程中的想法与思路。
目录
问题描述
原始的问题,可以参考:NineData 第二届数据库编程大赛 用一条SQL秒杀火车票,本文仅考虑其中的“进阶挑战”。这里该“进阶挑战问题”复述如下。
有如下两张表存放着乘客信息和列车信息,使用一条SQL给每个乘客分配一趟列车以及对应的座位号,需要注意,需要考虑进阶挑战的一些要求,比如,每趟列车可以发售10%的无座车票;车票需要有限发售有座车票,然后才开始发售无座车票。
mysql> desc passenger;
+-------------------+-------------+------+-----+
| Field | Type | Null | Key |
+-------------------+-------------+------+-----+
| passenger_id | varchar(16) | NO | PRI |
| departure_station | varchar(32) | NO | |
| arrival_station | varchar(32) | NO | |
+-------------------+-------------+------+-----+mysql> desc train;
+-------------------+-------------+------+-----+
| Field | Type | Null | Key |
+-------------------+-------------+------+-----+
| train_id | varchar(8) | NO | PRI |
| departure_station | varchar(32) | NO | |
| arrival_station | varchar(32) | NO | |
| seat_count | int | NO | |
+-------------------+-------------+------+-----+示例数据如下:
mysql> select * from passenger limit 3;
+--------------+-------------------+-----------------+
| passenger_id | departure_station | arrival_station |
+--------------+-------------------+-----------------+
| P00000001 | 上海 | 福州 |
| P00000002 | 成都 | 成都 |
| P00000003 | 乌鲁木齐 | 太原 |
+--------------+-------------------+-----------------+mysql> select * from train limit 3;
+----------+-------------------+-----------------+------------+
| train_id | departure_station | arrival_station | seat_count |
+----------+-------------------+-----------------+------------+
| G1006 | 重庆 | 北京 | 1600 |
| G1007 | 杭州 | 福州 | 600 |
| G1008 | 济南 | 合肥 | 800 |
+----------+-------------------+-----------------+------------+解题思路
对乘客进行编号
首先利用数据库的Windows Function功能对所有的乘客先分组再编号,具体的,按照“出发站”和“到达站”分组,然后在组内进行编号。次编号则为后续乘客车票分配的编号。例如,从 A 到 B 地,一共有 2420 个乘客。那么乘客的编号则是1…2420;再有乘客从 C 到 D 地,共有1800个乘客,则编号则为 1 … 1800。大概可以使用类似如下的 SQL 代码实现:
ROW_NUMBER() over(PARTITION BY departure_station,arrival_station) as seq对列车进行排序和计算
与乘客类似的,先按照出发和到达站点进行分组,并计算每个列车能够容纳的乘客数量,即座位数量的 1.1 倍。然后,在分组内进行“累加”计算,该累加计算,需算出每个列车能够运载乘客的起始序号和结束序号。例如,从 A 到 B地,共有列车 G01 和 G07 ,并分别有 600 和 1600 个座位。那么,经过上述的累加计算,列车 G01 能够运载的乘客编号应该是 1 到 660,而 G01 能够运载的乘客编号则为 661 到 2420 (即为 660 + 1600*110%)。
上述计算也可以使用 Window Function来实现,参考实现如下:
sum(seat_count*1.1)
over (
PARTITION BY departure_station,arrival_station
ORDER BY train_id
) as p_seat_to ,合并计算结果
然后,将上述经过计算的乘客表和列车表进行 JOIN ,条件是 起始站和到达站相同,且乘客编号在列车编号之间。如果,乘客无法关联出列车,则表示无法分配列车。
该方案的最终 SQL
SELECT
p_01.p_id,
p_01.d_s,
p_01.a_s,
t_01.train_id as t_id,
p_01.seq, -- passager seq from d_s to a_s
t_01.seat_count,
@p_seat_from := (t_01.p_seat_to-t_01.seat_count*1.1 + 1) as seat_from, -- train seat from(start index)
t_01.p_seat_to as seat_to, -- train seat from(start index)
if(p_01.seq >= p_seat_to-seat_count*0.1 + 1, "ti_no_seat","...") as ti_no_seat,
@seq_in_train := p_01.seq - @p_seat_from + 1 as seq_in_train, -- seq in the train
@carriage_id := ceil(@seq_in_train/100) as t_carr_id, -- for carriage id
@row_id := ceil((@seq_in_train%100)/5) as row_id, -- row_id
@seat_id := ceil((@seq_in_train%100)%5) seat_id -- 0,1,2,3,4 A B C E F
FROM
(
select
ROW_NUMBER() over(PARTITION BY departure_station,arrival_station) as seq ,
passenger_id as p_id,
departure_station as d_s,
arrival_station as a_s
from
passenger
) as p_01
LEFT JOIN
(
select
seat_count,
sum(seat_count*1.1)
over (
PARTITION BY departure_station,arrival_station
ORDER BY train_id
) as p_seat_to ,
train_id,
departure_station as d_s ,
arrival_station as a_s
from
train
) t_01
ON
p_01.seq >= p_seat_to-seat_count*1.1 + 1
and p_01.seq <= p_seat_to
and p_01.d_s = t_01.d_s
and p_01.a_s = t_01.a_s上述实现的问题
这样的实现,是可以完成相关的座位分配。但是,却会出现一个不合理的情况,即可能有车次的座位没有分配完,但是有一部分乘客却被分配到了无座的车次。比如,从A到B的车次,有两班,第一班车600个座位,第二版1600个座位,一共有 800 个乘客的话,那么这里分配自由度就比较高,比如这种情况依旧分配了 220 个无座的座位,是否是满足要求的。
在最初,该赛题还未对外发布时,是没有该限制的。而后,发现该漏洞后,新增了一个规则,即需要先把有座的票优先分配,再分配无座的车票。
考虑优先分配有座
考虑优先分配有座的车票,再对上述实现进行一定程度的修改。
重新考虑对列车的编号和计算
对于每一趟列车X,构造一个虚拟列车X',该虚拟列车X'虚拟的负责所有的X列车的座票。而在给列车中计算起始和结束乘客编号时,则优先计算原列车的编号范围,在所有的原列车编号计算完成后,再计算X'的乘客编号范围。
这里使用 CTEs 实现该表达如下:
WITH
t_no_seat_virtual AS (
select train_id as t_id,departure_station as d_s,arrival_station as a_s,seat_count, seat_count*0.1 as seat_count_no_seat
from train ),
t_include_no_seat AS (
select t_id,d_s ,a_s ,seat_count, "with_seat" as if_seat
from t_no_seat_virtual
union
select t_id,d_s ,a_s ,seat_count_no_seat, "no_seat" as if_seat
from t_no_seat_virtual)
SELECT * from t_include_no_seat ORDER BY t_id包含虚拟列车的表 t_include_no_seat
然后把上面的实现中,表train替换成这里的 t_include_no_seat ,包含了额外的“虚拟列车”,完整的 SQL 如下:
WITH
t_no_seat_virtual AS (
select train_id as t_id,departure_station as d_s,arrival_station as a_s,seat_count, seat_count*0.1 as seat_count_no_seat
from train ),
t_include_no_seat AS (
select t_id,d_s ,a_s ,seat_count, 0 as if_no_seat
from t_no_seat_virtual
union
select t_id,d_s ,a_s ,seat_count_no_seat, 1 as if_no_seat
from t_no_seat_virtual)
select
seat_count,
sum(seat_count)
over (
PARTITION BY d_s,a_s
ORDER BY t_id,if_no_seat
) as p_seat_to ,
t_id,
d_s ,
a_s,
if_no_seat
from
t_include_no_seat返回的结果如下:
+------------+-----------+------+--------+--------+------------+
| seat_count | p_seat_to | t_id | d_s | a_s | if_no_seat |
+------------+-----------+------+--------+--------+------------+
| 600.0 | 600.0 | G109 | 上海 | 北京 | 0 |
| 60.0 | 660.0 | G109 | 上海 | 北京 | 1 |
| 1600.0 | 2260.0 | G40 | 上海 | 北京 | 0 |
| 160.0 | 2420.0 | G40 | 上海 | 北京 | 1 |
| 1600.0 | 4020.0 | G70 | 上海 | 北京 | 0 |
| 160.0 | 4180.0 | G70 | 上海 | 北京 | 1 |
| 1600.0 | 1600.0 | G113 | 上海 | 广州 | 0 |
| 160.0 | 1760.0 | G113 | 上海 | 广州 | 1 |
| 1600.0 | 3360.0 | G26 | 上海 | 广州 | 0 |
| 160.0 | 3520.0 | G26 | 上海 | 广州 | 1 |
| 1600.0 | 5120.0 | G48 | 上海 | 广州 | 0 |
| 160.0 | 5280.0 | G48 | 上海 | 广州 | 1 |
| 1600.0 | 1600.0 | G52 | 上海 | 成都 | 0 |
| 160.0 | 1760.0 | G52 | 上海 | 成都 | 1 |
| 1600.0 | 3360.0 | G8 | 上海 | 成都 | 0 |
| 160.0 | 3520.0 | G8 | 上海 | 成都 | 1 |
| 1600.0 | 1600.0 | G107 | 上海 | 武汉 | 0 |
| 160.0 | 1760.0 | G107 | 上海 | 武汉 | 1 |
| 1600.0 | 3360.0 | G17 | 上海 | 武汉 | 0 |
| 160.0 | 3520.0 | G17 | 上海 | 武汉 | 1 |这里需要注意的是,编号的 ORDER BY 需要按照 if_no_seat,t_id 进行排序,这样就可以保障,优先分配有座位的位置。
WITH
t_no_seat_virtual AS (
select train_id as t_id,departure_station as d_s,arrival_station as a_s,seat_count, seat_count*0.1 as seat_count_no_seat
from train ),
t_include_no_seat AS (
select t_id,d_s ,a_s ,seat_count, 0 as if_no_seat
from t_no_seat_virtual
union
select t_id,d_s ,a_s ,seat_count_no_seat, 1 as if_no_seat
from t_no_seat_virtual)
select
sum(seat_count)
over (
PARTITION BY d_s,a_s
ORDER BY if_no_seat,t_id
) as p_seat_to ,
seat_count,
t_id,
d_s ,
a_s,
if_no_seat
from
t_include_no_seat按照乘客序号分配座位
与前述的实现相同,首先按照始发和到达站点将旅客表与“虚拟列车”表关联。如果自己序列落在某个列车的区间中就表示有座位。
关于 row 的分配异常问题
按照上述的分配,会将编号为 100 背书的人,分配为 0F,而正确的应该是 20 F。所以,需要额外处理该数值。具体的:
ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) 修改如下:
IF( (p_01.seq-t_01.p_seat_to + t_01.seat_count)%100 = 0, "20" ,ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5)) 这部分代码实现较为冗长,更好的方法是先计算偏倚值,然后使用字符串截取函数截取,而无需写这么多的CASE ... WHEN。
完整的SQL
WITH
t_no_seat_virtual AS (
select train_id as t_id,departure_station as d_s,arrival_station as a_s,seat_count, seat_count*0.1 as seat_count_no_seat
from train ),
t_include_no_seat AS (
select t_id,d_s ,a_s ,seat_count, 0 as if_no_seat
from t_no_seat_virtual
union
select t_id,d_s ,a_s ,seat_count_no_seat, 1 as if_no_seat
from t_no_seat_virtual)
SELECT
p_01.p_id,
p_01.d_s,
p_01.a_s,
t_01.t_id as t_id,
p_01.seq, -- passager seq from d_s to a_s
t_01.seat_count,
t_01.if_no_seat,
@p_seat_from := (t_01.p_seat_to-t_01.seat_count + 1) as seat_from, -- train seat from(start index)
t_01.p_seat_to as seat_to, -- train seat from(start index)
@seq_in_train := p_01.seq - @p_seat_from + 1 as seq_in_train, -- seq in the train
@carriage_id := ceil(@seq_in_train/100) as t_carr_id, -- for carriage id
@row_id := ceil((@seq_in_train%100)/5) as row_id, -- row_id
@seat_id := ceil((@seq_in_train%100)%5) seat_id, -- 0,1,2,3,4 A B C E F
CASE
WHEN @seat_id = 1 THEN CONCAT(@row_id,"A")
WHEN @seat_id = 2 THEN CONCAT(@row_id,"B")
WHEN @seat_id = 3 THEN CONCAT(@row_id,"C")
WHEN @seat_id = 4 THEN CONCAT(@row_id,"E")
WHEN @seat_id = 0 THEN CONCAT(@row_id,"F")
ELSE "ERROR"
END as seat_index
FROM
(
select
ROW_NUMBER() over(PARTITION BY departure_station,arrival_station) as seq ,
passenger_id as p_id,
departure_station as d_s,
arrival_station as a_s
from
passenger
) as p_01
LEFT JOIN
(
select
seat_count,
sum(seat_count)
over (
PARTITION BY d_s,a_s
ORDER BY if_no_seat,t_id
) as p_seat_to ,
t_id,
d_s ,
a_s ,
if_no_seat
from
t_include_no_seat
) t_01
ON
p_01.seq >= p_seat_to-seat_count + 1
and p_01.seq <= p_seat_to
and p_01.d_s = t_01.d_s
and p_01.a_s = t_01.a_s修正SQL
最后按照题目要求,对输出结果做一些修正。具体的:
- 按要求,如果分配座位为无座的,则在车厢号展示为””,座位号显示”无座”。
- 删除中间计算结果,为了保证性能,就不在外面再套一层了,事实上,套一层可读性会更好
WITH
t_no_seat_virtual AS (
select train_id as t_id,
departure_station as d_s,
arrival_station as a_s,
seat_count, seat_count*0.1 as seat_count_no_seat
from train ),
t_include_no_seat AS (
select t_id,d_s ,a_s ,seat_count, 0 as if_no_seat
from t_no_seat_virtual
union
select t_id,d_s ,a_s ,seat_count_no_seat, 1 as if_no_seat
from t_no_seat_virtual)
SELECT
p_01.p_id,
p_01.d_s,
p_01.a_s,
t_01.t_id as t_id,
p_01.seq, -- passager seq from d_s to a_s
t_01.seat_count,
t_01.if_no_seat,
@p_seat_from := (t_01.p_seat_to-t_01.seat_count + 1) as seat_from, -- train seat from(start index)
t_01.p_seat_to as seat_to, -- train seat from(start index)
@seq_in_train := p_01.seq - @p_seat_from + 1 as seq_in_train, -- seq in the train
-- @carriage_id := ceil(@seq_in_train/100) as t_carr_id, -- for carriage id
IF(if_no_seat, "" , @carriage_id := ceil(@seq_in_train/100) ) as t_carr_id,
@row_id := ceil((@seq_in_train%100)/5) as row_id, -- row_id
@seat_id := IF( !isnull(t_01.t_id) and if_no_seat,-1,ceil((@seq_in_train%100)%5)) as seat_id, -- 0,1,2,3,4 A B C E F
CASE
WHEN @seat_id = 1 THEN CONCAT(@row_id,"A")
WHEN @seat_id = 2 THEN CONCAT(@row_id,"B")
WHEN @seat_id = 3 THEN CONCAT(@row_id,"C")
WHEN @seat_id = 4 THEN CONCAT(@row_id,"E")
WHEN @seat_id = 0 THEN CONCAT(@row_id,"F")
WHEN @seat_id = -1 THEN "无座"
ELSE NULL
END as seat_index
FROM
(
select
ROW_NUMBER() over(PARTITION BY departure_station,arrival_station) as seq ,
passenger_id as p_id,
departure_station as d_s,
arrival_station as a_s
from
passenger
) as p_01
LEFT JOIN
(
select
seat_count,
sum(seat_count)
over (
PARTITION BY d_s,a_s
ORDER BY if_no_seat,t_id
) as p_seat_to ,
t_id,
d_s ,
a_s ,
if_no_seat
from
t_include_no_seat
) t_01
ON
p_01.seq >= p_seat_to-seat_count + 1
and p_01.seq <= p_seat_to
and p_01.d_s = t_01.d_s
and p_01.a_s = t_01.a_s正确性验证
这个 SQL 的正确性并不好验证。而事实上,只要能够正确的完成这条SQL,基本上就已经打败了80%的选手了。如果性能再有一些优化,基本上已经是前10%的选手。
这里从以下几个方面对SQL正确性做初步验证:
- 对于每一个系列(始发站和到达站相同)的车次进行统计,统计座位数量和旅客数量,然后看实际分配情况是否符合
- 手动检车车厢、座位号分配的情况
- 检查某个系列,无座和有座的乘客数量
座位供需统计
座位的供需情况有如下三种:(a) 座票供应充值 (b) 加上无座后供应充值 (c) 供应不足。完整的供需计算如下:
case #1
ti_supply |__________________________|___________|
ti_needed |<------------------->|
case #2
ti_supply |__________________________|___________|
ti_needed |<------------------------------>|
case #3
ti_supply |__________________________|___________|
ti_needed |<-------------------------------------------->|
-- ti_ always short for tickets
-- p_ always short for passager
-- t_ always short for train
select
p_needed.d_s,
p_needed.a_s,
ti_needed,
ti_supply,
if( ti_needed > ti_supply, ti_needed - ti_supply , 0 ) as p_without_ti,
if( ti_needed > ti_supply/1.1 , round(ti_supply/1.1,0) , ti_needed ) as p_with_ti_with_seat,
if( ti_needed <= ti_supply/1.1 , -- case #1
0,
if( ti_needed <= ti_supply, -- case #2
round(ti_needed - ti_supply/1.1,0) ,
ti_supply/11 -- case #3
)
) as p_with_ti_without_seat
from
(
select
-- passenger_id as p_id,
departure_station as d_s,
arrival_station as a_s,
count(1) as ti_needed
from
passenger
group by
departure_station,arrival_station
) p_needed
,
(
select
-- train_id t_id,
departure_station as d_s ,
arrival_station as a_s,
1.1*sum(seat_count) as ti_supply
from
train
group by
departure_station,arrival_station
) t_supply
WHERE
p_needed.d_s = t_supply.d_s
and p_needed.a_s = t_supply.a_s返回的供需表如下:
+--------+--------+-----------+-----------+--------------+---------------------+------------------------+
| d_s | a_s | ti_needed | ti_supply | p_without_ti | p_with_ti_with_seat | p_with_ti_without_seat |
+--------+--------+-----------+-----------+--------------+---------------------+------------------------+
| 上海 | 北京 | 2460 | 4180.0 | 0 | 2460 | 0 |
| 上海 | 广州 | 2406 | 5280.0 | 0 | 2406 | 0 |
| 上海 | 成都 | 2421 | 3520.0 | 0 | 2421 | 0 |
| 上海 | 武汉 | 2454 | 7700.0 | 0 | 2454 | 0 |
| 上海 | 深圳 | 2388 | 7040.0 | 0 | 2388 | 0 |
| 北京 | 上海 | 2381 | 1760.0 | 621.0 | 1600 | 160.00000 |
| 北京 | 广州 | 2448 | 3520.0 | 0 | 2448 | 0 |
| 北京 | 成都 | 2384 | 3520.0 | 0 | 2384 | 0 |
| 北京 | 杭州 | 2478 | 3520.0 | 0 | 2478 | 0 |
| 北京 | 武汉 | 2404 | 5940.0 | 0 | 2404 | 0 |
| 北京 | 深圳 | 2342 | 3520.0 | 0 | 2342 | 0 |
| 广州 | 上海 | 2339 | 4180.0 | 0 | 2339 | 0 |
| 广州 | 北京 | 2368 | 1760.0 | 608.0 | 1600 | 160.00000 |
| 广州 | 成都 | 2332 | 3520.0 | 0 | 2332 | 0 |
| 广州 | 杭州 | 2407 | 5280.0 | 0 | 2407 | 0 |
| 广州 | 武汉 | 2320 | 3520.0 | 0 | 2320 | 0 |
| 广州 | 深圳 | 2352 | 1760.0 | 592.0 | 1600 | 160.00000 |
| 成都 | 上海 | 2422 | 4180.0 | 0 | 2422 | 0 |
| 成都 | 北京 | 2318 | 5940.0 | 0 | 2318 | 0 |
| 成都 | 广州 | 2450 | 1760.0 | 690.0 | 1600 | 160.00000 |
| 成都 | 杭州 | 2343 | 5280.0 | 0 | 2343 | 0 |
| 成都 | 武汉 | 2415 | 5280.0 | 0 | 2415 | 0 |
| 成都 | 深圳 | 2364 | 2420.0 | 0 | 2200 | 164 |
| 杭州 | 北京 | 2389 | 1760.0 | 629.0 | 1600 | 160.00000 |
| 杭州 | 成都 | 2370 | 1760.0 | 610.0 | 1600 | 160.00000 |
| 杭州 | 深圳 | 2387 | 10560.0 | 0 | 2387 | 0 |
| 武汉 | 上海 | 2323 | 5280.0 | 0 | 2323 | 0 |
| 武汉 | 北京 | 2453 | 5280.0 | 0 | 2453 | 0 |
| 武汉 | 广州 | 2395 | 10560.0 | 0 | 2395 | 0 |
| 武汉 | 成都 | 2337 | 1760.0 | 577.0 | 1600 | 160.00000 |
| 武汉 | 杭州 | 2428 | 3520.0 | 0 | 2428 | 0 |
| 武汉 | 深圳 | 2390 | 5280.0 | 0 | 2390 | 0 |
| 深圳 | 上海 | 2251 | 3520.0 | 0 | 2251 | 0 |
| 深圳 | 北京 | 2309 | 7040.0 | 0 | 2309 | 0 |
| 深圳 | 成都 | 2341 | 3520.0 | 0 | 2341 | 0 |
| 深圳 | 杭州 | 2412 | 660.0 | 1752.0 | 600 | 60.00000 |
| 深圳 | 武汉 | 2329 | 10120.0 | 0 | 2329 | 0 |
+--------+--------+-----------+-----------+--------------+---------------------+------------------------+SQL 计算返回结果统计
先使用 CREATE TABLE t_ret ...将结果集存储一个中间的临时表。
然后,再计算 SQL返回结果表中的统计数据:
SELECT
d_s,a_s,
CASE
WHEN ISNULL(seat_index) THEN "p_without_ti"
WHEN seat_index = "无座" THEN "p_with_ti_without_seat"
ELSE "p_with_ti_with_seat"
END as p_status,
COUNT(1)
FROM t_ret
GROUP BY d_s,a_s , p_status返回:
+--------+--------+------------------------+----------+
| d_s | a_s | p_status | COUNT(1) |
+--------+--------+------------------------+----------+
| 上海 | 北京 | p_with_ti_with_seat | 2460 |
| 上海 | 广州 | p_with_ti_with_seat | 2406 |
| 上海 | 成都 | p_with_ti_with_seat | 2421 |
| 上海 | 杭州 | p_without_ti | 2373 |
| 上海 | 武汉 | p_with_ti_with_seat | 2454 |
| 上海 | 深圳 | p_with_ti_with_seat | 2388 |
| 北京 | 上海 | p_with_ti_with_seat | 1600 |
| 北京 | 上海 | p_with_ti_without_seat | 160 |
| 北京 | 上海 | p_without_ti | 621 |
| 北京 | 广州 | p_with_ti_with_seat | 2448 |
| 北京 | 成都 | p_with_ti_with_seat | 2384 |
| 北京 | 杭州 | p_with_ti_with_seat | 2478 |
| 北京 | 武汉 | p_with_ti_with_seat | 2404 |
| 北京 | 深圳 | p_with_ti_with_seat | 2342 |
| 广州 | 上海 | p_with_ti_with_seat | 2339 |
| 广州 | 北京 | p_with_ti_with_seat | 1600 |
| 广州 | 北京 | p_with_ti_without_seat | 160 |
| 广州 | 北京 | p_without_ti | 608 |
| 广州 | 成都 | p_with_ti_with_seat | 2332 |
| 广州 | 杭州 | p_with_ti_with_seat | 2407 |
| 广州 | 武汉 | p_with_ti_with_seat | 2320 |
| 广州 | 深圳 | p_with_ti_with_seat | 1600 |
| 广州 | 深圳 | p_with_ti_without_seat | 160 |
| 广州 | 深圳 | p_without_ti | 592 |
| 成都 | 上海 | p_with_ti_with_seat | 2422 |
| 成都 | 北京 | p_with_ti_with_seat | 2318 |
| 成都 | 广州 | p_with_ti_with_seat | 1600 |
| 成都 | 广州 | p_with_ti_without_seat | 160 |
| 成都 | 广州 | p_without_ti | 690 |
| 成都 | 杭州 | p_with_ti_with_seat | 2343 |
| 成都 | 武汉 | p_with_ti_with_seat | 2415 |
| 成都 | 深圳 | p_with_ti_with_seat | 2200 |
| 成都 | 深圳 | p_with_ti_without_seat | 164 |
| 杭州 | 上海 | p_without_ti | 2376 |
| 杭州 | 北京 | p_with_ti_with_seat | 1600 |
| 杭州 | 北京 | p_with_ti_without_seat | 160 |
| 杭州 | 北京 | p_without_ti | 629 |
| 杭州 | 广州 | p_without_ti | 2401 |
| 杭州 | 成都 | p_with_ti_with_seat | 1600 |
| 杭州 | 成都 | p_with_ti_without_seat | 160 |
| 杭州 | 成都 | p_without_ti | 610 |
| 杭州 | 武汉 | p_without_ti | 2353 |
| 杭州 | 深圳 | p_with_ti_with_seat | 2387 |
| 武汉 | 上海 | p_with_ti_with_seat | 2323 |
| 武汉 | 北京 | p_with_ti_with_seat | 2453 |
| 武汉 | 广州 | p_with_ti_with_seat | 2395 |
| 武汉 | 成都 | p_with_ti_with_seat | 1600 |
| 武汉 | 成都 | p_with_ti_without_seat | 160 |
| 武汉 | 成都 | p_without_ti | 577 |
| 武汉 | 杭州 | p_with_ti_with_seat | 2428 |
| 武汉 | 深圳 | p_with_ti_with_seat | 2390 |
| 深圳 | 上海 | p_with_ti_with_seat | 2251 |
| 深圳 | 北京 | p_with_ti_with_seat | 2309 |
| 深圳 | 广州 | p_without_ti | 2387 |
| 深圳 | 成都 | p_with_ti_with_seat | 2341 |
| 深圳 | 杭州 | p_with_ti_with_seat | 600 |
| 深圳 | 杭州 | p_with_ti_without_seat | 60 |
| 深圳 | 杭州 | p_without_ti | 1752 |
| 深圳 | 武汉 | p_with_ti_with_seat | 2329 |
+--------+--------+------------------------+----------+从上述的两个结果对比来看,挑选了几个来看,数据是一致的。比如,“深圳->杭州”,上面表格计算得
| 深圳 | 杭州 | 2412 | 660.0 | 1752.0 | 600 | 60.00000 |对比:
| 深圳 | 杭州 | p_with_ti_with_seat | 600 |
| 深圳 | 杭州 | p_with_ti_without_seat | 60 |
| 深圳 | 杭州 | p_without_ti | 1752 |这里的 600、60、1752也是一致的。
最后按照输出进行调整
WITH
t_no_seat_virtual AS (
select
train_id as t_id,
departure_station as d_s,
arrival_station as a_s,
seat_count,
seat_count*0.1 as seat_count_no_seat
from train
),
t_include_no_seat AS (
select t_id,d_s ,a_s ,seat_count, 0 as if_no_seat
from t_no_seat_virtual
union
select t_id,d_s ,a_s ,seat_count_no_seat, 1 as if_no_seat
from t_no_seat_virtual
)
SELECT
p_01.p_id, -- output 01
p_01.d_s, -- output 02
p_01.a_s, -- output 03
t_01.t_id as t_id, -- output 04
IF(
if_no_seat,
"" ,
ceil((p_01.seq-t_01.p_seat_to + t_01.seat_count)/100)
) as t_carr_id, -- output 05
CASE IF( !isnull(t_01.t_id) and if_no_seat,-1,ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)%5))
WHEN 1 THEN CONCAT( ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) ,"A")
WHEN 2 THEN CONCAT( ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) ,"B")
WHEN 3 THEN CONCAT( ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) ,"C")
WHEN 4 THEN CONCAT( ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5) ,"E")
WHEN 0 THEN CONCAT( IF( (p_01.seq-t_01.p_seat_to + t_01.seat_count)%100 = 0, "20" ,ceil((( p_01.seq-t_01.p_seat_to + t_01.seat_count )%100)/5)) ,"F")
WHEN -1 THEN "无座"
ELSE NULL
END as seat_index -- output 06
FROM
(
select
ROW_NUMBER() over(PARTITION BY departure_station,arrival_station) as seq ,
passenger_id as p_id,
departure_station as d_s,
arrival_station as a_s
from
passenger
) as p_01
LEFT JOIN
(
select
seat_count,
sum(seat_count)
over (
PARTITION BY d_s,a_s
ORDER BY if_no_seat,t_id
) as p_seat_to ,
t_id,
d_s ,
a_s ,
if_no_seat
from
t_include_no_seat
) t_01
ON
p_01.seq >= p_seat_to-seat_count + 1
and p_01.seq <= p_seat_to
and p_01.d_s = t_01.d_s
and p_01.a_s = t_01.a_s
ORDER BY p_01.p_id赛题与数据
原始的比赛题目参考:https://www.ninedata.cloud/sql_train2024 这里仅讨论其中的“进阶挑战”。
表定义(MySQL)
CREATE DATABASE `game_ticket`;
use game_ticket;
CREATE TABLE `passenger` (
`passenger_id` varchar(16) NOT NULL,
`departure_station` varchar(32) NOT NULL,
`arrival_station` varchar(32) NOT NULL,
PRIMARY KEY (`passenger_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `train` (
`train_id` varchar(8) NOT NULL,
`departure_station` varchar(32) NOT NULL,
`arrival_station` varchar(32) NOT NULL,
`seat_count` int NOT NULL,
PRIMARY KEY (`train_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;赛题数据
为了方便调试,这里保持了一份CSV的输入如下,供测试使用: