从一个Slide介绍中,在Sysbench测试中可以通过hook的方式对一些MySQL报错进行捕获,以避免测试中断。但是做了一些搜索,对该能力并没有文档描述,故做了一些测试,以验证该能力。
在前面的文章“Sysbench压测MySQL中遇到的”Duplicate entry”问题”中,较为详细的分析了在使用了--skip_trx=on后 ,Sysbench(版本1.0.20)在测试中遇到的”Duplicate entry”问题。也提到了,可以在脚本中添加hook的方式解决,不过之前并没有对这个方案进行验证。
在测试脚本中使用hook的方案,在sysbench的文档中并没有找到详细的说明,这里将对这个方案做一个使用说明,并验证其有效性。我们将分两组对比测试,验证新增hook的有效性,以及新增hook后,对测试结果是否对性能有影响。
测试结果概述
Sysbench的该能力并没有在文档中找到说明,只是在一个Slide中看到的。本文的测试验证了如下内容:
- 在测试lua脚本中,可以使用hook有效的避免”Duplicate entry”等报错带来的测试中断问题
- 使用了hook之后,测试前后性能并没有观测到差异(可以认为,一般来说,发生错误的情况并不多)
所以,后续测试中,如果不可避免的会遇到”Duplicate entry”报错(或其他报错)时,将使用hook的方式来避免。
如何修改测试脚本
具体的,我们在原来的oltp_read_write(sysbench 1.0.20版本)脚本中新增如下代码片段:
function sysbench.hooks.sql_error_ignorable(err)
if err.sql_errno == 1062 then -- ER_DUP_ENTRY
-- do nothing
return true
end
end
完整的代码可以参考:oltp_read_write_with_hooks.lua
具体的diff文件参考如下:
--- /usr/share/sysbench/oltp_read_write.lua
+++ oltp_read_write_with_hooks.lua
@@ -21,6 +21,13 @@
require("oltp_common")
+function sysbench.hooks.sql_error_ignorable(err)
+ if err.sql_errno == 1062 then -- ER_DUP_ENTRY
+ -- do nothing
+ return true
+ end
+end
+
function prepare_statements()
if not sysbench.opt.skip_trx then
prepare_begin()
测试说明
这里依旧使用oltp_read_write负载进行测试,测试时使用了参数 --skip_trx=on --db-ps-mode=disable --rand-type=uniform ,其中参数--skip_trx=on会带来”Duplicate entry”报错,并导致测试被终止(详细原因分析参考:Sysbench压测MySQL中遇到的”Duplicate entry”问题)。测试分两组,一组是使用原始的oltp_read_write脚本进行测试;另一组,则在脚本中新增上述hook代码。
而后观测:
- 使用了hook后,sysbench是否还会因为”Duplicate entry”被终止;
nohup ./sysbench_auto.sh -l ./oltp_read_write_with_hook.lua -hYOUR_HOST -uYOUR_USERNAME -pYOUR_PASSWORD > sysbench_with_hook_with_skip.log 2>&1 &
- 使用hook,与不使用hook,对测试结果是否有影响。
nohup ./sysbench_auto.sh -hYOUR_HOST -uYOUR_USERNAME -pYOUR_PASSWORD > sysbench_no_hook_with_skip.log 2>&1 &
这里的sysbench_auto.sh是一个自己编写的自动化的sysbench测试脚本。会自动化的、顺序的进行多个不同并发下的性能测试。
测试结果详情
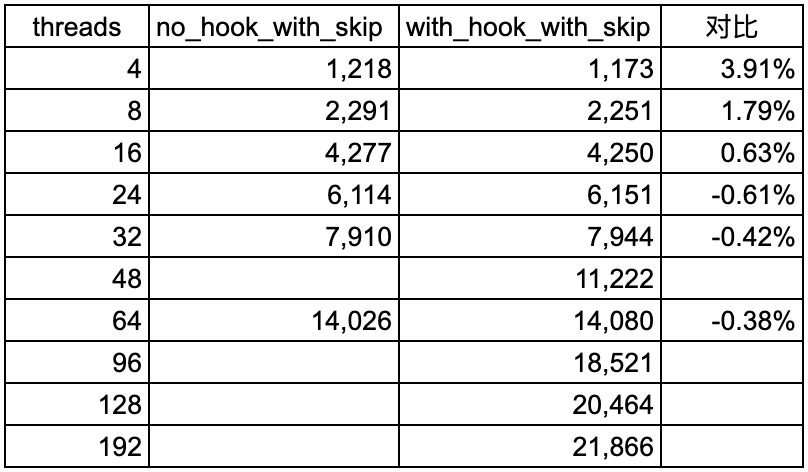
没有使用hook的测试中,注意到,在并发度为48、96、128、192时候,测试被终止,而观测日志也看到了是因为“Duplicate entry”所导致的。
threads|transactions| queries| time |avg/Latency|95%/Latency
4| 20311| 365598|300.05| 59.09| 66.84
8| 38195| 687510|300.04| 62.84| 71.83
16| 71296| 1283328|300.07| 67.33| 77.19
24| 101911| 1834398|300.05| 70.65| 81.48
32| 131859| 2373462|300.06| 72.81| 84.47
48| 0| 0| 0.00| 0.00| 0.00
64| 233840| 4209120|300.09| 82.12| 101.13
96| 0| 0| 0.00| 0.00| 0.00
128| 0| 0| 0.00| 0.00| 0.00
192| 0| 0| 0.00| 0.00| 0.00
具体报错:
FATAL: mysql_drv_query() returned error 1062 (Duplicate entry '876663' for key 'sbtest3.PRIMARY') for query
在使用了hook的测试中,注意到,测试顺利的完成了,并没有被终止,而观察日志,也可以看到,期间也是遇到了Duplicate entry报错的,但因为hook的处理,测试并没有终止。
threads|transactions| queries| time |avg/Latency|95%/Latency
4| 19547| 351846|300.06| 61.40| 71.83
8| 37524| 675432|300.06| 63.97| 74.46
16| 70847| 1275246|300.05| 67.76| 78.60
24| 102541| 1845738|300.06| 70.22| 81.48
32| 132424| 2383632|300.07| 72.50| 86.00
48| 187065| 3367170|300.06| 76.98| 92.42
64| 234717| 4224923|300.07| 81.81| 99.33
96| 308744| 5557409|300.06| 93.28| 118.92
128| 341177| 6141186|300.09| 112.57| 147.61
192| 364561| 6562115|300.10| 158.03| 211.60
两组测试性能的对比
根据如上性能测试数据,对QPS(Queries Per Second)进行对比:
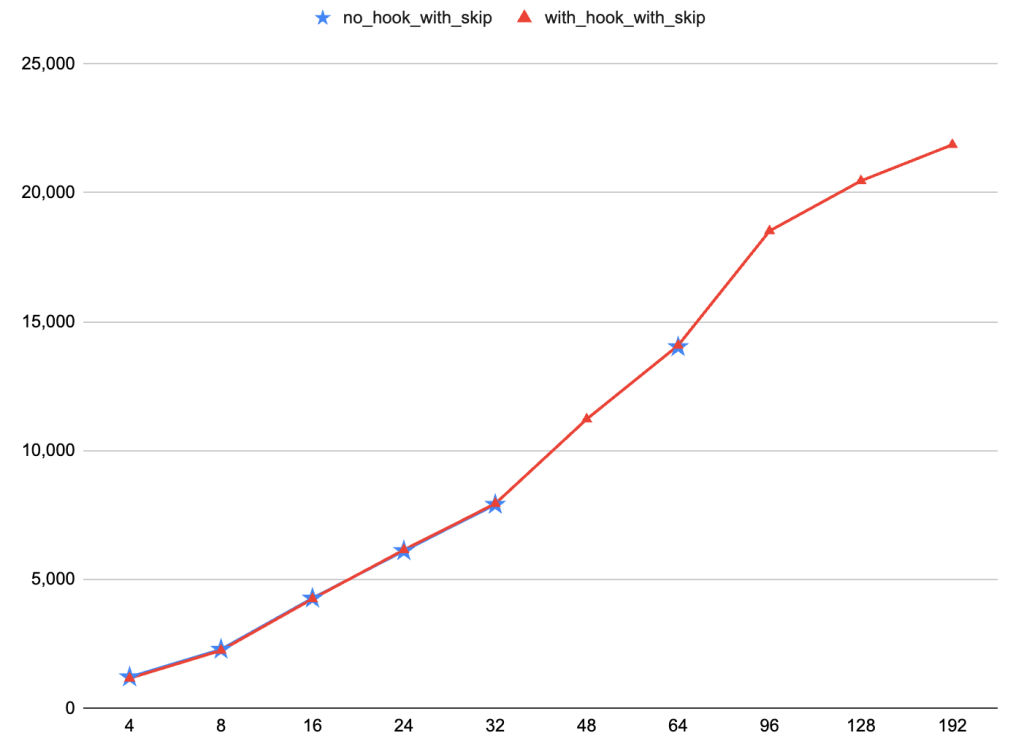
可以看到,整体性能波动非常小,优势在较高并发时,性能差异都小于1%;从趋势图上也能够看出来,两者几乎是重合的。
更多测试原始数据
2024-03-26@Benchmark on sysbench with or without hook
host : rds_m6i_xlarge_no_hook_with_skip
sub_dir : rds_m6i_xlarge_no_hook_with_skip
ins_code : m6i.xlarge
ha_type : ha
region : tokyo
storage_size : 100
iops : 3000
sysbench for host :multiaz.cjzowaj9vqpd.ap-northeast-1.rds.amazonaws.com
threads|transactions| queries| time |avg/Latency|95%/Latency
4| 20311| 365598|300.05| 59.09| 66.84
8| 38195| 687510|300.04| 62.84| 71.83
16| 71296| 1283328|300.07| 67.33| 77.19
24| 101911| 1834398|300.05| 70.65| 81.48
32| 131859| 2373462|300.06| 72.81| 84.47
48| 0| 0| 0.00| 0.00| 0.00
64| 233840| 4209120|300.09| 82.12| 101.13
96| 0| 0| 0.00| 0.00| 0.00
128| 0| 0| 0.00| 0.00| 0.00
192| 0| 0| 0.00| 0.00| 0.00
host : rds_m6i_xlarge_with_hook_with_skip
sub_dir : rds_m6i_xlarge_with_hook_with_skip
ins_code : m6i.xlarge
ha_type : ha
region : tokyo
storage_size : 100
iops : 3000
sysbench for host :multiaz.cjzowaj9vqpd.ap-northeast-1.rds.amazonaws.com
threads|transactions| queries| time |avg/Latency|95%/Latency
4| 19547| 351846|300.06| 61.40| 71.83
8| 37524| 675432|300.06| 63.97| 74.46
16| 70847| 1275246|300.05| 67.76| 78.60
24| 102541| 1845738|300.06| 70.22| 81.48
32| 132424| 2383632|300.07| 72.50| 86.00
48| 187065| 3367170|300.06| 76.98| 92.42
64| 234717| 4224923|300.07| 81.81| 99.33
96| 308744| 5557409|300.06| 93.28| 118.92
128| 341177| 6141186|300.09| 112.57| 147.61
192| 364561| 6562115|300.10| 158.03| 211.60