AI-LLM
-

在最初尝试了解 diffusion 模型的时候,原本是打算跳过 VAE (Variational Autoencoder 变分自编码 )模型的,后面发现有点跳不过去。再花了一些时间去了解 VAE,才意识到其实不应该跳过去,相反的,了解 VAE 实现的一些架构、原理、直觉、初衷、数学原理则可以大大帮助理解后续的生成模型。
目录
1. 为什么现在你依旧需要了解 VAE
“潜空间”(latent space)的处理依旧是现代(SOTA)生成模型最为核心的组件。而从autoencoder模型,扩展到 VAE 模型,则是生成模型走出的关键步骤之一。将潜空间限制在一个正态分布的空间内,然后,在这个空间进行采样后进行 decoder 的生成思想,则是现代生成模型很多思想来时的路。
如果跳过这一段,很多的概念则会显得非常突然。
2. VAE 关键直觉与主要思想
2.1 关键直觉
在计算机与数学科学中有几个概念是反复出现的,其中之一就是“高斯分布”(或者叫“正态分布”)。在图像生成模型中非常关键的,则是将潜空间限制在了一个正态分布之中,为什么会这样?似乎并没有人去说明这一点,这里做一个简单的阐述和理解。高斯分布可以理解为大量伯努利分布的极限形式,现实世界的分布我们通常会假设其为大量微小因子的共同作用下的宏观表现,故通常假设其满足高斯分布。
那这与 VAE 有什么关系呢?在经典的 Guassian VAE 中,一个关键假设是:“潜空间” \(z \) 符合高斯分布的(通过训练来将其拉向高斯分布)。然后再对潜空间采样后,就可以生成较为“逼真”的图像了。那么假设“潜空间” \(z \) 符合高斯分布有什么深意吗?还是只是为了方便采样?
从直觉构建的角度,我们可以这样认为:潜空间的每个“维度”都有某这非常强的意义,例如色彩、风格、类型等,那么则有理由相信,一个对象在每一个“维度”上的分布也是符合正态分布的。即“潜空间”是一个符合正态分布的空间,那么从这个样本空间进行采样时,也就更容易得到一个有代表意义的点。
2.2 VAE 的主要思想
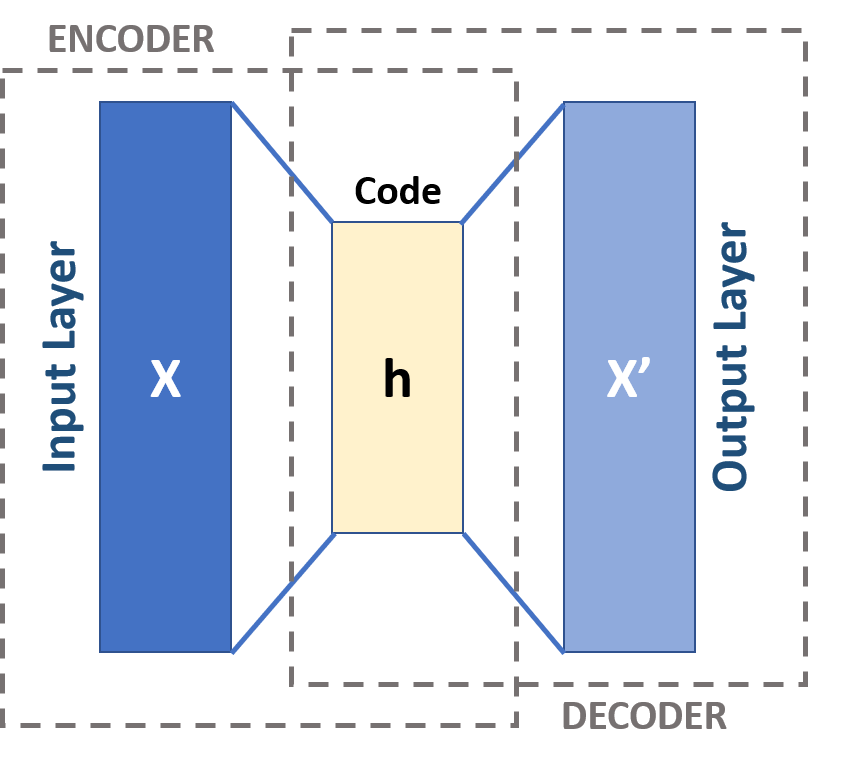
如何使用“神经网络”生成“逼真”的数据(例如图片、视频等)呢?在机器学习领域,一个比较自然的探索是从“autoencoder”架构去做一些尝试:“autoencoder” 由一个确定的encoder 将输入压缩到一个低维的“潜编码”(latent code)空间中,然后再由decoder根据“latent code”重建数据。
如右图所示,对于这样的神经网络设计其优势是非常明显的,这可以是非常好的“无监督学习”的神经网络,对比最终输出和输入的数据即可以作为损失函数。
但,在数据生成(例如新的图像生成)上,这样的设计在实践中也有着非常明显的限制:即对于如果随机选取一个“latent code”,通常只能生成一些无意义的数据。
2013年的 “Variational Autoencoder (VAE)” (Kingma and Welling, 2013) 架构则尝试解决这个问题:将“潜空间”(latent space)设计为某个符合某个概率分布结构。终于,可以生成出色的、逼真的数据(例如“图像”)。
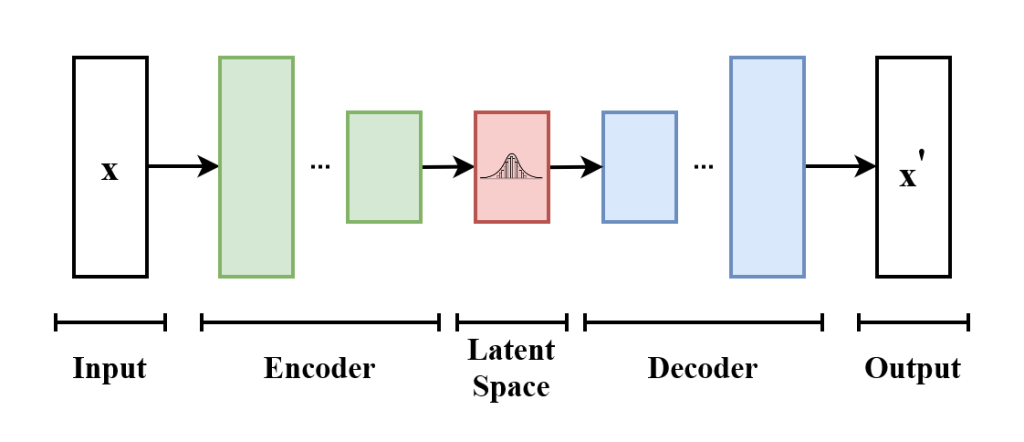

上述的描述可能还是比较抽象的,下面将实现一个基础的“VAE”模型,从而观测该模型的各个模块。
3. 一个简单的 VAE 模型的观测
3.1 模型架构概述
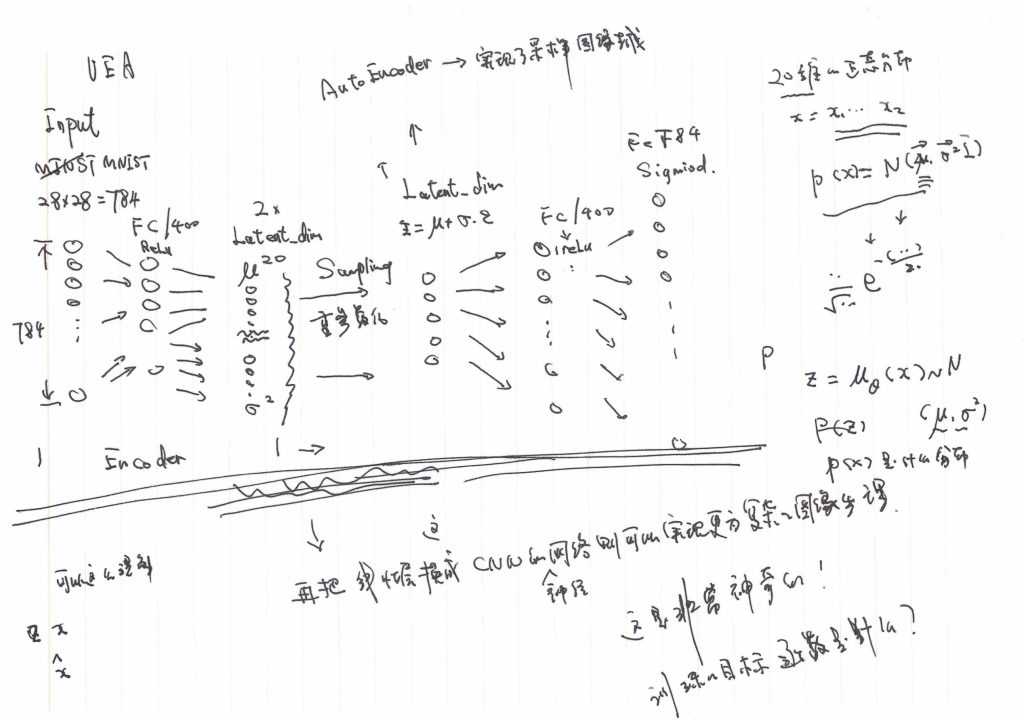
这里实现了(主要靠Gemini)一个由多个全连接层构成 VAE 模型。输入是 MNIST 数据集,输入层维度是 \(28 \times 28 = 784 \),中间的潜空间(Latent Space)维度为 20 ,包括 20 个均值和20个方差,然后是一个基本对称的decoder,包括一个400个神经元的全连接层和一个784个神经元的输出层,手绘描述如右图。
相关的代码实现参考:VAE-my-practice.ipynb。
这个神经网络结构之简单、生成效果之惊人,我自己是有点被震惊了的,相比于Autoencoder ,这里将“潜空间”限制在了某个概率分布之中,更为具体的是将每一个样本都“尝试”映射到正态分布中(注:\(p(z|x) \)是正态分布)。这里的“尝试”的做法是,先让神经网络输出“均值”和“方差”,然后再做一次重参数化的“采样”(Sampling)得到 \(z \)。
说明:\(p(z|x) \)是正态分布;从模型架构上看,\(p(z) \) 似乎并不是正态分布,但最终由训练的目标函数将\(p(z) \) “拉向”一个正态分布。
3.2 模型效果观测:某个点附近的数据

这里使用上述模型,将 MNIST 数据集中的一张原始图片计算出对应的正态分布,即均值和方差,然后使用该均值和方差进行了 11 一次采样,再生成 11 张图片,可以看到这些生成的图片和原始图片有非常高的相似度,同时又与原始图片不同。
即达到了生成“逼真”图片的效果。这种实现范式,展现出了非常强的图片生成潜力。也是后续 diffusion 模型的重要基础之一。

再从 \(z \sim \mathcal{N}(0,I) \) 随机采样一些值,再看看这些随机生成的效果,如右图。
可以看到,基本上能够生成一些有意义的图。这里只是使用了一些全连接层,即可以产生非常好的效果,可以预期,如果使用卷积神经网络,是可以有更好的效果的。
3.3 模型效果观测:空间中交接处的情况
从构建直觉的角度我们可以这样理解,encoder 层将原始的“向量空间”映射到了一个“潜空间”(latent space),该潜空间中的数据符合标准正态分布。所以,这就使得我们在“潜空间”变量 \(z \) 中做一个标准正态分布的采样,就可以使用 decoder 生成一个有意义的图片。并且,从构建直觉的角度,我们可以认为decoder 将正态分布中的点映射到“10个”数字的“空间”(784维)中,甚至可以认为(直觉角度)目标空间中有一片“连续”的空间即为“像空间”,这些空间某种程度可以“聚类”为“10类”,这些聚类的边缘则是一些介于不同数字之间的难以辨认的数字。
例如,我们考虑这样观测这些“聚类”中数字“1”和数字“0”之间的图像。我们先使用encoder计算(找一张图片作为输入)出数字“1”、“0”对应的均值,并以此作为对应数字在“潜空间”中的中心(更为严格的可以多计算一些相同的数字,再计算均值),然后在“1”、“1”对应的质心之间进行插值,然后观测这些“插值”经过encoder后的图片。

在放大33% ~ 66% 这个关键阶段:

3.4 模型小结
如上所述,encoder 最终把“原始的数据”映射到一个“潜空间”(latent space),“潜空间”中的数据(在线性代数中类似的概念称为“像空间”)符合正态分布。从从构建直觉角度我们可以有如下的一些理解和疑问。
VAE 模型尝试把“潜空间”限制在一个非常小区域,即以“原点”为中心的一个小“球”中(想想 3 \(\sigma \) 内就可能覆盖了 99.73% 的点),更为准确的是一片标准正态分布的概率云当中。问题:这种把“像空间”限制在小区域内,是否是实现“逼真生成”的关键因素?尝试回答:像空间的大小也许并不是关键的,毕竟,从数学角度来看,单位“球”可能与整个空间是一样大的,只是看起来小了而已;那么,关键可能在于把“像空间”现在在了某种结构上,这里的结构是标准正态分布空间。问题:为什么把“像空间”限制在某种结构上,就能够达到这样的效果呢?
在上述示例的“概率云”中,所有的点并不是“对等的”,概率密度相等的点,其意义也有着非常大的区别。从直觉的角度,例如最某个数字1的点 \(z_1 \in z \),在点 \(z_1 \) 附近的点则映射到的“像”也是更为接近的与数字“1”的点(这里的 \(z_1 = q_{\theta}(x) \quad \text{where} \, x \in \text{Samples} \))。
4. VAE 实现的一些细节
4.1 VAE的训练目标
VAE 模型将潜空间限制在了一个“正态分布”之中,通过在正态分布中采样的方式用来生成新的图片。这个过程并不是很好理解,这里介绍一下 VAE 的数学建模思路。
模型的训练目标(ELBO):
$$
\min_{\theta,\phi} \mathbb{E}_{q_{\theta}(z|x)}[\frac{1}{2\sigma^2}|| x-\mu_{\phi}(z) ||^2] + \mathcal{D}_{KL}(q_{\theta}(z|x)||p(z) ) \tag{1}
$$关于这个式子的完整的数学推导,在网上比较好找到,有一些复杂、也不是很好理解。但是,这个式子的意义却比较明确:
- 前一部分,对于某个输入 \(x \),需要神经网络的参数 \(\theta , \phi \) 生成的图像\(x’ \)能够与原始图像接近
- 后半部分,则让神经网络参数\(\theta \) 是的分布 \(q_{\theta}(z|x) \) 靠近 \(p(z) \)即标准正态分布
4.2 VAE的数学模型
理解 VAE 比较困难的大概是这背后的数学模型,而理解了这个“数学模型”才可能进一步理解上述的公式,以及更多的VAE以及后续生成模型的思想。所以这里总结一些我对这个“数学模型”的理解:
Encoder 部分 \(q_{\theta} \) 是将一个图片 \(x \) 映射到一个概率分布(而不是某个具体的值),通常是 \(\mathcal{N}(\mu,\sigma^2) \)。那么,在神经网络中,如何将一个具体的样本/数据 \(x \) 映射到一个概率分布呢?是这样的:神经网络则需要输出/拟合/回归出该分布的关键参数即可,例如对于正态分布只需要给均值和方差即可。这也是为什么在上述的“示例VAE”中 Encoder 部分输出即为分布 \(z \sim p(z) \) 的均值与方差。那么,要从潜空间 \(z \) 中取一个值(即采样一个值)的时候,则需要“随机”的做一次生成,这里的“随机”则使用了“重参数化”技巧进行处理从而解决训练时向后传播的随机性问题。更为一般的即:$$ q_{\theta}(z|x) := \mathcal{N}(z;\mu_{\theta}(x),\text{diag}(\sigma_{\theta}^2(x))) \tag{2} $$
Decoder 部分 \(p_{\phi} \) 则是将潜空间的采样 \(z \) 映射到一个概率分布,而不是一个具体的值,但这里可能感觉是一个具体指的原因是,通常输出就是这个分布的均值(或期望),而不再另外进行采样操作。在常见的 Gaussian VAE 中,更为一般的有:
$$ p_{\phi}(x|z) := \mathcal{N}(x;\mu_{\phi}(z),\sigma^2 I) \tag{3} $$
最后,有了这两个定义公式(2)、(3),就可以计算上述的损失函数公式(1)了。
5. VAE 中的数学推导
这大概是最难理解的部分,甚至注意到很多领域内的专家(更加注重实践能力),对于这部分也很头疼,这里做一些尝试。
5.1 VAE 基本数学概率模型与训练目标
我们有一个上述的 VAE 模型,其中:
- \(\theta \) 为encoder部分参数,\(\phi \) 为decoder 的参数
- \(p_{\theta}(z|x) \) 表示对于给定的输入 \(x \),encoder 将输入映射为分布\(p_{\theta}(z|x) \) ,通常按照上述的公式(2)定义
- \(p_{\phi}(x|z) \) 表示对于给定的潜空间采样值 \(z \),decoder 将其映射为分布\(p_{\phi}(x|z) \) ,通常按照上述的公式(3)定义
在数学形式上,就可以有目标端(神经网络的输出)\(x \) 的分布:
$$
p_{\phi}(x) = \int p_{\phi}(x|z)p(z)dz
$$这是一个形式上的表达,并不能直接计算,这是因为 \(p_{\phi}(x|z) \) 是一个由神经网络定义的映射或分布,对于每一个 \(z \),并没有一个简单的表达式给出\(p_{\phi}(x|z) \)的形式,或者更为直接的,在公式(3)中的 \(\mu_{\phi}(z) \) 由神经网络定义,并没有数学形式的表达。
这个式子确实不可计算,在实际训练中,则做了一些数学“推导”,训练另一个与此相关的式子(ELBO),这个我们后续再看。
所以,对于 VAE 模型的训练,即需要最大化:
$$
\max_{\phi}\sum_\limits{i} \log p_{\phi}(x_i) \quad \forall x_i \in \text{Sample Data} \tag{4}
$$即对于最终的概率分布(PDF)\(p_{\phi}(x) \),任何的真实的图像(对应的 \(\forall x \in {\text{data}} \))所对应的密度值取值都需要很大,才能最终使得上述式子取值最大。
这似乎还比较抽象,这里我们进一步解释一下上述的式子(4)。考虑真实分布为 \(p_{\text{data}}(x) \),通常我们可以使用 KL 散度衡量两个分布的距离,那么,就需要最小化这个散度值:
$$
\begin{aligned}
\mathcal{D}_{\text{KL}} &= \int p_{\text{data}}(x) \log \frac{p_{\text{data}}(x)}{ p_{\phi}(x)}dx \\[0.8em]
&= \int p_{\text{data}}(x) \log p_{\text{data}}(x)dx – \int p_{\text{data}}(x) \log p_{\phi}(x)dx
\end{aligned}
$$上述式子中的前项是一个常数(认为真实世界的分布是确定的,是拟合的目标,其实就是这个分布的“熵”),那么要这个散度值最小,就是让上述式子中后一项最大,即 \(\int p_{\text{data}}(x)p_{\phi}(x)dx \) 最大;在离散场景,积分则变成求和,并且 \(p_{\text{data}}(x) \)通常不可知,则通常使用\(\frac{1}{N} \)替代或者直接忽略,即有上面的式子(4)。
5.2 使用 ELBO 对上述目标进行近似
关于“Evidence Lower Bound” (简称 ELBO )虽然网上有很多的说明,但总是不够细致(或者要求对概率论有非常深的理解),这里做一个最为详细的推导和说明如下(应该是互联网上能够找到的最为详细的说明了)。
ELBO的定义为:
$$
\mathcal{L}_{\text{ELBO}}
=
\underbrace{
\mathbb{E}_{z \sim q_\theta(z|x)}
\left[ \log p_\phi(x|z) \right]
}_{\text{Reconstruction Term}}
–
\underbrace{
D_{\mathrm{KL}}\!\left( q_\theta(z|x) \,\|\, p(z) \right)
}_{\text{Latent Regularization}}
$$可以通过严格的证明,如下不等式成立:
$$
\begin{equation}
\log p_\phi(x) \ge \mathcal{L}_{\text{ELBO}}(\theta, \phi; x)
\end{equation}
$$证明如下:
$$
\begin{aligned}
\log p_\phi(x) &\stackrel{(1)}{=} \log \int p_\phi(x, z) \, dz \\[0.8em]
&\stackrel{(2)}{=} \log \int q_\theta(z|x) \frac{p_\phi(x, z)}{q_\theta(z|x)} \, dz \\[0.8em]
&\stackrel{(3)}{=} \log \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \frac{p_\phi(x, z)}{q_\theta(z|x)} \right] \\[0.8em]
&\stackrel{(4)}{\geq} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log \frac{p_\phi(x, z)}{q_\theta(z|x)} \right] \\[0.8em]
&\stackrel{(5)}{=} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log \frac{p_\phi(x, z) p(z)}{q_\theta(z|x)p(z)} \right] \\[0.8em]
&\stackrel{(6)}{=} \mathbb{E}_{z \sim q_\theta(z|x) p(z)} \left[ \log \frac{p_{\phi}(x|z)p(z)}{q_\theta(z|x)} \right] \\[0.8em]
&\stackrel{(7)}{=} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log {p_{\phi}(x|z)} – \log { \frac{q_\theta(z|x)}{p(z)} } \right] \\[0.8em]
&\stackrel{(8)}{=} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log {p_{\phi}(x|z)} \right] – \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log { \frac{q_\theta(z|x)}{p(z)} } \right] \\[0.8em]
&\stackrel{(9)}{=} \mathbb{E}_{z \sim q_\theta(z|x)} \left[ \log {p_{\phi}(x|z)}] – \mathcal{D}_{\mathrm{KL}}(q_\theta(z|x)||p(z)) \right] \\[0.8em]
\end{aligned}
$$各步骤的说明:
- 步骤 (1) 为边缘概率公式
- 步骤(2) 分子、分母都乘以了 \(q_\theta(z|x) \)
- 步骤(3) 使用期望的形式改写上述公式(可以想一想连续形式的概率期望计算),这一步是为了转化为下一步可以使用 “Jensen” 不等式
- 步骤(4) 这里使用 “Jensen” 不等式,对于凹函数 \(\varphi \)有 \(\varphi(\mathbb{E}[X]) \geq \mathbb{E}[\varphi(X)] \) ,函数 \(f(x) = \log (x) \) 即为凹函数
- 步骤(5) 分子、分母都乘以 \(p(z) \)
- 步骤(6) 使用基础的条件概率公式 \(p_{\phi}(x|z)p(z) = p_{\phi}(x,z) \)
- 步骤(7) 使用对数函数基本性质 \(\log \frac{ab}{c} = \log {a} – \log \frac{c}{b} \)
- 步骤(8) 使用期望公式的线性特性 \(\mathbb{E}[X+Y] = \mathbb{E}[X] + \mathbb{E}[Y] \)
- 步骤(9) 使用了KL散度的定义,简单的说,即概率密度对数的差的期望即为散度
步骤(9) 也最终与前述的 \(\mathcal{L}_{\mathrm{ELBO}} \) 定义完全相同,故得证。
-

深度学习领域除了大语言模型之外,另一个极其活跃的领域即为视频、图像处理领域(或者叫“多模”数据)。随着 Stable Diffusion 取得成功,这个领域也在非常快速的发展。这里也打算极其粗浅的了解一下这个领域。打算,从最为基础“组件”之一 “CLIP” 开始。
“CLIP”的全称是“Contrastive Language–Image Pre-training”,描述的是一种训练方法,可以把“图片”、“文字”嵌入(Embedding)到同一个空间(例如 512 维的向量空间),并保持非常好的相关性。利用这个特点,则可以非常好的进行诸如:图片相似性、文本图片相关性的人物;也可以作为其他模型的一部分,提供非常好的文本与图片一致性的关系。这里以典型的“clip-vit-base-patch32”模型为例,去简单实践并了解该模型。
1. 实验设计
这里选择一张图片,如右图,使用该模型对图片进行 Embedding;然后再选择一组文本,如下,使用该模型对其进行 Embedding ,然后观察这些向量之间的余弦距离关系。
texts = [ "a dog", "a cat", "a car", "a landscape", "a person", "a person behind a statue", "a person riding a bicycle", "tourist attraction", "a vacation" ]
2. 实验数据与结果分析
在使用模型进行Embedding后,然后把所有文本向量与图片计算余弦相似度后有右侧数据:
可以看到,图片和文本之间表现出了非常强的相关度。相关度最高的文本为:“a person behind a statue”,也是所有文本中对图片最为准确的描述。“a person” 也比 “a person riding a bicycle” 有着更高的相似度,更比诸如 “a dog”、“a cat” 要高非常多。
0.2707 | a person behind a statue 0.2508 | tourist attraction 0.2074 | a person 0.2063 | a vacation 0.1974 | a person riding a bicycle 0.1875 | a dog 0.1821 | a landscape 0.1754 | a cat 0.1655 | a car2.1 可视化结果
这里在一个数轴上,简单对上述结果进行可视化,从而建立一个更为直观一点的认识:

在数轴上将上述文本与图片的相似度取值绘制出来,可以看到,“a person behind a statue”远比其他的文本相似度要高。
3. 其他
对于 Embedding 出来的向量,这里也使用诸如“T-SNE”、“PCA”、“UMAP”、“MDS”等方式去降维到二维空间分析,但是并没有观察余弦相似度的保持,与上述计算结果不符合。也许是点太少、也许是用法不对。这也让对诸如“T-SNE”等算法在可视化上效果,提高了警惕。关于这部分计算的数据和结果可以参考:SD-Forward-Diffusion-Process.ipynb@Colab,这里不再展示。
-
线性代数回顾
·

如果要理解大模型内部是如何工作的,良好的数学基础是必须的,而线性代数又是所有这些的基础。例如我们来看 \(\text{Attention} \) 机制中的如下问题。
目录
1. 为什么要重温线性代数
考虑第 \(j \) 个 \( \text{Layer} \) 中的第 \( i \) 个 \( \text{Head} \) ,则有如下的计算(为了简化,下述的角标省略了 \( \text{Layer} \) 部分):
$$
\begin{aligned}
Q_i &= XW_i^Q \\[0.3em]
K_i &= XW_i^K \\[0.3em]
\text{Therefore:} \\[0.3em]
\text{Attention Score}_i &= Q_iK_i^T \\[0.3em]
&= XW_i^Q(XW_i^K)^T \\[0.3em]
&= XW_i^Q\big((W_i^K)^T X^T\big) \\[0.3em]
&= XW_i^Q(W_i^K)^T X^T \\[0.3em]
&= X\big(W_i^Q (W_i^K)^T\big) X^T \\[0.3em]
\text{Let:} \quad \\[0.3em]
W_i^{QK} &= W_i^Q (W_i^K)^T \\[0.3em]
\text{Therefore:} \\[0.3em]
\text{Attention Score}_i &= XW_i^{QK} X^T \\[0.3em]
\end{aligned}
$$注:上述的推导使用矩阵的一些简单特性,包括转置计算、结合律等。其中,在开源的GPT2模型中,\(W_i^Q \,, W_i^K \) 都是 \(64 \times 768 \)的矩阵。
这里一个简单、又不太简单的问题是:那为什么每一个 \( \text{Head} \) 中不使用一个权重 \( W_i^{QK} \) 就可以了?这个问题从我第一次看明白 \( \text{Attention} \) 的计算后,困扰了我一会儿,直到重温了线性代数,才算是理解了上述的计算。
大学时学习线性代数学得非常痛苦,而现在带着问题再去看这本书,竟然花了两个晚上就看完了。这里对里面的基本概念和结论做个梳理,以更好的理解什么是“线性变换”、与矩阵的关系是什么、如何研究一个线性变换或矩阵的性质等。
本系列主要以介绍线性代数的“直觉”为主,不会做任何证明,为了更好的阐述“直觉”,甚至牺牲了很多的数学严谨,看客也需要从构建“直觉”与“联系”的角度阅读。本文的阅读前提是已经有一定的线性代数的基础、也对神经网络/LLM技术有一定了解,那么本文则尝试通过较小的篇幅去构建两者的联系,看看如何使用线性代数的技术去研究神经网络的中的问题。
2. 线性代数讨论的主要问题
通常“线性代数”课程会从 \(n\) 元一次线性方程组引入,并使用行列式理论,去较为彻底的回答如何解决 \(n\) 元一次线性方程组。更进一步的,为了更好/更完整的研究 \(n\) 元一次线性方程组的“解空间”,则需要引入一个新的研究对象:“向量空间”。而向量空间本身所具备的普遍性,已经远超出 \(n\) 元一次线性方程组本身。而后,“向量空间”、“线性变换”就变成了新的研究对象,因为现实问题中,我们经常会尝试通过“线性变换”来洞察向量空间中向量的关系。
是不是感觉上面描述漏了什么?是的,漏了“矩阵”。无论是讨论 \(n\) 元一次线性方程组还是“向量空间”或“线性变换”,矩阵都是“核心”工具。这个工具“核心”或者说重要到什么程度呢?甚至很多问题,只需要研究清楚对应“矩阵”的特性,原来的问题就研究清楚了。所以,你会注意到,线性代数的书中,几乎全都在介绍“矩阵”的各种特性。
而各种 \( \text{Embedding} \) 就可以理解为是在最为典型的欧氏空间中的向量。
3. \(n \) 元一次方程组的解
线性代数通常都会以解“\( n \)元一次方程组”为切入点,这个问题看似很简单,但是最终要完全讨论清楚,则需要很多篇幅。这也是“线性代数”前半部分比较枯燥的原因。整体上来看,关于“\( n \)元一次方程组”的解需要讨论清楚几个问题:
- (a) \( n \)元一次方程组的解是否存在?
- (b) 如果存在,如何求解
- (c) 如果解不存在,充要条件是什么
- (d) 如果有解,那么所有的解如何表达
在探讨上述问题的时候,先是引入了“行列式”、“矩阵”的概念与理论,并通过矩阵的“初等变换”实现对上述问题的求解。这里涉及到的概念延伸出了:
- (a) 矩阵的初等变换
- (b) 矩阵的秩等
这里我们列举一些主要的结论(并不做推倒,推倒过程还是非常复杂的,这也正是线性代数书比较枯燥的原因之一)。这里考虑如下的线性方程组:
$$
a_{11}x_1 + a_{12}x_2 + \cdots + a_{1n}x_n = b_1, \\
a_{21}x_1 + a_{22}x_2 + \cdots + a_{2n}x_n = b_2, \\
\quad\vdots \\
a_{m1}x_1 + a_{m2}x_2 + \cdots + a_{mn}x_n = b_m.
$$结论: 线性方程组有解的充分必要条件是:它的系数矩阵与增广矩阵有相同的秩。
结论: 线性方程组系数矩阵和增广矩阵的秩都是\( r \),方程组的未知数的个数是\( n \),如果:
- \( r = n \) 则线性方程组有唯一解
- \( r < n \) 则线性方程组有无穷组解
上述两个定理较为彻底的回答了解存在性的问题。那么,解的公式化表达是怎样的呢?为了略微简化问题,这里考虑仅考虑\( n \)个方程、\( n \)个未知数,且解唯一的情况:
$$
\begin{cases}
a_{11}x_1 + a_{12}x_2 + \cdots + a_{1n}x_n = b_1, \\
a_{21}x_1 + a_{22}x_2 + \cdots + a_{2n}x_n = b_2, \\
\quad\vdots \\
a_{n1}x_1 + a_{n2}x_2 + \cdots + a_{nn}x_n = b_n
\end{cases}
\quad\Longleftrightarrow\quad
\begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\begin{bmatrix}
x_1 \\ x_2 \\ \vdots \\ x_n
\end{bmatrix}
=
\begin{bmatrix}
b_1 \\ b_2 \\ \vdots \\ b_n
\end{bmatrix}
$$形式化的解,则可以由两种方式给出:
使用矩阵的表达:
$$
\vec{x} = A^{-1}\vec{b}
$$“克莱默法则”(Cramer’s rule / formula):
$$
x_1 = \frac{D_1}{D},x_2 = \frac{D_2}{D},\dots , x_n = \frac{D_n}{D},
$$注意:上述的两种表达,无论哪种,限制条件都非常苛刻,即要求:矩阵\( A \)可逆或者行列列式\(D \neq 0\),当然,这两个条件式等价的。并且,这里的\(D\)也经常写作:\( det(A) \)。
4. 矩阵基础与部分结论
虽然是为了求解线性方程组才引入矩阵的,但很快就会意识到,对矩阵本身特性的研究有着更为广泛的应用。
首先,在定义了矩阵的运算之后,很快就会有一些矩阵的运算律。例如,加法的结合律、交换律、分配律等。这里,矩阵的乘法是重点,且略微复杂一些:
- 首先,首先矩阵的乘法是不满足交换律的
- 很幸运,结合律和分配律都是满足的
- 再次,对于转置运算,是满足如下形式的:\( (AB)^T = B^TA^T \)
结论: 线性方程组的初等变换,对应着三个初等变换矩阵:\( P_{ij} \)、\( D_i(k) \)、\( T_{ij}(k) \),且这三个初等变换矩阵都是可逆的。
结论: 一个\( m \times n\)的矩阵\( A \)总是可以通过初等变换化为以下形式的矩阵:
$$ \bar{A} = \begin{bmatrix}
I_r & O_{r,\,n-r} \\
O_{m-r,\,r} & O_{m-r,\,n-r}
\end{bmatrix} $$这里,\(I_r\)是\( r \)阶单位矩阵,\(O_{st}\)表示\( s\times t\)的零矩阵,\( r \)等于矩阵\(A\)的秩。
结论:\(n \) 阶矩阵\( A \)可逆,当且仅当\( A \)的秩等于\( n \)。
如何求解矩阵的逆:有了这些结论,那么对于一个可逆矩阵要求其逆矩阵,则可以有些办法:即对一个矩阵实施一系列的初等变换,将其变为单位矩阵。而同时,在开始的时候,就将所有的这些初等变换作用在一个单位矩阵上。最后,当原矩阵变为单位矩阵的时候,后面的单位矩阵就变成原矩阵的逆了。
结论: 两个矩阵乘积的秩,不大于任何一个矩阵的秩。特别的,如果有一个矩阵是可逆的,则乘积的秩则等于另一个矩阵的秩。
结论: 一个矩阵的行空间的维数等于列空间的维数,等于这个矩阵的秩。
5. 向量空间
到目前为止,前面的线性方程组的解,还有一些问题没有彻底回答(例如,解空间的描述),在回答这个问题之前,我们需要先了解一下“向量空间”。“向量空间”的严格定义是有些枯燥的,这里暂时把“向量空间”的限制为大家所熟悉的、最为典型的“ \(n \) 维欧氏空间”。
5.1 基
要描述一个向量空间中的元素,则首先需要一组基(坐标)。在\(n\)维欧氏空间,最为常见的一组基,即为多个“垂直”(“正交”)的单位向量,即:
$$ \begin{align}
\alpha_1 &= (1,0,\dots) \\
& \vdots \\
\alpha_i &= (\dots,0,1,0,\dots) \\
& \vdots \\
\alpha_n &= (0,\dots,1)
\end{align}
$$在二维平面空间中,则为:\( \alpha_1 = (1,0) \quad \alpha_2 = (0,1)\);三维空间则为:\( \alpha_1 = (1,0,0) \quad \alpha_2 = (0,1,0) \quad \alpha_3 = (0,0,1)\)。
既然有“正交”基,那么当然有不那么“正交”的基,而此类“基”则是更为普遍的。事实上,更为普遍的,任何 \( n \) 个线性无关的向量都可以作为向量空间的基。
5.2 线性相关与线性无关
考虑一组向量\( \alpha_1,\dots , \alpha_n \),如果当且仅当所有\( a_i = 0 \quad i=1,\dots,n\)时如下的等式才成立:
$$ a_1\alpha_1 + a_2\alpha_2 + \dots + a_n\alpha_n = 0 $$
那么,就说 这组向量 \( \alpha_1,\dots , \alpha_n \) 是线性无关的。反之,则称这组向量是线性相关的。
或者这么说,对于一组线性无关的向量\( \alpha_1,\dots , \alpha_n \):任何一个向量都不能用剩余的向量做“线性表示”。
5.3 一些重要的结论
结论:设\( \{ \alpha_1,\dots , \alpha_n \}\)是向量空间\( V \)的一组基,那么\( V \)空间中的每一个向量都可以唯一的表示为这组基的线性组合。这个线性组合的系数,就叫“坐标”(注:相对于这组基)。
结论:\( W_1 \)、\( W_2 \)是\( V \)的有限子空间,那么有:
$$ dim(W_1+W_2) = dim(W_1) + dim(W_2) – dim(W_1\cap W_2) $$
结论:\( n \)维向量空间中,任意\( n \)个线性无关的向量都可以取做基。
6. 线性变换与矩阵
6.1 概述
“线性变换”是指向量空间中一类特殊的映射 \( \sigma : R^n \to R^m \) ,需要满足条件是:
- \( \sigma(\xi + \eta) = \sigma(\xi) + \sigma(\eta) \)
- \( \sigma(a\xi) = a\sigma(\xi) \)
“线性变换” 描述了向量空间之间的映射。后续所有的内容大概都是围绕此而展开,后续所有的内容都会尝试通过各种方式将 “线性变换” 的特性研究清楚。这里写出部分结论,后面再慢慢展开:
- 线性变换之下,原点保持不变。即 \( \sigma( \vec{0} ) = \vec{0} \)
- 几何意义下,通常,线性变换包括了:旋转、镜像、拉伸/压缩(特别的,有时候会压缩到零)、剪切
为了研究清楚一个线性变换上述的特点,通常需要选取一组“基”,然后使用这组“基”的“坐标”来描述空间中的点,进而再描述对应的线性变换。最为常见的基为“正交单位基”。
从方法上来看,研究清楚“线性变换”最为关键的是研究清楚对应的“变换矩阵”。所以,“线性代数”的核心后面就变成了对矩阵特性的研究,但是,也不要忘记了初衷,否则很快就迷失了。
6.2 线性变换
我在大学期间对于线性变换、矩阵有什么作用,是完全没有概念的。所以对于他们的特性研究也没有掌握的很深,基本上是停留在能够把一些联系题做对这个层面。而现在,注意线性变换的广泛应用之后,尝试去理解去本质之后,就会寻根问底的去理解清楚什么是线性变换、什么是矩阵。这里再次说说我的理解。
在一个向量空间中,最为常见的是 \(n \) 维欧氏空间,会有很多的向量,例如每个 Embedding 就可以理解是在一个线性空间中,“线性变换”表述了是空间中的一类映射,该映射满足上述“小结2.1”中的两个要求,即原点依旧到原点、映射保持所谓的“线性”(例如,向量和的映射等于映射的和等)。
在一个向量空间中,一个线性变换就是一个符合一定条件的映射。与向量空间的基的选取是没有关系的。自此,与矩阵也是没有关系的。所以,线性变换本身是更为底层、更为基础的概念。
6.3 欧氏空间的线性变换与矩阵
现在我们把问题限定在 \(n \) 维欧氏空间中。那么,这时候,我们如何描述一个线性变换呢?是的,就是“基”与“矩阵”。
通常,\(n \) 维欧氏空间,我们会先选取一组基,然后使用一个矩阵去描述这个线性变换。并且非常幸运的,一旦这组基 选定了,这个矩阵是唯一的。
结论:在\(n \) 维欧氏空间(这个条件似乎可以去掉)中,对于线性变换 \(\sigma \),如果选定一组“基”,那么就存在唯一的“矩阵”描述该线性变换。
上述的结论,是比较明显的。我们考虑对于线性变换中的上述选定的基向量 \(\alpha_i,\quad \text{where } i = 1,\ldots,n \),线性变换将其映射到 \(\beta_i,\quad \text{where } i = 1,\ldots,n \),那么根据“基”的基本性质,对于这里的任何 \(\beta_i \)都可以表示成\(\alpha_i \)的线性组合,所有的这些系数构成的矩阵,就是上述描述的唯一的“矩阵”。具体的:
$$
\begin{aligned}
\beta_1 &= a_{11}\alpha_1 + a_{21}\alpha_2 + \cdots + a_{n1}\alpha_n \\[0.5em]
\beta_2 &= a_{12}\alpha_1 + a_{22}\alpha_2 + \cdots + a_{n2}\alpha_n \\[0.5em]
&\ \vdots \\[0.5em]
\beta_n &= a_{1n}\alpha_1 + a_{2n}\alpha_2 + \cdots + a_{nn}\alpha_n
\end{aligned}
$$即:
$$
\begin{aligned}
\begin{bmatrix}
\beta_1 & \beta_2 & \cdots & \beta_n
\end{bmatrix}
=
\begin{bmatrix}
\alpha_1 & \alpha_2 & \cdots & \alpha_n
\end{bmatrix}
\begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\end{aligned}
$$即在这个线性变换\(\sigma \) 在选定基 \(\alpha_i,\quad \text{where } i = 1,\ldots,n \) 对应的矩阵为:
$$
\begin{aligned}
A =
\begin{bmatrix}
a_{11} & a_{12} & \cdots & a_{1n} \\
a_{21} & a_{22} & \cdots & a_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
a_{n1} & a_{n2} & \cdots & a_{nn}
\end{bmatrix}
\end{aligned}
$$从这段简洁的“证明”(或“说明”)来看,我们很自然有如下结论,根据空间中的“基”的选取不同,我们会得到不同的矩阵。因为我们反复会提到,我们经常会通过研究矩阵的特性来研究线性变换。那么,同一个线性变换在不同的“基”下的不同“矩阵”,很自然的能够想到,这些“矩阵”是有某些共性的,是的,我们称这些矩阵为“相似矩阵”,相关特性,暂不展开。
7. 特征向量与特征值
7.1 为什么
为什么我们需要关注“特征值与特征向量”呢?为什么我们要去了解奇异值分解(SVD)呢?
原因是“线性变换”是一个映射,是非常抽象的。而特征值 、特征向量、SVD分解可以把线性变换最为关键的特性,以非常“直观”的形式表达出来。当然,这里的“直观”并不是简单意义上能够一眼就看出什么来,事实上,“线性变换”本身就有很强的抽象性,这里的“直观”只是相对的,是否直观,完全依赖于各位看客自己的“悟性”了 。
特征向量的基本定义:如果有 \( \sigma(\xi) = \lambda \xi \) ,那么这里的 \( \xi \) 就是特征向量,对应的 \(\lambda \) 就是对应的特征值。
要想真正说清楚特征向量与特征值是需要非常多篇幅的,而且关于对特征向量的理解对于理解线性变化也是非常关键的,所以,建议花些时间较为系统的做一些理解。如果你已经建立的基础概念,这里的一篇文章可能是帮助你增强一些理解:特征向量与特征值。
7.2 关于对特征向量的理解
完整的讨论特征向量与特征值是复杂的,这里将其限定在一些较为简单的情况,作为一个入门。我们这里考虑最为简单的情况,即对于一个 \(n \times n \)的矩阵,其秩为 \(n \),并且在计算特征值时,有 \(n \) 是不重复的实数解,即没有任何根式重根。如果,恰好 \( n = 2 \)这大概是最为简单的情况了,不过理解这种情况,再进一步拓展,则学习曲线会平滑很多。
我们来看一个实例,在二维空间中,在标准基下,我们有如下的线性变换矩阵:
$$
W = \begin{bmatrix}
2 & 1 \\
1 & 2
\end{bmatrix}
$$根据上述特征向量特征值的定义进行求解,我们可以有如下的特征值与特征向量:
- \( \lambda_1 = 3 \) 特征向量 \( (1,1) \)
- \( \lambda_2 = 1 \) 特性向量 \( (-1,1) \)
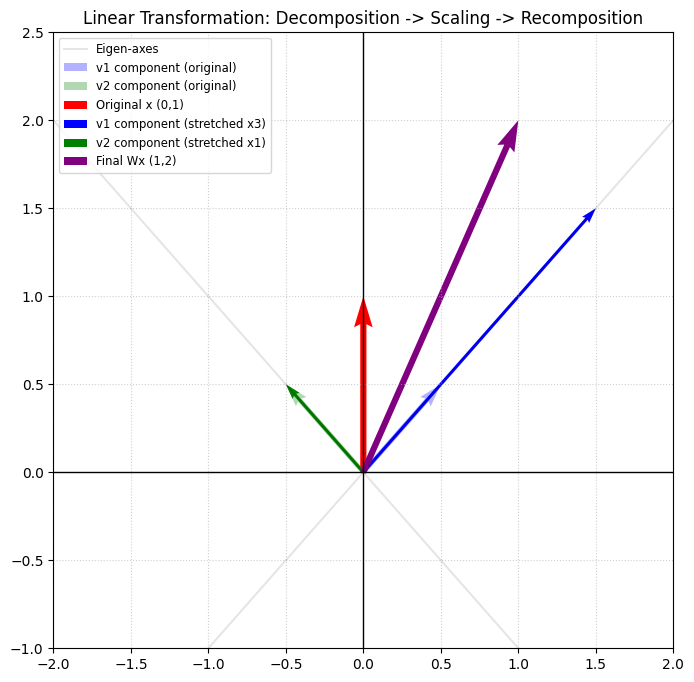
从特征向量角度理解线性变换:那么上述的矩阵A对应的线性变换 \(\sigma \) 有如下特性,在这个二维空间任何向量 \(\beta \),都可以分解(投影)为上述两个特征向量方向的向量: \(\beta_1 \,, \beta_2 \),且有:\(\beta = \beta_1 + \beta_2 \)。那么,则有:\(\sigma(\beta) = \lambda_1 \beta_1 + \lambda_2 \beta_2 \)。即,这个线性变换可以这样描述:先将任何向量沿着特征向量方向分解,然后再按照特征值的大小进行拉伸或压缩,然后再把向量合并起来。
上述的解释,可以对照着右图去理解。特征向量分别为 \((1,1) \) 和 \((-1,1) \) ,即图中浅绿色、浅蓝色方向。该矩阵作用在向量 \((0,1) \) 上,即图中的红色向量。先将红色向量沿着浅绿色、浅蓝色方向分解,然后按照特征值进行拉伸,即图中的绿色、蓝色向量,最后合并为图中的紫色最终向量。
上述的场景是线性变换中,最为简单的一类。而实际的线性变换,则更为复杂,可能还涉及到对于向量的旋转、镜像、剪切等变换。关于更多场景可以自己探索,或者阅读相关书籍,也可以看看这篇文章中的更多直观的例子:特征值与特征向量。
“特征向量”可以很好的帮助理解“方阵”变换,还有一类变换时非方阵的情况,通常这时候可以借助于奇异值分解的方式去理解,关于奇异值分解可以参考:奇异值分解–深度学习的数学基础。
8. 一些补充说明
初等的线性代数核心部分大概是这些内容,出于完整性的考虑,可以再进一步了解“Jordan 块”相关的内容,从而把相关理论补充完整,这里不再详述。
如果再回到最初的线性方程组解的问题,我们这里就可以回答最后一个问题:对于一个线性方程组,如果有解,那么所有的解空间是怎样的?
结论:如果方程组的系数矩阵的秩为\( r \),那么解空间的维度为\( n-r \)。解空间的“基”则可以通过初等变换求得。这里不再详述。
9. 再看看前面的问题
$$
\begin{aligned}
\text{Attention Score}_i = XW_i^{QK} X^T \quad \text{where} \,,W_i^{QK} = W_i^Q (W_i^K)^T
\end{aligned}\tag{1}
$$$$
\text{Attention Score}_i = Q_iK_i^T = XW_i^Q(XW_i^K)^T \tag{2}
$$在上面的计算(1) 和 计算(2),那么在模型中训练 \(W_i^{QK} \) 和 在模型中训练单独训练 \(W_i^Q \,,W_i^K \) 是否是等价的?
答案是否定的。
这里以 GTP2 模型为例,原因在于如果单独训练 \(W_i^{QK} \) ,那么这个矩阵的秩,则很可能是 768 ;而单独训练 \(W_i^Q \,,W_i^K \),这两个矩阵的秩则一定小于 64,这两个矩阵的乘积的秩也一定是 64 (严格来说是小于等于)。所以最终训练获得的效果一定是不同的。当然,哪个更好,这倒不一定,但他们并不是等价的。
一般意义来说,使用 \(W_i^{QK} \) 可能有着更强的表达能力,只是意义没有那么明确,并且训练的参数要更多。
-

大语言模型的一个重要方向是“推理”优化,即如何在有限的硬件环境中提升推理的效率。对于所有的 MaaS 服务提供方,这都是至关重要的。一方面关乎用户的使用体验(诸如TTFT,time to first token)、另一方面关于服务提供的成本(有限的GPU如何提供更高的吞吐量)。
1. 概述
从 Transformer 架构的 Decoder 阶段原理来看,一个常见的、自然的优化就是使用“KV Cache”大大减少推理(自回归阶段)过程需要计算量,实现以显存换效率,从而加速推理过程。
2. Decoder 模型的自回归计算
在了解了“Attention”、“mask attention”、“autoregression”计算之后,比较自然可以注意到在 Q、K、V 矩阵在“autoregression”的过程中,有很多的部分是无需额外计算的。
这里依旧继续使用《理解大语言模型的核心:Attention》中的示例,这里考虑在文章中的提示词“It’s very hot in summer. Swimming is”,生成新的Token为 “ a”,那么我们看看这个自回归过程某个Head中的计算。完成的代码可以参考:autoregression-of-attention.ipynb。
相比与在 prefill 阶段,需要额外计算的,在后续使用黄色标识出来。
2. 1 Token Embedding 和 Positional Embedding
Token Embedding
+
Positional Embedding
----------------------------------------------------------------------------------------------------------------------------------
| Token | Token ID | Token Embeddings(first 3 of 768 ) | Positional Embeddings | Token Embedding + Positional |
----------------------------------------------------------------------------------------------------------------------------------
| It | 1026 | [ 0.0390, -0.0869, 0.0662, ...] | [ -0.0188, -0.1974, 0.0040, ...] | [ 0.0202, -0.2844, 0.0702, ...] |
| âĢ | 447 | [ -0.0750, 0.0948, -0.0034, ...] | [ 0.0240, -0.0538, -0.0949, ...] | [ -0.0510, 0.0410, -0.0982, ...] |
| Ļ | 247 | [ -0.0223, 0.0182, 0.2631, ...] | [ 0.0042, -0.0848, 0.0545, ...] | [ -0.0181, -0.0666, 0.3176, ...] |
| s | 82 | [ -0.0640, -0.0469, 0.2061, ...] | [ -0.0003, -0.0738, 0.1055, ...] | [ -0.0643, -0.1207, 0.3116, ...] |
| Ġvery | 845 | [ -0.0553, -0.0348, 0.0606, ...] | [ 0.0076, -0.0251, 0.1270, ...] | [ -0.0477, -0.0599, 0.1876, ...] |
| Ġhot | 3024 | [ 0.0399, -0.0053, 0.0742, ...] | [ 0.0096, -0.0339, 0.1312, ...] | [ 0.0495, -0.0392, 0.2054, ...] |
| Ġin | 287 | [ -0.0337, 0.0108, 0.0293, ...] | [ 0.0027, -0.0205, 0.1196, ...] | [ -0.0310, -0.0098, 0.1490, ...] |
| Ġsummer | 3931 | [ 0.0422, 0.0138, -0.0213, ...] | [ 0.0025, -0.0032, 0.1174, ...] | [ 0.0448, 0.0106, 0.0961, ...] |
| . | 13 | [ 0.0466, -0.0113, 0.0283, ...] | [ -0.0012, -0.0018, 0.1110, ...] | [ 0.0454, -0.0131, 0.1394, ...] |
| ĠSw | 2451 | [ 0.0617, 0.0373, 0.1018, ...] | [ 0.0049, 0.0021, 0.1178, ...] | [ 0.0666, 0.0395, 0.2196, ...] |
| imming | 27428 | [ -0.1385, -0.1774, -0.0181, ...] | [ 0.0016, 0.0062, 0.1004, ...] | [ -0.1369, -0.1711, 0.0823, ...] |
| Ġis | 318 | [ -0.0097, 0.0101, 0.0556, ...] | [ -0.0036, 0.0175, 0.1068, ...] | [ -0.0133, 0.0275, 0.1623, ...] |
| Ġa | 257 | [ -0.0506, 0.0056, 0.0471, ...] | [ 0.0001, 0.0172, 0.0969, ...] | [ -0.0506, 0.0228, 0.1440, ...] |
----------------------------------------------------------------------------------------------------------------------------------这里,只需要计算最新的Token(即这里的“ a”)的Embedding即可。事实上,上面矩阵白色部分再自回归阶段完全不再需要使用了。所以,上述内容计算完成后,内存即可释放,无需缓存。
2. 2 Normalize
即,将每一个token的embedding 进行正规化,将其均值变为0,方差变为1
------------------------------------------------------
| Token | Token ID | Normalized(first 3 of 768 ) |
------------------------------------------------------
| It | 1026 | [ 0.0129 , -0.1104 , -0.0317] |
| âĢ | 447 | [-0.0530 , 0.0588 , -0.1290] |
| Ļ | 247 | [-0.0170 , -0.0242 , 0.1639] |
| s | 82 | [-0.0754 , -0.0842 , 0.1842] |
| Ġvery | 845 | [-0.0566 , -0.0280 , 0.0953] |
| Ġhot | 3024 | [ 0.0587 , -0.0086 , 0.1073] |
| Ġin | 287 | [-0.0391 , 0.0209 , 0.0731] |
| Ġsummer | 3931 | [ 0.0532 , 0.0397 , 0.0181] |
| . | 13 | [ 0.0553 , 0.0152 , 0.0579] |
| ĠSw | 2451 | [ 0.0807 , 0.0691 , 0.1216] |
| imming | 27428 | [-0.1528 , -0.1249 , -0.0017] |
| Ġis | 318 | [-0.0175 , 0.0605 , 0.0880] |
| Ġa | 257 | [-0.0688 , 0.0540 , 0.0697] |
------------------------------------------------------与前面类似,这里计算完成并推进到下一步后,内存即可释放,无需缓存。
2. 3 Attention 层的参数矩阵
\(W^Q\,,W^K\,,W^V \)
W^Q [:3] shape (768 x 64) W^K [:3] shape (768 x 64) W^V [:3] shape (768 x 64)
------------------------------------- -------------------------------- --------------------------------
[-0.4738, -0.2614, -0.0978, ...] | [ 0.3660, 0.0771, 0.2226, ...] [ 0.1421, 0.0329, -0.0667, ...]
[ 0.0874, 0.1473, 0.2387, ...] | [-0.4380, -0.1446, -0.4717, ...] [ 0.0162, -0.0633, -0.0636, ...]
[ 0.0039, 0.0695, 0.3668, ...] | [ 0.1237, 0.0174, 0.1181, ...] [ 0.0229, -0.0828, 0.0437, ...]
[ 0.2215, -0.1884, -0.0141, ...] 64 [-0.2247, 0.0148, -0.1859, ...] [-0.0106, 0.0070, 0.0565, ...]
[-0.0947, 0.1678, -0.0143, ...] rows [-0.2001, -0.1052, -0.1743, ...] [ 0.0416, 0.0938, -0.1792, ...]
... | ... ...
[-0.4100, -0.1924, -0.2400, ...] | [,0.1567, 0.2664, 0.1851, ...] [-0.0341, 0.0034, 0.0203, ...]
------------------------------------- -------------------------------- --------------------------------
|<------- columns: 768 ------->| |<------- columns: 768 ------->| |<------- columns: 768 ------->|这是三个权重矩阵,总是需要常驻内存的,并且可以被多个“推理”共享使用。
2. 4 矩阵 Q K V的计算
\(Q = XW^Q \)
\(K = XW^K \)
\(V = XW^V \)
Q [:3] shape (12 x 64) K [:3] shape (12 x 64) V [:3] shape (12 x 64)
------------------------------------- --------------------------------- --------------------------------
[ 0.4207, -0.9178, 0.1760, ...] | [ -1.4202, 1.6791, 0.9837, ...] [ 0.0452, 0.0628, 0.1463, ...]
[ 0.7757, 0.2485, 0.7349, ...] | [ -2.5320, 2.2932, 1.5592, ...] [-0.1361, 0.1379, 0.0150, ...]
[ 0.4481, 0.0206, -0.0825, ...] | [ -2.2571, 2.7764, 1.8401, ...] [ 0.0039, -0.1295, -0.0311, ...]
[ 0.9500, 0.1481, 0.3469, ...] 12 [ -2.4322, 3.1454, 2.0600, ...] [-0.0391, 0.0581, 0.0511, ...]
[ 0.4989, -0.4376, 0.1678, ...] rows [ -3.5428, 2.1485, 2.0414, ...] [ 0.0963, 0.3563, -0.1477, ...]
... | ... ...
[ 0.4429, -1.1997, 0.5611, ...] | [ -2.2559, 2.0384, 2.2542, ...] [ 0.2759, -0.2783, 0.3240, ...]
[ 0.4989, -0.4376, 0.1678, ...] | [ -2.6703, 2.3629, 1.7493, ...] [ -0.0633, 0.0431, -0.0422, ...]
------------------------------------- --------------------------------- --------------------------------
|<------- columns: 64 ------->| |<------- columns: 64 ------->| |<------- columns: 64 ------->|计算 Q、K、V 矩阵,这里只有最后一行(即对应最后一个Token “ a”)。这里的矩阵 K 、V 需要进行缓存,在后续每一次自回归的过程都需要完整的使用 K V 矩阵中所有值,下一步会说明原因。Q 矩阵在完成后矩阵计算,就可以释放。
2. 5 计算 Attention Score
\(\text{Attention Score} \)
\(= \frac{QK^T}{\sqrt{d}} \)
|-----------------------------------------------------------------------------------------------------|
| | Attention Score Matrix shape (13 x 13) |
| Token |---------------------------------------------------------------------------------------------|
| | It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis Ġa |
|-------|---------------------------------------------------------------------------------------------|----
|It | [ 0.14, -1.53, -1.45, -1.71, -1.69, -1.74, -2.36, -2.27, -2.37, -1.33, -0.58, -2.40, / ]| |
|âĢ | [ 0.70, -0.93, -1.72, -1.02, -1.52, -2.24, -1.90, -2.19, -1.63, -2.13, -1.66, -2.14, / ]| |
|Ļ | [-0.60, -1.81, -1.99, -1.96, -2.57, -1.84, -1.62, -2.04, -0.98, -1.18, -2.23, -2.25, / ]| |
|s | [-0.46, -1.33, -1.60, -2.65, -2.24, -1.99, -2.89, -1.44, -2.05, -2.77, -2.09, -2.74, / ]| |
|Ġvery | [ 0.29, -1.42, -1.77, -1.15, -0.94, -1.14, -1.81, -1.04, -1.77, -2.13, -0.60, -0.82, / ]| |
|Ġhot | [ 0.03, -0.68, -0.59, -0.95, -1.78, -0.10, -0.95, -0.14, -1.32, -0.57, 0.06, -1.07, / ]| 13
|Ġin | [-0.71, -1.72, -1.53, -2.18, -1.67, -1.93, -3.41, -1.69, -2.74, -1.89, -1.17, -2.02, / ]| rows
|Ġsummer| [-0.34, -1.49, -1.35, -1.31, -1.12, -0.89, -1.49, -1.11, -1.51, -1.15, -1.45, -1.20, / ]| |
|. | [-0.89, -1.73, -2.67, -2.80, -2.45, -2.37, -4.39, -2.33, -4.42, -2.73, -1.82, -3.21, / ]| |
|ĠSw | [-0.05, -1.15, -1.76, -1.15, -1.68, -0.74, -1.15, -1.35, -1.36, -1.29, -0.43, -1.51, / ]| |
|imming | [-0.02, -1.65, -0.87, -0.35, -1.18, -0.65, -0.33, -1.25, -0.38, -1.68, -2.15, -1.08, / ]| |
|Ġis | [-0.97, -2.03, -2.56, -2.94, -1.96, -2.71, -4.07, -2.46, -3.51, -2.68, -1.88, -2.99, / ]| |
|Ġa | [-1.10, -1.95, -2.12, -3.12, -2.72, -2.17, -3.88, -2.06, -3.57, -2.49, -1.86, -2.83, -3.40 ]| |
|-------|---------------------------------------------------------------------------------------------|----
|<------------------------------------ columns: 13 ------------------------------------------>|特别需要注意的,这一步中,“Attention Score Matrix”最后一行的计算,需要前面的Q的最后一行,此外还需要整个 K 矩阵。这就是为什么 K 矩阵是需要缓存的。
2. 6 计算 Masked Attention Score
\(\text{Masked Attention Score} \)
\(= \frac{QK^T}{\sqrt{d}} + \text{mask} \)
|-----------------------------------------------------------------------------------------------------|
| | Attention Score Matrix shape (13 x 13) |
| Token |---------------------------------------------------------------------------------------------|
| | It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis Ġa |
|-------|---------------------------------------------------------------------------------------------|----
|It | [ 0.14, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf ]| |
|âĢ | [ 0.70, -0.93, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf ]| |
|Ļ | [-0.60, -1.81, -1.99, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf ]| |
|s | [-0.46, -1.33, -1.60, -2.65, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf ]| |
|Ġvery | [ 0.29, -1.42, -1.77, -1.15, -0.94, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf ]| |
|Ġhot | [ 0.03, -0.68, -0.59, -0.95, -1.78, -0.10, -inf, -inf, -inf, -inf, -inf, -inf, -inf ]| 13
|Ġin | [-0.71, -1.72, -1.53, -2.18, -1.67, -1.93, -3.41, -inf, -inf, -inf, -inf, -inf, -inf ]| rows
|Ġsummer| [-0.34, -1.49, -1.35, -1.31, -1.12, -0.89, -1.49, -1.11, -inf, -inf, -inf, -inf, -inf ]| |
|. | [-0.89, -1.73, -2.67, -2.80, -2.45, -2.37, -4.39, -2.33, -4.42, -inf, -inf, -inf, -inf ]| |
|ĠSw | [-0.05, -1.15, -1.76, -1.15, -1.68, -0.74, -1.15, -1.35, -1.36, -1.29, -inf, -inf, -inf ]| |
|imming | [-0.02, -1.65, -0.87, -0.35, -1.18, -0.65, -0.33, -1.25, -0.38, -1.68, -2.15, -inf, -inf ]| |
|Ġis | [-0.97, -2.03, -2.56, -2.94, -1.96, -2.71, -4.07, -2.46, -3.51, -2.68, -1.88, -2.99, -inf ]| |
|Ġa | [-1.10, -1.95, -2.12, -3.12, -2.72, -2.17, -3.88, -2.06, -3.57, -2.49, -1.86, -2.83, -3.40 ]| |
|-------|---------------------------------------------------------------------------------------------|----
|<------------------------------------ columns: 13 ------------------------------------------>|2.7 计算 Softmax Masked Attention Score
\(\text{Softmax Masked Attention Score} \)
\(= \text{softmax}(\frac{QK^T}{\sqrt{d}} + \text{mask}) \)
|---------------------------------------------------------------------------------------|
| | Softmax Masked Attention Score Matrix shape (13 x 13) |
| Token |-------------------------------------------------------------------------------|
| | It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis |
|-------|-------------------------------------------------------------------------------|----
|It | [1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| |
|âĢ | [0.84 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| | V [:3] shape (12 x 64)
|Ļ | [0.65 0.19 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| | --------------------------------
|s | [0.54 0.23 0.17 0.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| | [ 0.0452, 0.0628, 0.1463, ...]
|Ġvery | [0.54 0.10 0.07 0.13 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| | [-0.1361, 0.1379, 0.0150, ...]
|Ġhot | [0.29 0.14 0.16 0.11 0.05 0.25 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| 13 [ 0.0039, -0.1295, -0.0311, ...]
|Ġin | [0.36 0.13 0.16 0.08 0.14 0.11 0.02 0.00 0.00 0.00 0.00 0.00 0.00]| rows [-0.0391, 0.0581, 0.0511, ...]
|Ġsummer| [0.26 0.08 0.09 0.10 0.12 0.15 0.08 0.12 0.00 0.00 0.00 0.00 0.00]| | [ 0.0963, 0.3563, -0.1477, ...]
|. | [0.40 0.17 0.07 0.06 0.08 0.09 0.01 0.10 0.01 0.00 0.00 0.00 0.00]| | ...
|ĠSw | [0.27 0.09 0.05 0.09 0.05 0.14 0.09 0.07 0.07 0.08 0.00 0.00 0.00]| | [ 0.2759, -0.2783, 0.3240, ...]
|imming | [0.19 0.04 0.08 0.14 0.06 0.10 0.14 0.06 0.13 0.04 0.02 0.00 0.00]| | [-0.0633, 0.0431, -0.0422, ...]
|Ġis | [0.30 0.10 0.06 0.04 0.11 0.05 0.01 0.07 0.02 0.05 0.12 0.04 0.00]| | --------------------------------
|Ġa | [0.25 0.11 0.09 0.03 0.05 0.09 0.02 0.10 0.02 0.06 0.12 0.04 0.03]| | |<------- columns: 64 ------->|
|-------|-------------------------------------------------------------------------------|----
|<---------------------------------- columns: 13 ------------------------------>|2. 8 计算 Contextual Embeddings
\(\text{Contextual Embeddings} \)
\(= \text{softmax}(\frac{QK^T}{\sqrt{d}} + \text{mask})V \)
Token | Contextual Embedding (12 x 768)
--------------------------------------------
It | [ 0.0452, 0.0628, 0.1463,...]
âĢ | [ 0.0153, 0.0752, 0.1247,...]
Ļ | [ 0.0034, 0.0464, 0.0923,...]
s | [-0.0082, 0.0464, 0.0801,...]
Ġvery | [ 0.0218, 0.1029, 0.0621,...]
Ġhot | [ 0.0327, 0.0892, 0.0409,...]
Ġin | [ 0.0249, 0.0964, 0.0329,...]
Ġsummer | [ 0.0583, 0.1195, 0.0068,...]
. | [ 0.0334, 0.1100, 0.0366,...]
ĠSw | [ 0.0086, 0.0846, 0.0074,...]
imming | [-0.0049, 0.0841, -0.0339,...]
Ġis | [ 0.0410, 0.0706, 0.0077,...]
Ġa | [ 0.0427 , 0.0503 , 0.0080,...]所以,这一步中,“Contextual Embeddings”最后一行的计算,需要前面 Softmax Masked Attention Score Matrix 的最后一行,此外还需要整个 V 矩阵。这就是为什么 V 矩阵是需要缓存的。
此外可以看到,在这个自回归的计算中,Q 矩阵前面的所有行(即上一轮计算的Q矩阵)都用不上,这也是为什么 Q 矩阵不需要缓存,即我们需要的“KV Cache”,而不是“QKV Cache”的原因。
3. 计算图示
这里依据使用了图示的方式展示了在“自回归”过程中的数学计算。在下图中,第一个生成的 Token 为“ a”,该 Token 在进入 Decoder 模型再次进行计算时(即“自回归”),下图中:
- 粉红色背景部分为新的、需要计算的部分;
- 灰色背景部分为虽然不需要计算,但在计算新的内容时,需要使用的部分。
灰色部分即为“KV Cache”需要缓存的部分。即,每一个 Token 对应的 “K”、“V” 矩阵都需要在后续的计算中使用。亦即,每一个 Token 的 Key 向量都需要保存,用于与新的 Token 的 Query 向量进行点击计算“关注度”值;每一个 Token 的 V 向量也需要保持

在上述的计算中,注意到,在一次的新的“自回归”中,最终需要额外计算的就是新Token(这里是“ a”)对应的 Centextual Embedding,该内容计算,需要使用前述所有 Token 对应的 K、V 值,即这里的 K 和 V 矩阵。
所以,在一次自回归推理中,最好上一次计算的所有 Token 的 K、V 向量都缓存起来,避免重复计算。本次自回归中计算新Token的对应的 K、V 向量也需要缓存,以供后续使用。
4. KV Cache 的内存消耗
在推理优化中,一个重要硬限制便是GPU卡的显存(memory)大小。当前,主流的企业级显卡H100显存为80GB,高端显卡 H200 显存为141 GB。现在的 LLM 参数量通常巨大,参数加载就需要耗费巨大的显存,以最新的 llama 4 17B为例,考虑 FP16 (半精度)考虑,则需要消耗约 30+ GB 。卡片上剩余的内存,才是用于实际的推理使用。而每次推理,例如提示词是1000个Token,输出也是1000个Token,那么,在生成最后一个Token的时候,需要的内存(按5%的经验值计算)约为1.5GB。这时候,单个H100的显卡也只能支持约33个并发,实际的情况则要考虑系统内存等,会比这个预估多很多。
在这篇文章:Mastering LLM Techniques: Inference Optimization@developer.nvidia.com 中也类似的估算:
- 7B 的模型(如Llama 2 7B),参数是16位(FP16 or BF16)则参数需要消耗约 14 GB 显存
- Token 数为4096的推理(decoder),则需要约 2 GB KV Cache
从上述粗略的预估可以看得出来,高效使用显存资源对于 LLM 推理来说至关重要。所以,各推理框架则会通过各种方法尝试去优化“KV Cache”以降低显存使用。这些方法包括“量化”(Quantization)、MQA/MGA 等。
5. Multi-Query Attention/Group-Query Attention
可以看到,无论是在模型参数加载的时候,还是推理 KV Cache 阶段,都需要大量的显存。关于 MQA 和 GQA 的经典论文是:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints。
5.1 关于MQA与GQA
Multi-Query Attention 则尝试通过减少 \(W^K \, W^V \) 参数的数量来减少上述显存,从而增加推理速度与并发能力。参考下图,可以看到在每一个 Layer 中,所有的 Head 共享一组 \(W^K \, W^V \) 参数,那么这两个相关参数就减少到了原来的 \(\frac{1}{h} \)。
更进一步的,为了减少上述方法(MQA)对于模型效果的影响,另一个优化是 Group-Query Attention。即如下图,一组 Heads 共享一组 \(W^K \, W^V \) 。可以依照分组的大小,以平衡模型效果与资源使用。如果一个 Head 一组 \(W^K \, W^V \) 则退化到普通的 Multi-Head Attention;如果所有 Heads 分到一组,则退化到普通的 Multi-Query Attention。

5.2 模型训练 Uptraining
此外,比较关键的,论文提出了一些关于 GQA 架构的训练优化。
例如,从一个 MHA 架构开始训练,然后从某个 checkpoint 开始,将MHA模型改成GQA模型,在初始化分组参数时,则使用原 MHA 模型中参数去求一个均值的方式初始化GQA中对应的 \(W^K \, W^V \) 。然后继续使用语料库对于该新模型训练。
论文指出,这时候只需要使用非常少的计算资源就可以训练处效果还不错的GQA新模型。新的GQA模型,则可以使用更少的显存资源,有更好的并发吞吐能力,同时也达到还比较好的效果。
参考
-

在整个大语言模型学习之路中,对 Attention 机制的理解大概是最为让我困惑的部分,最终经过层层解构、加上重新把“线性代数”温习了一遍之后,最终,总算某种程度的理解了 Attention 机制的设计。相信对于所有NLP专业的人,这部分都是不太容易理解的。
目录
1. 概述
要想讲清楚,大概也是非常不容易的,这里就做一个尝试吧。这里的重点是讲清楚 Attention Score (简称Attention)的计算。介绍的顺序是“两个词语的相似度”、“Similarity Score Matrix”、“Attention Score Matrix”。
1.1 要构建的是直觉,而不是“推理”
为什么 Attention 理解起来很难呢?我想其中有一个原因大概是这个“机制”本身并不是某种“公式推导”出来的,而是通过一篇篇论文与实践,被证明非常有效的一个机制,所以,这个机制本身的所具备的“可解释性”其实也是有限的。这大概也是,无论你在互联网上如何搜索,也没有谁可以比较简单的把这个机制说清楚的原因。但,理解这个机制构建的直觉,对于理解整个 Transformer ,以及整个当代大语言模型技术基础都是至关重要的。
2. 预处理
在“大语言模型的输入:tokenize”中详细介绍了“提示词”进入大模型处理之前,如何将提示词换行成大模型可以处理的“词向量”或者说“token embedding”。
大语言模型在开始“Attention”计算之前,还会对“token embedding”进行一些预处理,这些预处理包括了“融入”位置向量、对向量进行“归一化”处理(将各个向量都转化为均值为0、方差为1的向量,长度要统一变成1吗?)。
例如,在这里的例子中,提示词 “It’s very hot in summer. Swimming is”,先转换为embedding,然后加上位置编码(positional encoder)、再进行正规化,最后变换为如下的向量 “ X ” :
|-------------------------------------------------------------------------------------------------------------------------------------------
| Token | wte[:3] (word token embedding) | wpe[:3](word positional e..)| wte [:3] + wpe [:3] | X[:3] (Norm) |
|-------------------------------------------------------------------------------------------------------------------------------------------
|It | [0.039, -0.0869, 0.0662 ,...] | [-0.0188, -0.1974, 0.004 ] | [0.0202, -0.2844,0.0702 ] | [ 0.0129, -0.1104, -0.0317,...] |
|âĢ | [-0.075, 0.0948, -0.0034,...] | [0.024, -0.0538, -0.0949] | [-0.051, 0.041, -0.0982] | [-0.0530, 0.0588, -0.1290,...] |
|Ļ | [-0.0223, 0.0182, 0.2631 ,...] | [0.0042, -0.0848, 0.0545 ] | [-0.0181,-0.0666,0.3176 ] | [-0.0170, -0.0242, 0.1639,...] |
|s | [-0.064, -0.0469, 0.2061 ,...] | [-0.0003, -0.0738, 0.1055 ] | [-0.0643,-0.1207,0.3116 ] | [-0.0754, -0.0842, 0.1842,...] |
|Ġvery | [-0.0553, -0.0348, 0.0606 ,...] | [0.0076, -0.0251, 0.127 ] | [-0.0477,-0.0599,0.1876 ] | [-0.0566, -0.0280, 0.0953,...] |
|Ġhot | [0.0399, -0.0053, 0.0742 ,...] | [0.0096, -0.0339, 0.1312 ] | [0.0495, -0.0392,0.2054 ] | [ 0.0587, -0.0086, 0.1073,...] |
|Ġin | [-0.0337, 0.0108, 0.0293 ,...] | [0.0027, -0.0205, 0.1196 ] | [-0.031, -0.0098,0.149 ] | [-0.0391, 0.0209, 0.0731,...] |
|Ġsummer | [0.0422, 0.0138, -0.0213,...] | [0.0025, -0.0032, 0.1174 ] | [0.0448, 0.0106, 0.0961 ] | [ 0.0532, 0.0397, 0.0181,...] |
|. | [0.0466, -0.0113, 0.0283 ,...] | [-0.0012, -0.0018, 0.111 ] | [0.0454, -0.0131,0.1394 ] | [ 0.0553, 0.0152, 0.0579,...] |
|ĠSw | [0.0617, 0.0373, 0.1018 ,...] | [0.0049, 0.0021, 0.1178 ] | [0.0666, 0.0395, 0.2196 ] | [ 0.0807, 0.0691, 0.1216,...] |
|imming | [-0.1385, -0.1774, -0.0181,...] | [0.0016, 0.0062, 0.1004 ] | [-0.1369,-0.1711,0.0823 ] | [-0.1528, -0.1249, -0.0017,...] |
|Ġis | [-0.0097, 0.0101, 0.0556 ,...] | [-0.0036, 0.0175, 0.1068 ] | [-0.0133,0.0275, 0.1623 ] | [-0.0175, 0.0605, 0.0880,...] |
|-------------------------------------------------------------------------------------------------------------------------------------------这里的 “X” 是一个由12个 “token embedding”组成的矩阵,“形状”是 12 x 768 。在数学符号上,有:
--------------------------------------- ------------------------------------------ -------------
| [ 0.0129, -0.1104, -0.0317,...] | | x_1 = [ 0.0129, -0.1104, -0.0317,...] | |It |
| [-0.0530, 0.0588, -0.1290,...] | | x_2 = [-0.0530, 0.0588, -0.1290,...] | |âĢ |
| [-0.0170, -0.0242, 0.1639,...] | | x_3 = [-0.0170, -0.0242, 0.1639,...] | |Ļ |
| [-0.0754, -0.0842, 0.1842,...] | | x_4 = [-0.0754, -0.0842, 0.1842,...] | |s |
| [-0.0566, -0.0280, 0.0953,...] | | x_5 = [-0.0566, -0.0280, 0.0953,...] | |Ġvery |
| X = [ 0.0587, -0.0086, 0.1073,...] | | x_6 = [ 0.0587, -0.0086, 0.1073,...] | |Ġhot |
| [-0.0391, 0.0209, 0.0731,...] | | x_7 = [-0.0391, 0.0209, 0.0731,...] | |Ġin |
| [ 0.0532, 0.0397, 0.0181,...] | | x_8 = [ 0.0532, 0.0397, 0.0181,...] | |Ġsummer |
| [ 0.0553, 0.0152, 0.0579,...] | | x_9 = [ 0.0553, 0.0152, 0.0579,...] | |. |
| [ 0.0807, 0.0691, 0.1216,...] | | x_10 = [ 0.0807, 0.0691, 0.1216,...] | |ĠSw |
| [-0.1528, -0.1249, -0.0017,...] | | x_11 = [-0.1528, -0.1249, -0.0017,...] | |imming |
| [-0.0175, 0.0605, 0.0880,...] | | x_12 = [-0.0175, 0.0605, 0.0880,...] | |Ġis |
--------------------------------------- ------------------------------------------ -------------3. Similarity Score Matrix
在正式介绍 Attention 之前,为了能够比较好的理解“为什么”是这样,这里先引入了“Similarity”的概念,最终在该概念上,新增权重矩阵,就是最终的 Attention :
$$ \text{Similarity} = \text{softmax}(\frac{XX^{T}}{\sqrt{d}})X $$
这里删除了参数矩阵:\(W^Q \quad W^K \quad W^V \)
$$ \text{Attention} = \text{softmax}(\frac{QK^{T}}{\sqrt{d}})V $$
其中, \(Q = XW^Q \quad K = XW^K \quad V = XW^V \)
3.1 两个“词语”的相似度
在向量为单位长度的时候,通常可以直接使用“内积”作为两个向量的相似度度量。例如,考虑词语 “hot” 与 “summer” 的相似度,则可以“简化”的处理这两个词(Token)的向量的“内积”。
在前面的文章“大语言模型的输入:tokenize”中,较为详细的介绍了大语言模型如何把一个句子转换成一个的 Token,然后再转换为一个个“向量”。那么,我们通常会通过两个向量的余弦相似度来描述其相似度,如果向量的“长度”(\(L_2 \) 范数)是单位长度,那么也通常会直接使用“内积”描述两个向量的相似度:
$$
\cos \theta = \frac{\alpha \cdot \beta}{\|\alpha\| \|\beta\| }
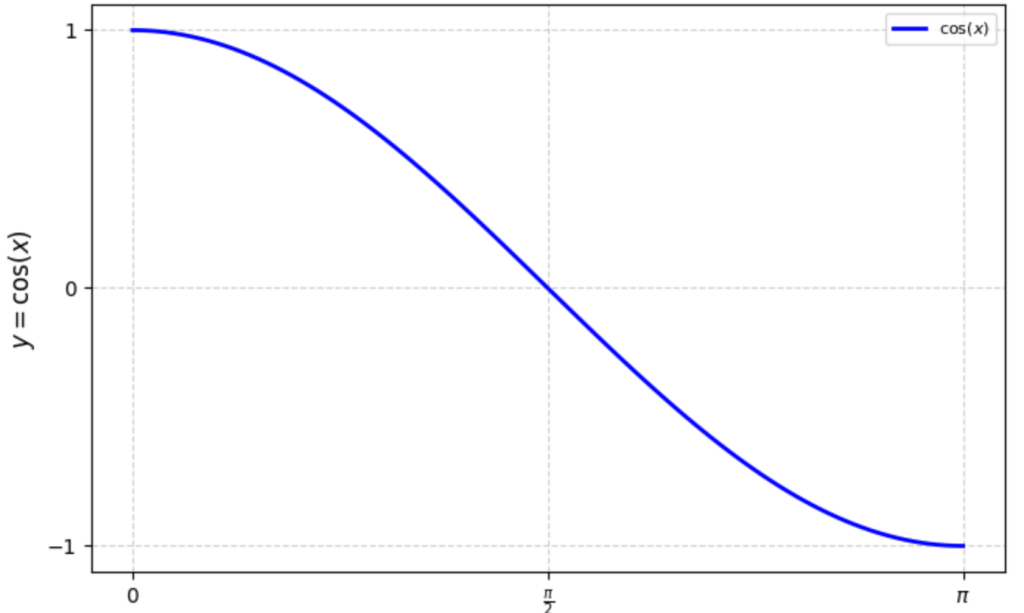
$$\(f(x) = \cos(x) \) 的图像如右图,故:
- 夹角为 0 时,最为相似,这时候 \(\cos(x) = 1 \)
- 夹角 \(\pi \) 时,最“不”相似,这时候 \(\cos(x) = 0 \)
例如,
3.2 “Similarity Score Matrix”
因为两个向量的“内积”某种程度可以表示为相似度。那么,对于句子中的某个 token 来说,与其他所有向量各自计算“内积”,就可以获得一个与其他所有向量“相似程度”的数组,再对这个数组进行 softmax 计算就可以获得一个该 token 与其他所有向量“相似程度”的归一化数组。这个归一化的数据,就可以理解为这里的“Similarity Score Matrix”。
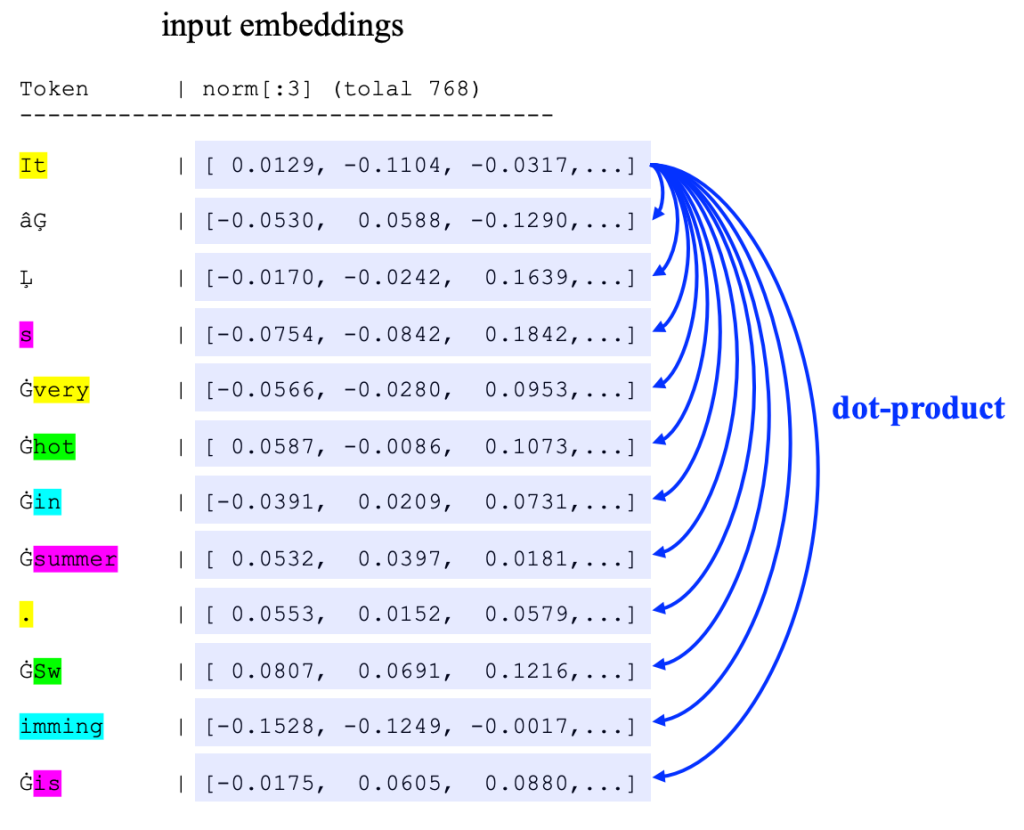
这里依旧以“大语言模型的输入:tokenize”示例中的句子为演示示例。
更为具体的,可以参考右图。这里考虑 Token “It” 与其他所有词语的相似度。即计算 Token “It” 的 Embedding 向量,与其他所有向量的“内积”。
更进一步,如果计算两两词语之间的相似度,并进行归一化(softmax ),则有如下的Similarity Matrix:
[0.6975, 0.0347, 0.0236, 0.0298, 0.0386, 0.0282, 0.0272, 0.0270, 0.0216, 0.0244, 0.0219, 0.0254]
[0.0000, 0.9994, 0.0002, 0.0000, 0.0000, 0.0001, 0.0000, 0.0000, 0.0000, 0.0001, 0.0001, 0.0000]
[0.0000, 0.0004, 0.9987, 0.0001, 0.0001, 0.0001, 0.0000, 0.0002, 0.0000, 0.0001, 0.0002, 0.0000]
[0.0002, 0.0003, 0.0004, 0.9945, 0.0008, 0.0004, 0.0011, 0.0003, 0.0007, 0.0005, 0.0002, 0.0007]
[0.0013, 0.0012, 0.0013, 0.0042, 0.9724, 0.0044, 0.0047, 0.0021, 0.0030, 0.0013, 0.0012, 0.0028]
[0.0002, 0.0003, 0.0003, 0.0004, 0.0009, 0.9932, 0.0005, 0.0020, 0.0004, 0.0009, 0.0006, 0.0003]
[0.0049, 0.0048, 0.0038, 0.0299, 0.0258, 0.0125, 0.7728, 0.0086, 0.0779, 0.0095, 0.0025, 0.0471]
[0.0001, 0.0001, 0.0005, 0.0002, 0.0003, 0.0015, 0.0002, 0.9959, 0.0002, 0.0003, 0.0003, 0.0002]
[0.0049, 0.0048, 0.0045, 0.0255, 0.0203, 0.0126, 0.0974, 0.0082, 0.7698, 0.0094, 0.0024, 0.0401]
[0.0001, 0.0001, 0.0001, 0.0002, 0.0001, 0.0003, 0.0001, 0.0002, 0.0001, 0.9983, 0.0002, 0.0002]
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.9998, 0.0000]
[0.0033, 0.0027, 0.0028, 0.0129, 0.0110, 0.0063, 0.0334, 0.0055, 0.0228, 0.0075, 0.0025, 0.8893]在这个示例中,则会有上述 12×12 的矩阵。该矩阵反应了“词”与“词”之间的相似度。如果,我们把每一行再进行一个“归一化”(注右图已经经过了归一化),那么每一行,就反应了一个词语与其他所有词语相似程度的一个度量。
例如,右图中 it 可能与 very 最为相似(除了自身)。
4. Self-Attention
4.1 对比
注意到最终的 “Attention” 计算公式和上述的“Similarity Score Matrix”的差别就是参数矩阵W:
$$ \text{Similarity Score} = \text{softmax}(\frac{XX^{T}}{\sqrt{d}})X $$
这里没有参数矩阵:\(W^Q \quad W^K \quad W^V \)
$$ \text{Attention} = \text{softmax}(\frac{QK^{T}}{\sqrt{d}})V $$
其中, \(Q = XW^Q \quad K = XW^K \quad V = XW^V \)
4.2 为什么需要参数矩阵 W
那么,为什么需要 \(W^Q \,, W^K \,, W^V \) 呢?这三个参数矩阵乘法,意味着什么呢?要说清楚、要理解这个点并不容易,也没有什么简单的描述可以说清楚的,这也大概是为什么,对于非 NLP 专业的人,要想真正理解 Transformer 或 Attention 是比较困难的。
你可能会看到过一种比较普遍的、简化版本,大概是说 \(W^Q \) 是一个 Query 矩阵,表示要查询什么;\(W^K \) 是一个 Key 矩阵,表示一个词有什么。这个说法似乎并不能增加对上述公式的理解。
那么,一个向量乘以一个矩阵时,这个“矩阵”意味着什么?是的,就是“线性变换”。
4.3 线性变换 Linear Transformations
一般来说,\(W^Q \,, W^K \,, W^V \) 是一个 \(d \times d \) 的矩阵[1]。对于的 Token Embedding (上述的矩阵 X )所在的向量空间,那么 \(W^Q \,, W^K \,, W^V \) 就是该向量空间的三个“线性变换”。
那么线性变换对于向量空间的作用是什么呢?这里我们以“奇异值分解”的角度来理解这个问题[2],即对向量进行拉伸/压缩、旋转、镜像变换。\(W^Q \,, W^K \,, W^V \) 则会分别对向量空间的向量(即Token Embedding)做类似的变换。变换的结果即为:
$$ Q = XW^Q \quad \quad K = XW^K \quad \quad V = XW^V $$
那么,如果参数矩阵“设计”合理,“Token”与“Token”之间就可以建立“期望”的 Attention 关系,例如:“代词”(it),总是更多的关注于“名词”;“名词”更多的关注与附近的“形容词”;再比如,“动词”更多关注前后的“名词”等。除了词性,线性变换关注的“维度”可能有很多,例如“位置”、“情感”、“动物”、“植物”、“积极/消极”等。关于如何理解 token embedding 的各个“维度”含义可以参考:Word Embedding 的可解释性探索。
当然,这三个参数矩阵都不是“设计”出来的,而是“训练”出来的。所以,要想寻找上述如此清晰的“可解释性”并不容易。2019年的论文《What Does BERT Look At? An Analysis of BERT’s Attention》较为系统的讨论了这个问题,感兴趣的可以去看看。
关于线性变换如何作用在向量空间上,可以参考:线性代数、奇异值分解–深度学习的数学基础。
所以,\( \frac{QK^T}{\sqrt{d}} = \frac{XW^Q (XW^K)^T}{\sqrt{d}} \) 则可以系统的表示,每个“Token”对于其他“Token”的关注程度(即pay attention的程度)。可以注意到:
- 增加了参数矩阵\(W^Q \,, W^K \,, W^V \)后,前面的“相似性”矩阵,就变为“注意力”矩阵
- “Token” 之间的关注程度不是对称的。例如 Token A 可能很关注 B;但是 B 可能并不关注 A
- 这里的 \(\sqrt{d} \) 根据论文描述,可以提升计算性能;
如果,你恰好理解了上面所有的描述,大概会有点失望的。就只能到这儿吗?似乎就只能到这里了。如果,你有更深刻的理解,欢迎留言讨论。
接下里,我们来看看 “Attention Score Matrix” 的计算。
4.4 Attention Score Matrix
使用上述的 “Similarity Score Matrix” 的计算方式,可以计算类似的 “Attention Score Matrix”,之后再对该矩阵进行 softmax 计算就可以获得每个词语对于其他所有词语的 Attention Score,或者叫“关注程度”。有了这个关注程度,再乘以 V 矩阵,原来的 Token Embedding 就变换为一个新的带有上下文的含义的 Token Eembedding 了,即 Context Embedding[3]。
类似的,我们有右图的 Attention Score Matrix 计算。
该矩阵反应了两个 Token 之间的 Attention 关系。该关系,通过对经过线性变换的 Token Embedding ,再进行内积计算获得。
Attention Score Matrix (12 x 12)
It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis
-----------------------------------------------------------------------------------
It [ 0.14, -1.53, -1.45, -1.71, -1.69, -1.74, -2.36, -2.27, -2.37, -1.33, -0.58, -2.40] |
âĢ [ 0.70, -0.93, -1.72, -1.02, -1.52, -2.24, -1.90, -2.19, -1.63, -2.13, -1.66, -2.14] |
Ļ [-0.60, -1.81, -1.99, -1.96, -2.57, -1.84, -1.62, -2.04, -0.98, -1.18, -2.23, -2.25] |
s [-0.46, -1.33, -1.60, -2.65, -2.24, -1.99, -2.89, -1.44, -2.05, -2.77, -2.09, -2.74] |
Ġvery [ 0.29, -1.42, -1.77, -1.15, -0.94, -1.14, -1.81, -1.04, -1.77, -2.13, -0.60, -0.82] |
Ġhot [ 0.03, -0.68, -0.59, -0.95, -1.78, -0.10, -0.95, -0.14, -1.32, -0.57, 0.06, -1.07] 12
Ġin [-0.71, -1.72, -1.53, -2.18, -1.67, -1.93, -3.41, -1.69, -2.74, -1.89, -1.17, -2.02] rows
Ġsummer [-0.34, -1.49, -1.35, -1.31, -1.12, -0.89, -1.49, -1.11, -1.51, -1.15, -1.45, -1.20] |
. [-0.89, -1.73, -2.67, -2.80, -2.45, -2.37, -4.39, -2.33, -4.42, -2.73, -1.82, -3.21] |
ĠSw [-0.05, -1.15, -1.76, -1.15, -1.68, -0.74, -1.15, -1.35, -1.36, -1.29, -0.43, -1.51] |
imming [-0.02, -1.65, -0.87, -0.35, -1.18, -0.65, -0.33, -1.25, -0.38, -1.68, -2.15, -1.08] |
Ġis [-0.97, -2.03, -2.56, -2.94, -1.96, -2.71, -4.07, -2.46, -3.51, -2.68, -1.88, -2.99] |
-----------------------------------------------------------------------------------
|<----------------------------- columns: 12 -------------------------------------->|4.5 Masked Attention Score Matrix
上述计算,是一个典型的 Self Attention 计算过程,BERT 模型就使用类似的计算,但 GPT 模型(或者叫 Decoder 模型)还有一些不同。GPT 模型中为了训练出更好的从现有 Token 中生成新 Token 的模型,将上述的 Self Attention 更改成了 Masked Self Attention ,即将 Attention Score Matrix 的右上角部分全部置为 -inf (即负无穷),后续经过 softmax 之后这些值都会变成零,即,在该类模型下,一个词语对于其后面的词的关注度为 0 。
在 Decoder 模型设计中,为了生成更准确的下一个 Token 所以在训练和推理中,仅会计算Token 对之前的 Token 的 Attention ,所以上述的矩阵的右上角部分就会被遮盖,即就是右侧的 “Masked Attention Score Matrix”。
Masked Attention Score Matrix (12 x 12)
It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis
---------------------------------------------------------------------------------------
It [ 0.14, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf] |
âĢ [ 0.70, -0.93, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf] |
Ļ [-0.60, -1.81, -1.99, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf] |
s [-0.46, -1.33, -1.60, -2.65, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf] |
Ġvery [ 0.29, -1.42, -1.77, -1.15, -0.94, -inf, -inf, -inf, -inf, -inf, -inf, -inf] |
Ġhot [ 0.03, -0.68, -0.59, -0.95, -1.78, -0.10, -inf, -inf, -inf, -inf, -inf, -inf] 12
Ġin [-0.71, -1.72, -1.53, -2.18, -1.67, -1.93, -3.41, -inf, -inf, -inf, -inf, -inf] rows
Ġsummer [-0.34, -1.49, -1.35, -1.31, -1.12, -0.89, -1.49, -1.11, -inf, -inf, -inf, -inf] |
. [-0.89, -1.73, -2.67, -2.80, -2.45, -2.37, -4.39, -2.33, -4.42, -inf, -inf, -inf] |
ĠSw [-0.05, -1.15, -1.76, -1.15, -1.68, -0.74, -1.15, -1.35, -1.36, -1.29, -inf, -inf] |
imming [-0.02, -1.65, -0.87, -0.35, -1.18, -0.65, -0.33, -1.25, -0.38, -1.68, -2.15, -inf] |
Ġis [-0.97, -2.03, -2.56, -2.94, -1.96, -2.71, -4.07, -2.46, -3.51, -2.68, -1.88, -2.99] |
---------------------------------------------------------------------------------------
|<----------------------------- columns: 12 -------------------------------------->|通常为了快速计算对于上述的计算值会除以 \(\sqrt{d} \) ,可以提升计算的效率。
4.6 归一化(softmax) Attention Score
对于上述矩阵的每一行都进行一个 softmax 计算,就可以获得一个归一化的按照百分比分配的Attention Score。
经过归一化之后,每个词语对于其他词语的 Attention 程度都可以使用百分比表达处理。例如,“summer”对于“It”的关注程度最高,为26%;其次是关注“hot”,为15%。可以看到这一组线性变换(\(W^Q\,W^K \))对于第一个位置表达特别的关注。
The Attention Score Matrix (12 x 12)
It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis
-----------------------------------------------------------------------------
It [1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00] |
âĢ [0.84 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00] |
Ļ [0.65 0.19 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00] |
s [0.54 0.23 0.17 0.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00] |
Ġvery [0.54 0.10 0.07 0.13 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00] |
Ġhot [0.29 0.14 0.16 0.11 0.05 0.25 0.00 0.00 0.00 0.00 0.00 0.00] 12
Ġin [0.36 0.13 0.16 0.08 0.14 0.11 0.02 0.00 0.00 0.00 0.00 0.00] rows
Ġsummer [0.26 0.08 0.09 0.10 0.12 0.15 0.08 0.12 0.00 0.00 0.00 0.00] |
. [0.40 0.17 0.07 0.06 0.08 0.09 0.01 0.10 0.01 0.00 0.00 0.00] |
ĠSw [0.27 0.09 0.05 0.09 0.05 0.14 0.09 0.07 0.07 0.08 0.00 0.00] |
imming [0.19 0.04 0.08 0.14 0.06 0.10 0.14 0.06 0.13 0.04 0.02 0.00] |
Ġis [0.30 0.10 0.06 0.04 0.11 0.05 0.01 0.07 0.02 0.05 0.12 0.04] |
-----------------------------------------------------------------------------
|<----------------------------- columns: 12 --------------------------->|4.7 Contextual Embeddings
最后,再按照上述的 Attention Matrix 的比例,将各个 Token Embedding 进行一个“加权平均计算”。
例如,上述的加权计算时,“summer” 则会融入 26% 的“It”,15%的“hot”… ,最后生成新的 “summer” 的表达,这个表达也可以某种程度理解为 “Contextual Embeddings”。需要注意的是,这里在计算加权平均,也不是直接使用原始的 Token Embedding ,也是一个经过了线性变换的Embedding,该线性变换矩阵也是经过训练而来的,即矩阵 \(W^V \)。
例如,上述的加权计算时,“summer” 则会融入 26% 的“It”,15%的“hot”… ,最后生成新的 “summer” 的表达,这个表达也可以某种程度理解为 “Contextual Embeddings”。
需要注意的是,这里在计算加权平均,也不是直接使用原始的 Token Embedding ,也是一个经过了线性变换的Embedding,该线性变换矩阵也是经过训练而来的,即矩阵 \(W^V \)。
Token | Contextual Embeddings(12 x 768)
--------------------------------------------
It | [ 0.0452, 0.0628, 0.1463,...]
âĢ | [ 0.0153, 0.0752, 0.1247,...]
Ļ | [ 0.0034, 0.0464, 0.0923,...]
s | [-0.0082, 0.0464, 0.0801,...]
Ġvery | [ 0.0218, 0.1029, 0.0621,...]
Ġhot | [ 0.0327, 0.0892, 0.0409,...]
Ġin | [ 0.0249, 0.0964, 0.0329,...]
Ġsummer | [ 0.0583, 0.1195, 0.0068,...]
. | [ 0.0334, 0.1100, 0.0366,...]
ĠSw | [ 0.0086, 0.0846, 0.0074,...]
imming | [-0.0049, 0.0841, -0.0339,...]
Ġis | [ 0.0410, 0.0706, 0.0077,...]5 计算示意图
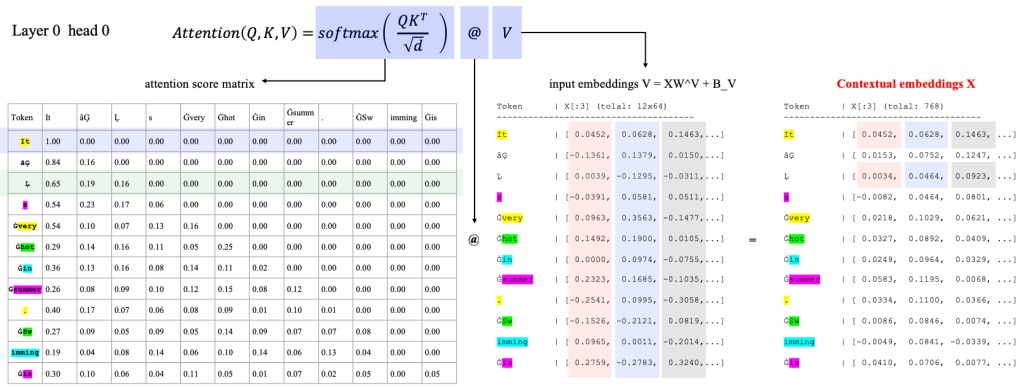
如下的示意图,一定的可视化的表达了,一个 Token 如何经过上述的矩阵运算,如何了其他 Token 的内容。
6. 注意力矩阵的观察
那么,我们给定于如下的提示词输入:“Martin’s one of my sons, and the other is Chanler.”。看看在 GPT 模型中,各个Token之间的 Attention 情况:
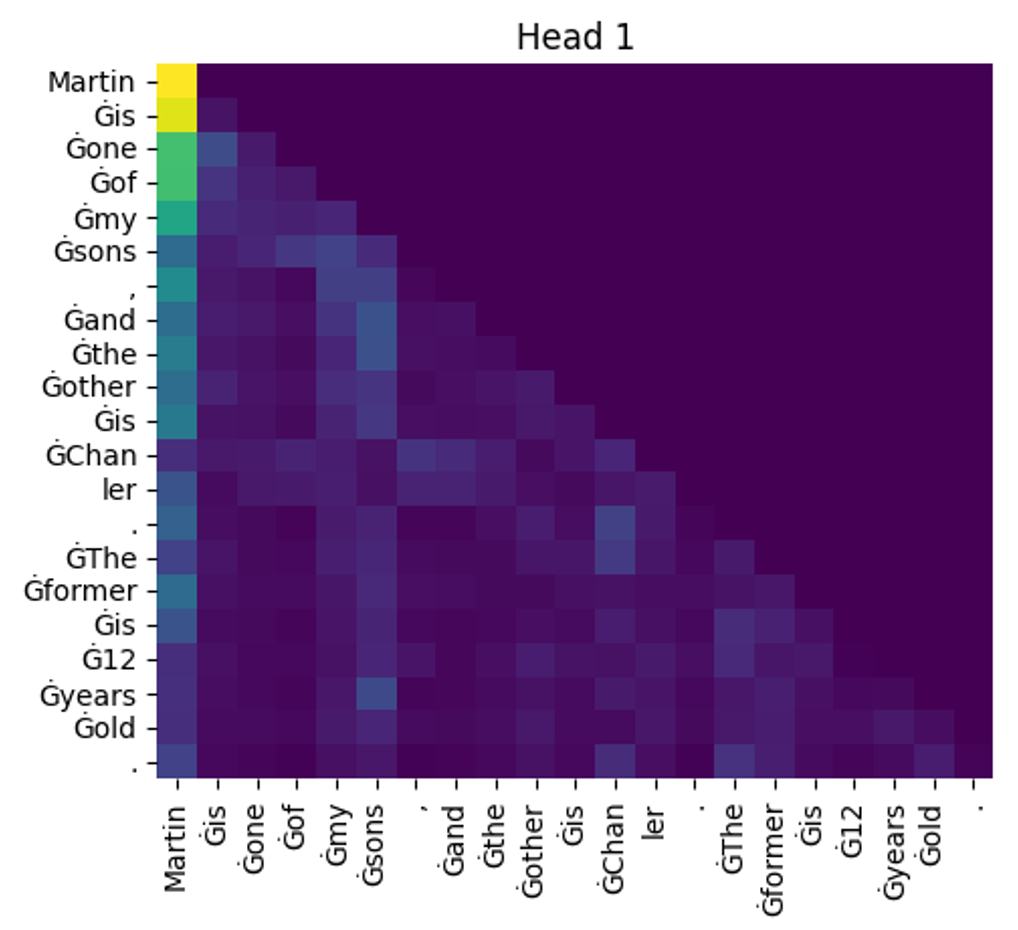
- 这句话总计有21个token,所以这是一个21×21的矩阵
- 这里是“masked self-attention”,所以矩阵的右上半区都是 “0” 。
- 在GPT2中,一共12层,每层12个“头”,所以一共有“144”个类似的矩阵
- \(W^Q \,, W^K \,, W^V \) 的维度都是768×64,所以粗略的估计这部分的参数量就超过2000万,具体的:
768*64*3*144 = 21,233,664
7. Multi-Head Attention
7.1 Scaled Dot-Product Attention
以前面小结“预处理”中的 X 为例,Attention Score Matrix 就有如下的计算公式:
$$
\begin{aligned}
\text{Attention Score Matrix} & = \text{softmax}(\frac{QK^T}{\sqrt{d}}) \\
& = \text{softmax}(\frac{XW^Q(XW^K)^T}{\sqrt{d}})
\end{aligned}
$$最终的 Attention 计算如下:
$$
\begin{aligned}
\text{Attention}(Q,K,V) & = \text{softmax}(\frac{QK^T}{\sqrt{d}})V \\
& = \text{softmax}(\frac{XW^Q(XW^K)^T}{\sqrt{d}})XW^V
\end{aligned}
$$7.2 Multi-Head Attention
上述的“Attention”在论文“Attention Is All You Need”称为“Scaled Dot-Product Attention”。更进一步的在论文中提出了“Multi-Head Attention”(经常被缩写为“MHA”)。对应的公式如下(来自原始论文):
$$
\begin{aligned}
\text{MultiHead}(Q, K, V) & = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O \\
\text{where} \quad \text{head}_i & = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
\end{aligned}
$$更完整的解释,可以参考原始论文。这里依旧以前文的示例来说明什么是MHA。
在本文第4章“Self-Attention”中,较为详细的介绍了相关的计算(即模型的推理过程)。在示例中,一共有12个“Token”,在进入 Attention 计算时经过位置编码、正则化后,12个“Token”向量组成矩阵“X”,这里的“X”的 shape 为 12 x 768,通常使用符号 \(l \times d \) 或者 \(l \times d_{model} \) 表示。最终输出的 Contextual Embedding 也是 \(l \times d_{model} \) 的一组表示12个 Token 向量,这是每个向量相比最初的输入向量,则融合上下文中其他词语的含义。在一个多层的模型中,这组向量则可以作为下一层的输入。
在“Multi-Head Attention”其输入、输出与“Self-Attention”一样,都是 \(l \times d_{model} \) 。但是,对于最终输出的 \(l \times d_{model} \) 的向量/矩阵,在 MHA 中则分为多个 HEAD 各自计算其中的一部分,例如,一共有 \(d_{model} \) 列,那么则分别有 \(h \) 个HEAD,每个 HEAD 输出其中的 \(\frac{d_{model}}{h} \) 列。在上述示例中,供有12个HEAD,即 \(h=12 \),模型维度为768,即\(d_{model} = 768 \),所以每个HEAD,最终输出 \(64 = \frac{d_model}{h} = \frac{768}{12} \) 列。即:
$$
\begin{aligned}
\text{where} \quad \text{head}_i & = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
\end{aligned}
$$然后由12个 Head 共同组成(concat)要输出的 Contextual Embedding,并对此输出做了一个线性变换\(W^O \)。即:
$$
\begin{aligned}
\text{MultiHead}(Q, K, V) & = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O
\end{aligned}
$$7.3 Self Attention vs MHA
Self Attention

Multi Head Attention

7.4 Multi-Head Attention 小结
- “Multi-Head Attention” 与 经典“Attention” 有着类似的效果,但是有着更好的表现性能
- “Multi-Head Attention” 与 经典“Attention” 有相同的输入,相同的输出
8. Attention 数学计算示意图
如下的图片,半可视化的展示了在GTP2中,某一个HEAD中Attention的计算。

9. 全流程数学计算
完整的计算,就是一个“forward propagation”或者叫“inference”的过程,这里依旧以上述的提示词“It’s very hot in summer. Swimming is”,并观察该提示词在 GPT2 模型中的第一个Layer、第一个Head中的计算。完成的代码可以参考:Attention-Please.ipynb
9.1 Token Embedding 和 Positional Embedding
Token Embedding
+
Positional Embedding
|------------ ----------------------------------- ------------------------------- ------------------------------
| Token | | wte[:3] (word token embedding) | | wpe[:3](word positional e..)| | wte [:3] + wpe [:3] |
|------------ ----------------------------------- ------------------------------- ------------------------------
|It | | [0.039, -0.0869, 0.0662 ,...] | | [-0.0188, -0.1974, 0.004 ] | | [0.0202, -0.2844,0.0702 ] |
|âĢ | | [-0.075, 0.0948, -0.0034,...] | | [0.024, -0.0538, -0.0949] | | [-0.051, 0.041, -0.0982] |
|Ļ | | [-0.0223, 0.0182, 0.2631 ,...] | | [0.0042, -0.0848, 0.0545 ] | | [-0.0181,-0.0666,0.3176 ] |
|s | | [-0.064, -0.0469, 0.2061 ,...] | | [-0.0003, -0.0738, 0.1055 ] | | [-0.0643,-0.1207,0.3116 ] |
|Ġvery | | [-0.0553, -0.0348, 0.0606 ,...] | + | [0.0076, -0.0251, 0.127 ] | = | [-0.0477,-0.0599,0.1876 ] |
|Ġhot | | [0.0399, -0.0053, 0.0742 ,...] | | [0.0096, -0.0339, 0.1312 ] | | [0.0495, -0.0392,0.2054 ] |
|Ġin | | [-0.0337, 0.0108, 0.0293 ,...] | | [0.0027, -0.0205, 0.1196 ] | | [-0.031, -0.0098,0.149 ] |
|Ġsummer | | [0.0422, 0.0138, -0.0213,...] | | [0.0025, -0.0032, 0.1174 ] | | [0.0448, 0.0106, 0.0961 ] |
|. | | [0.0466, -0.0113, 0.0283 ,...] | | [-0.0012, -0.0018, 0.111 ] | | [0.0454, -0.0131,0.1394 ] |
|ĠSw | | [0.0617, 0.0373, 0.1018 ,...] | | [0.0049, 0.0021, 0.1178 ] | | [0.0666, 0.0395, 0.2196 ] |
|imming | | [-0.1385, -0.1774, -0.0181,...] | | [0.0016, 0.0062, 0.1004 ] | | [-0.1369,-0.1711,0.0823 ] |
|Ġis | | [-0.0097, 0.0101, 0.0556 ,...] | | [-0.0036, 0.0175, 0.1068 ] | | [-0.0133,0.0275, 0.1623 ] |
|------------ ----------------------------------- ------------------------------- ------------------------------9.2 Normalize
即,将每一个token的embedding 进行正规化,将其均值变为0,方差变为1
Token | X norm[:3] (12 x 768)
--------------------------------------------
It | [ 0.0129, -0.1104, -0.0317,...]
âĢ | [-0.0530, 0.0588, -0.1290,...]
Ļ | [-0.0170, -0.0242, 0.1639,...]
s | [-0.0754, -0.0842, 0.1842,...]
Ġvery | [-0.0566, -0.0280, 0.0953,...]
Ġhot | [ 0.0587, -0.0086, 0.1073,...]
Ġin | [-0.0391, 0.0209, 0.0731,...]
Ġsummer | [ 0.0532, 0.0397, 0.0181,...]
. | [ 0.0553, 0.0152, 0.0579,...]
ĠSw | [ 0.0807, 0.0691, 0.1216,...]
imming | [-0.1528, -0.1249, -0.0017,...]
Ġis | [-0.0175, 0.0605, 0.0880,...]9.3 Attention 层的参数矩阵
\(W^Q\,,W^K\,,W^V \)
W^Q [:3] shape (768 x 64) W^K [:3] shape (768 x 64) W^V [:3] shape (768 x 64)
------------------------------------- -------------------------------- --------------------------------
[-0.4738, -0.2614, -0.0978, ...] | [ 0.3660, 0.0771, 0.2226, ...] [ 0.1421, 0.0329, -0.0667, ...]
[ 0.0874, 0.1473, 0.2387, ...] | [-0.4380, -0.1446, -0.4717, ...] [ 0.0162, -0.0633, -0.0636, ...]
[ 0.0039, 0.0695, 0.3668, ...] | [ 0.1237, 0.0174, 0.1181, ...] [ 0.0229, -0.0828, 0.0437, ...]
[ 0.2215, -0.1884, -0.0141, ...] 64 [-0.2247, 0.0148, -0.1859, ...] [-0.0106, 0.0070, 0.0565, ...]
[-0.0947, 0.1678, -0.0143, ...] rows [-0.2001, -0.1052, -0.1743, ...] [ 0.0416, 0.0938, -0.1792, ...]
... | ... ...
[-0.4100, -0.1924, -0.2400, ...] | [,0.1567, 0.2664, 0.1851, ...] [-0.0341, 0.0034, 0.0203, ...]
------------------------------------- -------------------------------- --------------------------------
|<------- columns: 768 ------->| |<------- columns: 768 ------->| |<------- columns: 768 ------->|9.4 矩阵 Q K V的计算
\(Q = XW^Q \)
\(K = XW^K \)
\(V = XW^V \)
Q [:3] shape (12 x 64) K [:3] shape (12 x 64) V [:3] shape (12 x 64)
------------------------------------- --------------------------------- --------------------------------
[ 0.4207, -0.9178, 0.1760, ...] | [ -1.4202, 1.6791, 0.9837, ...] [ 0.0452, 0.0628, 0.1463, ...]
[ 0.7757, 0.2485, 0.7349, ...] | [ -2.5320, 2.2932, 1.5592, ...] [-0.1361, 0.1379, 0.0150, ...]
[ 0.4481, 0.0206, -0.0825, ...] | [ -2.2571, 2.7764, 1.8401, ...] [ 0.0039, -0.1295, -0.0311, ...]
[ 0.9500, 0.1481, 0.3469, ...] 12 [ -2.4322, 3.1454, 2.0600, ...] [-0.0391, 0.0581, 0.0511, ...]
[ 0.4989, -0.4376, 0.1678, ...] rows [ -3.5428, 2.1485, 2.0414, ...] [ 0.0963, 0.3563, -0.1477, ...]
... | ... ...
[ 0.4429, -1.1997, 0.5611, ...] | [ -2.2559, 2.0384, 2.2542, ...] [ 0.2759, -0.2783, 0.3240, ...]
------------------------------------- --------------------------------- --------------------------------
|<------- columns: 64 ------->| |<------- columns: 64 ------->| |<------- columns: 64 ------->|9.5 计算 Attention Score
\(\text{Attention Score} \)
\(= \frac{QK^T}{\sqrt{d}} \)
|---------------------------------------------------------------------------------------------|
| | Attention Score Matrix shape (12 x 12) |
| Token |-------------------------------------------------------------------------------------|
| | It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis |
|-------|-------------------------------------------------------------------------------------|----
|It | [ 0.14, -1.53, -1.45, -1.71, -1.69, -1.74, -2.36, -2.27, -2.37, -1.33, -0.58, -2.40]| |
|âĢ | [ 0.70, -0.93, -1.72, -1.02, -1.52, -2.24, -1.90, -2.19, -1.63, -2.13, -1.66, -2.14]| |
|Ļ | [-0.60, -1.81, -1.99, -1.96, -2.57, -1.84, -1.62, -2.04, -0.98, -1.18, -2.23, -2.25]| |
|s | [-0.46, -1.33, -1.60, -2.65, -2.24, -1.99, -2.89, -1.44, -2.05, -2.77, -2.09, -2.74]| |
|Ġvery | [ 0.29, -1.42, -1.77, -1.15, -0.94, -1.14, -1.81, -1.04, -1.77, -2.13, -0.60, -0.82]| |
|Ġhot | [ 0.03, -0.68, -0.59, -0.95, -1.78, -0.10, -0.95, -0.14, -1.32, -0.57, 0.06, -1.07]| 12
|Ġin | [-0.71, -1.72, -1.53, -2.18, -1.67, -1.93, -3.41, -1.69, -2.74, -1.89, -1.17, -2.02]| rows
|Ġsummer| [-0.34, -1.49, -1.35, -1.31, -1.12, -0.89, -1.49, -1.11, -1.51, -1.15, -1.45, -1.20]| |
|. | [-0.89, -1.73, -2.67, -2.80, -2.45, -2.37, -4.39, -2.33, -4.42, -2.73, -1.82, -3.21]| |
|ĠSw | [-0.05, -1.15, -1.76, -1.15, -1.68, -0.74, -1.15, -1.35, -1.36, -1.29, -0.43, -1.51]| |
|imming | [-0.02, -1.65, -0.87, -0.35, -1.18, -0.65, -0.33, -1.25, -0.38, -1.68, -2.15, -1.08]| |
|Ġis | [-0.97, -2.03, -2.56, -2.94, -1.96, -2.71, -4.07, -2.46, -3.51, -2.68, -1.88, -2.99]| |
|-------|-------------------------------------------------------------------------------------|----
|<-------------------------------- columns: 12 -------------------------------------->|9.6 计算 Masked Attention Score
\(\text{Masked Attention Score} \)
\(= \frac{QK^T}{\sqrt{d}} + \text{mask} \)
|---------------------------------------------------------------------------------------------|
| | Masked Attention Score Matrix shape (12 x 12) |
| Token |-------------------------------------------------------------------------------------|
| | It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis |
|-------|-------------------------------------------------------------------------------------|----
|It | [ 0.14, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf]| |
|âĢ | [ 0.70, -0.93, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf]| |
|Ļ | [-0.60, -1.81, -1.99, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf]| |
|s | [-0.46, -1.33, -1.60, -2.65, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf]| |
|Ġvery | [ 0.29, -1.42, -1.77, -1.15, -0.94, -inf, -inf, -inf, -inf, -inf, -inf, -inf]| |
|Ġhot | [ 0.03, -0.68, -0.59, -0.95, -1.78, -0.10, -inf, -inf, -inf, -inf, -inf, -inf]| 12
|Ġin | [-0.71, -1.72, -1.53, -2.18, -1.67, -1.93, -3.41, -inf, -inf, -inf, -inf, -inf]| rows
|Ġsummer| [-0.34, -1.49, -1.35, -1.31, -1.12, -0.89, -1.49, -1.11, -inf, -inf, -inf, -inf]| |
|. | [-0.89, -1.73, -2.67, -2.80, -2.45, -2.37, -4.39, -2.33, -4.42, -inf, -inf, -inf]| |
|ĠSw | [-0.05, -1.15, -1.76, -1.15, -1.68, -0.74, -1.15, -1.35, -1.36, -1.29, -inf, -inf]| |
|imming | [-0.02, -1.65, -0.87, -0.35, -1.18, -0.65, -0.33, -1.25, -0.38, -1.68, -2.15, -inf]| |
|Ġis | [-0.97, -2.03, -2.56, -2.94, -1.96, -2.71, -4.07, -2.46, -3.51, -2.68, -1.88, -2.99]| |
|-------|-------------------------------------------------------------------------------------|----
|<-------------------------------- columns: 12 -------------------------------------->|9.7 计算 Softmax Masked Attention Score
\(\text{Softmax Masked Attention Score} \)
\(= \text{softmax}(\frac{QK^T}{\sqrt{d}} + \text{mask}) \)
|-------------------------------------------------------------------------------------|
| | Softmax Masked Attention Score Matrix shape (12 x 12) |
| Token |-----------------------------------------------------------------------------|
| | It âĢ Ļ s Ġvery Ġhot Ġin Ġsummer . ĠSw imming Ġis |
|-------|-----------------------------------------------------------------------------|
|It | [1.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| |
|âĢ | [0.84 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| | V [:3] shape (12 x 64)
|Ļ | [0.65 0.19 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| | --------------------------------
|s | [0.54 0.23 0.17 0.06 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| | [ 0.0452, 0.0628, 0.1463, ...]
|Ġvery | [0.54 0.10 0.07 0.13 0.16 0.00 0.00 0.00 0.00 0.00 0.00 0.00]| | [-0.1361, 0.1379, 0.0150, ...]
|Ġhot | [0.29 0.14 0.16 0.11 0.05 0.25 0.00 0.00 0.00 0.00 0.00 0.00]| 12 [ 0.0039, -0.1295, -0.0311, ...]
|Ġin | [0.36 0.13 0.16 0.08 0.14 0.11 0.02 0.00 0.00 0.00 0.00 0.00]| rows [-0.0391, 0.0581, 0.0511, ...]
|Ġsummer| [0.26 0.08 0.09 0.10 0.12 0.15 0.08 0.12 0.00 0.00 0.00 0.00]| | [ 0.0963, 0.3563, -0.1477, ...]
|. | [0.40 0.17 0.07 0.06 0.08 0.09 0.01 0.10 0.01 0.00 0.00 0.00]| | ...
|ĠSw | [0.27 0.09 0.05 0.09 0.05 0.14 0.09 0.07 0.07 0.08 0.00 0.00]| | [ 0.2759, -0.2783, 0.3240, ...]
|imming | [0.19 0.04 0.08 0.14 0.06 0.10 0.14 0.06 0.13 0.04 0.02 0.00]| | --------------------------------
|Ġis | [0.30 0.10 0.06 0.04 0.11 0.05 0.01 0.07 0.02 0.05 0.12 0.04]| | |<------- columns: 64 ------->|
|-------|-----------------------------------------------------------------------------|
|<-------------------------------- columns: 12 ------------------------------>|9.8 计算 Contextual Embeddings
\(\text{Contextual Embeddings} \)
\(= \text{softmax}(\frac{QK^T}{\sqrt{d}} + \text{mask})V \)
Token | Contextual Embedding (12 x 768)
--------------------------------------------
It | [ 0.0452, 0.0628, 0.1463,...]
âĢ | [ 0.0153, 0.0752, 0.1247,...]
Ļ | [ 0.0034, 0.0464, 0.0923,...]
s | [-0.0082, 0.0464, 0.0801,...]
Ġvery | [ 0.0218, 0.1029, 0.0621,...]
Ġhot | [ 0.0327, 0.0892, 0.0409,...]
Ġin | [ 0.0249, 0.0964, 0.0329,...]
Ġsummer | [ 0.0583, 0.1195, 0.0068,...]
. | [ 0.0334, 0.1100, 0.0366,...]
ĠSw | [ 0.0086, 0.0846, 0.0074,...]
imming | [-0.0049, 0.0841, -0.0339,...]
Ġis | [ 0.0410, 0.0706, 0.0077,...]10. 其他
上述流程详述了 LLM 模型中 Attention 计算的核心部分。也有一些细节是省略了的,例如,
- 在GPT2中,“线性变换”是有一个“截距”(Bias)的,所以也可以称为一个“仿射变换”,即在一个线性变换基础上,再进行一次平移;
- 在GTP2中,Attention计算都是多层、多头的,本文主要以Layer 0 / Head 0 为例进行介绍;
- 在生成最终的“Contextual Embeddings”之前,通常还需要一个MLP层(全连接的前馈神经网络)等,本文为了连贯性,忽略了该部分。
总结一下,本文需要的前置知识包括:矩阵基本运算、矩阵与线性变换、SVD 分解/特征值特征向量、神经网络基础、深度学习基础等。
注
- [1] 多头注意情况可能是 \(d \times \frac{d}{h} \)
- [2] 对于满秩方阵也可以使用“特征值/特征向量”的方式去理解
- [3] 在 GPT 2 中,一个 Attention 层的计算,会分为“多头”去计算;并在计算后,还会再经过一个 MLP 层
