这是个人博客站点,记录了零散的想法。包括:数据库技术、生活与见闻,以及相关的云计算、AI/LLM等技术分享。

Featured Posts

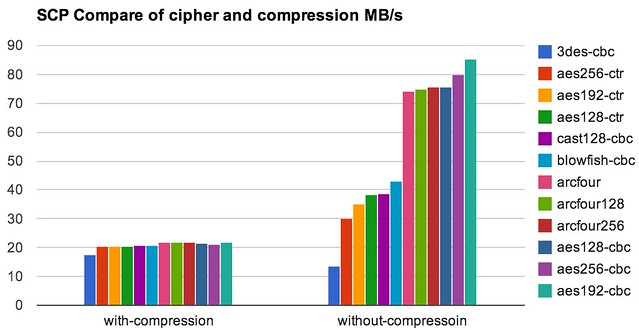
在这里测试中,通过简单的参数-c arcfour128或-c aes192-cbc可以大大加速scp传输
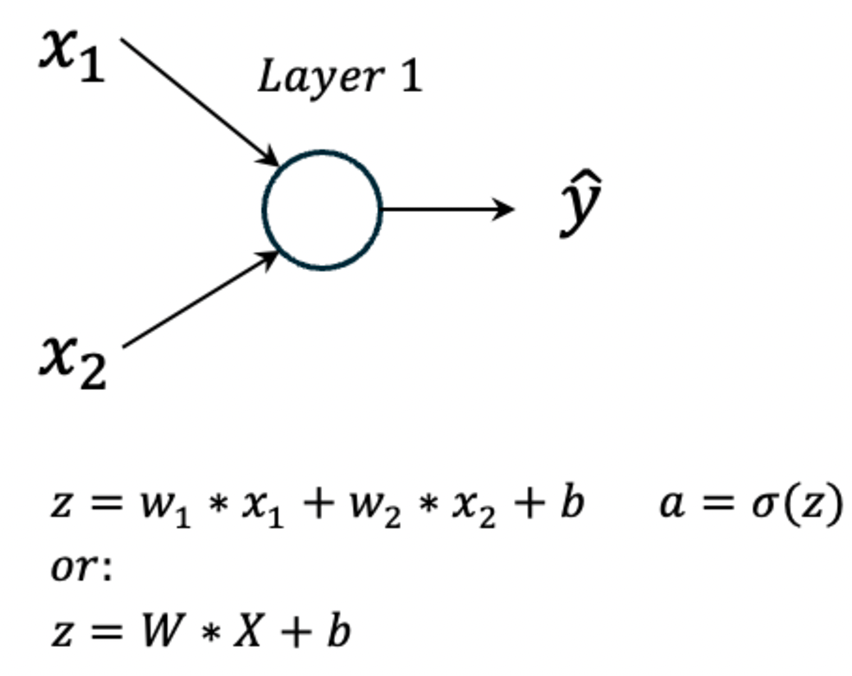
麻雀虽小、五脏俱全,包含了梯度下降的实现、链式法则的应用等,如果理解了该示例,则可以很好帮助开发者打好基础,以便更好的理解更为复杂的神经网络的训练

这是我们常去的一个图书馆,这里夏天冷气足、冬天暖气够,是身体避暑抗寒,也是心理抗压力与浮躁的好去处。同一片建筑群里还有“省博物馆之江馆区”。地下一层是用餐区,有浙江各地特色美食,也有KFC、Subway、知味观等

这次行程共9天,驱车自驾约2600公里,一路从西宁到青海湖,再到德令哈、乌苏特雅丹、敦煌、张掖、祁连,最后返回西宁

人群喧闹,而数亿年来山峰从不言语,只是静静伫立,一时让人恍惚,到底是谁在看着谁?
云数据库性能专题
在不同的云厂商,购买相同规格的 MySQL 实例,获得的性能相同吗?本文使用 Sysybench,对不同云厂商的同样规格“4vCPU-16GB”进行性能测试来尝试回答上述问题:
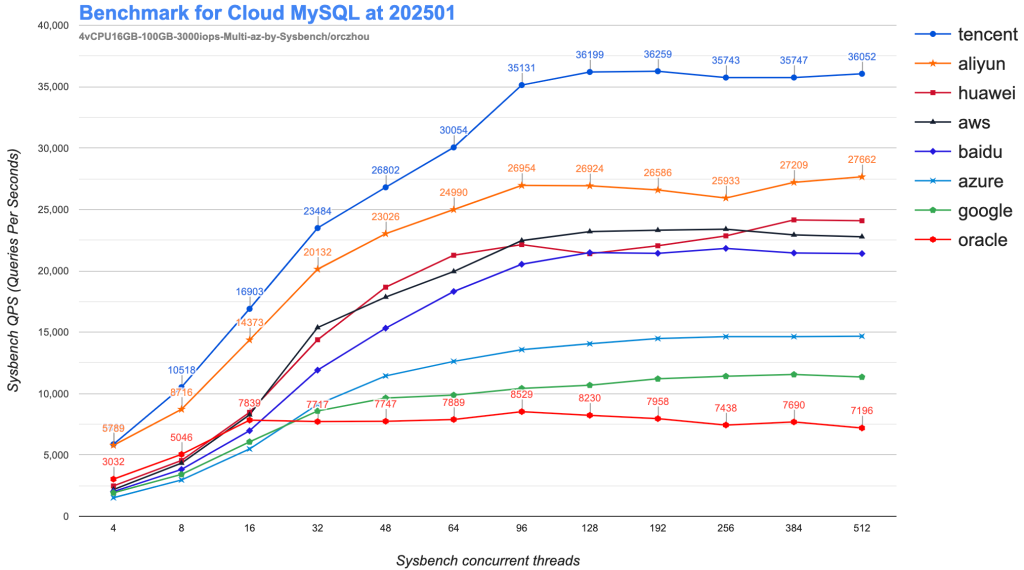
从实际测试来看,不同的云厂商,想通的规格,性能差异非常大,关于该测试的详细解读参考:云数据库 RDS MySQL 的性能综述
Featured Images





Top viewed Posts
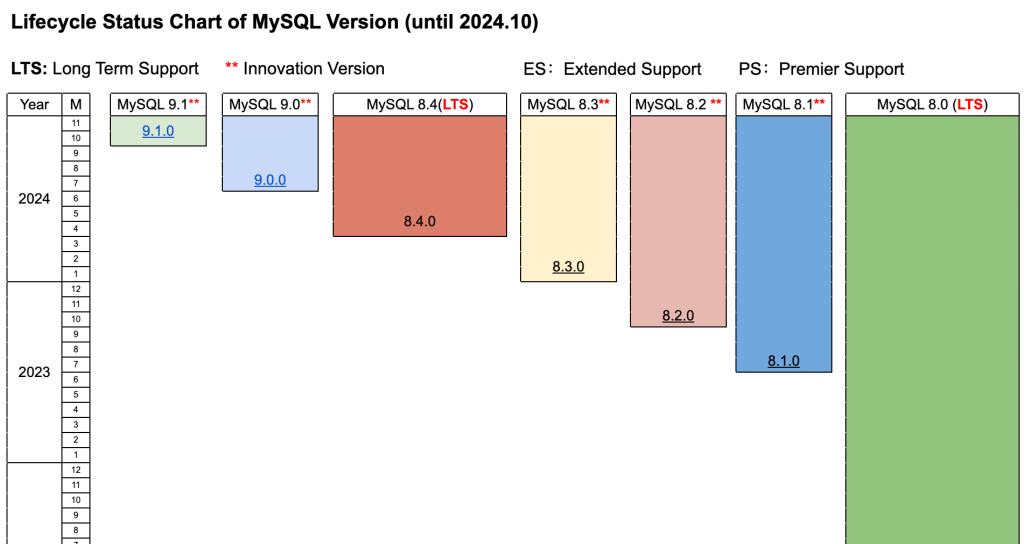
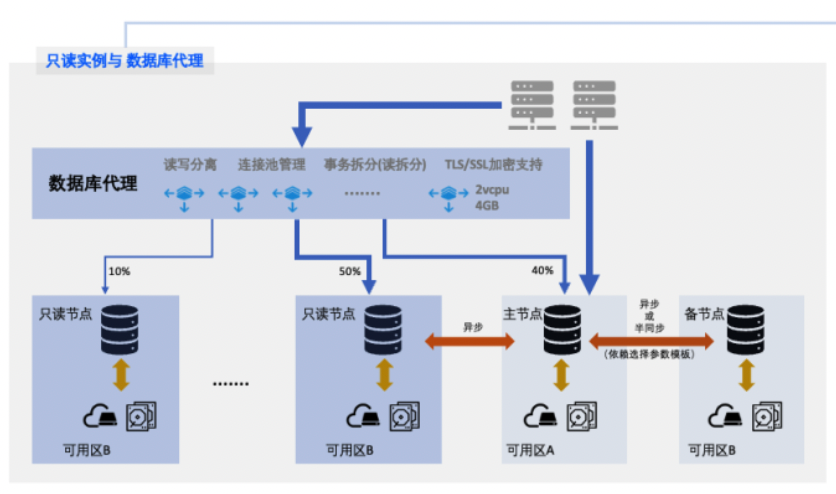
阿里云数据库 RDS 一直在快速的演进,在基础能力上,还有集群版、Serverless、ARM支持等
Post Lists
最新文章
云数据库RDS MySQL性能专题
- 云数据库 RDS MySQL 性能综述 | Performance Benchmark MySQL on Cloud
- 云数据库RDS MySQL性能测试与对比@2024年09月
- 阿里云RDS标准版(x86) vs 经济版(ARM)性能对比
- 华为云RDS通用型(x86) vs 鲲鹏(ARM)架构的性能对比
- AWS x86 vs Graviton(ARM)的RDS MySQL性能对比
- AWS x86 vs Graviton(ARM)的RDS MySQL性能对比 (二)
- 磁盘类型选择对阿里云RDS MySQL的性能影响
- TLS传输加密开启/关闭对于RDS MySQL性能的影响
- Oracle Cloud上MySQL的性能测试
- Oracle Cloud上的ECPU与OCPU规格的MySQL性能对比
- Oracle云第三、四代规格的MySQL性能差异
生也有涯